Dokumenter
Chatboten din kan umiddelbart få tilgang til og bruke dokumenter, HTML-sider og til og med YouTube-videoer for å tilpasse din unike kontekst. Perfekt for å legg...
2 min lesing
AI Chatbot
Knowledge Management
+3
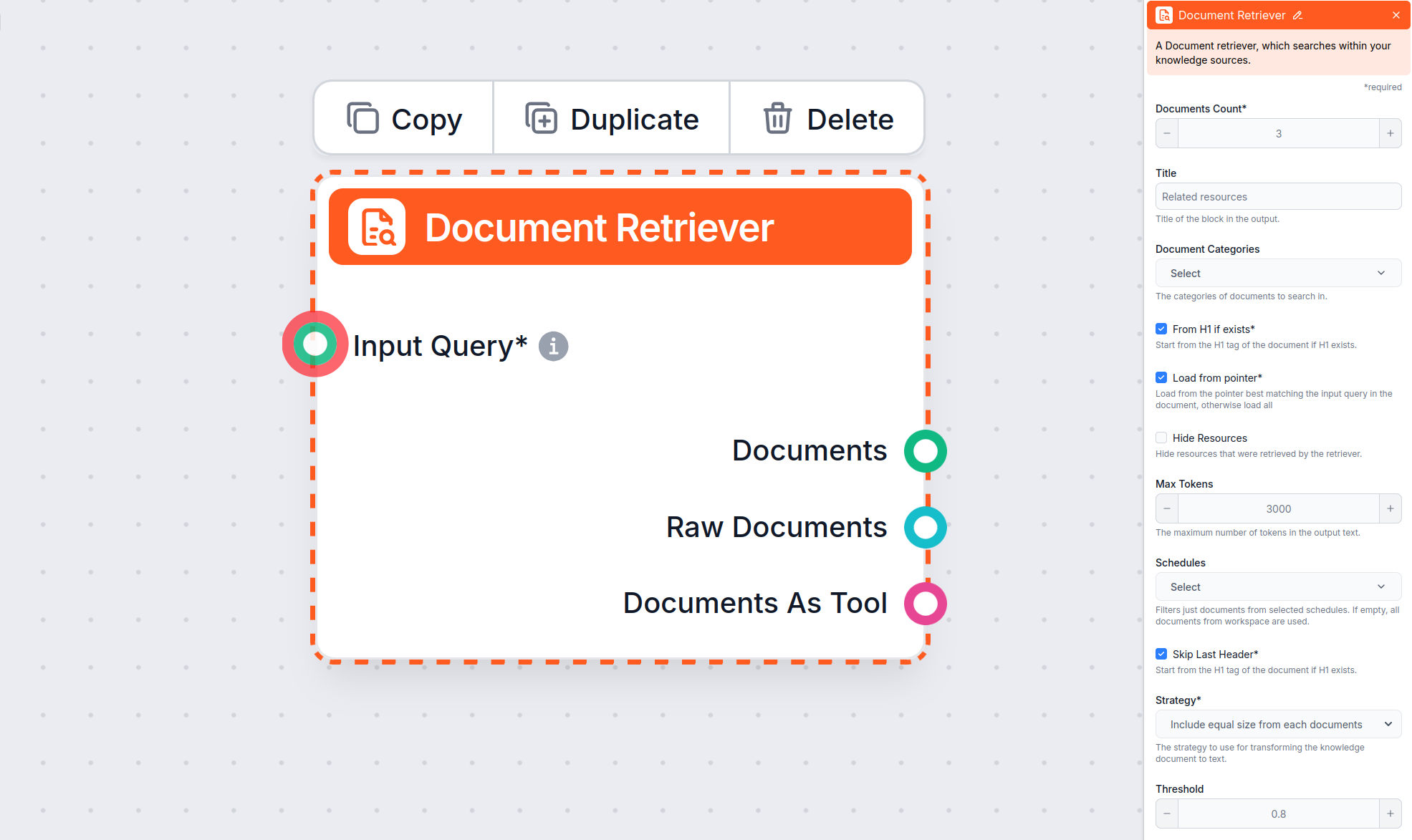
Lær hvordan du setter opp parameterne ‘Fra H1 hvis finnes’, ‘Last fra peker’ og ‘Hopp over siste overskrift’.
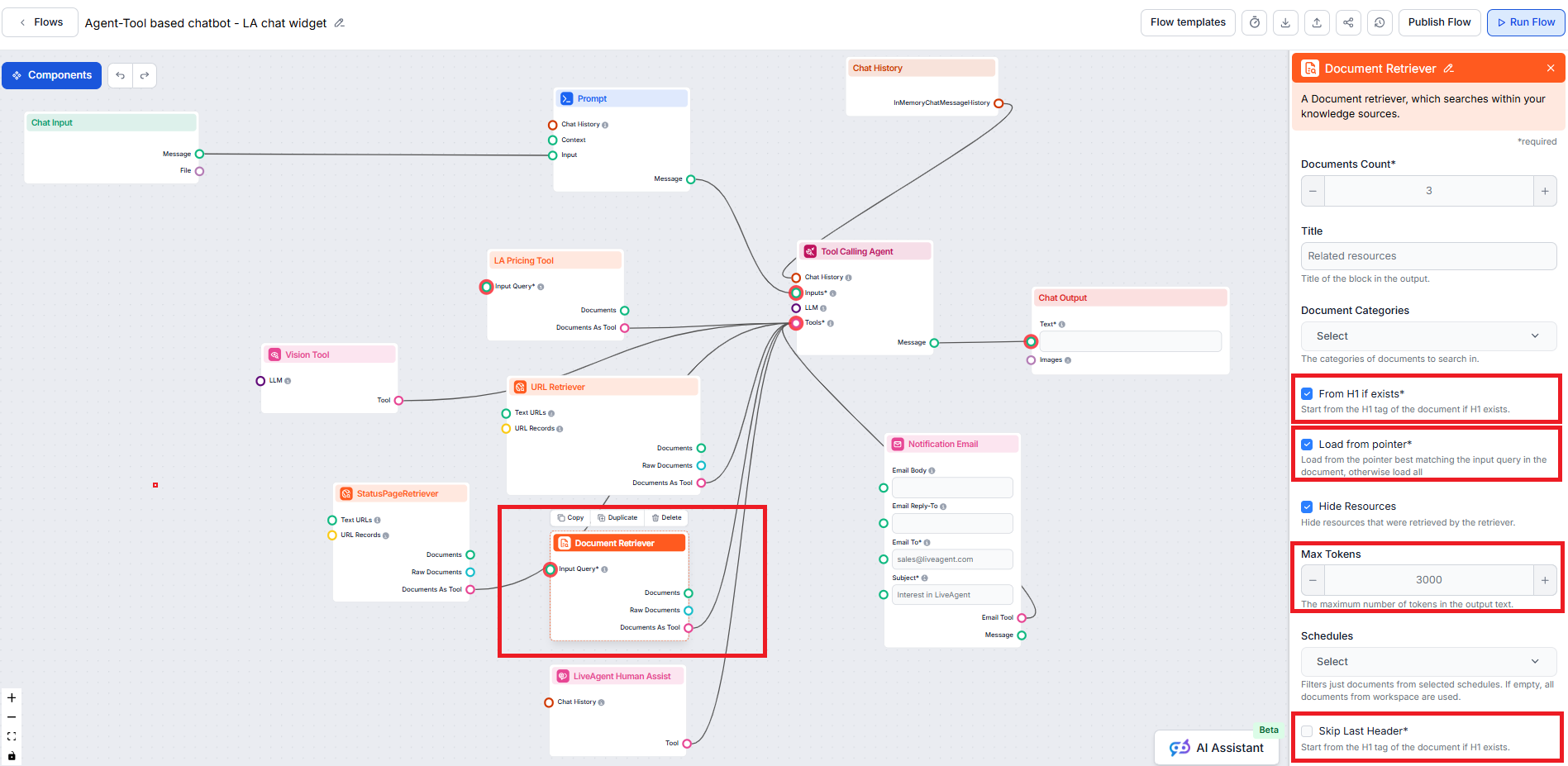
Document Retriever-komponenten lar chatboten hente kunnskap fra kilder du har spesifisert i Dokumenter og Tidsplaner. Rollen til denne komponenten er å kontrollere uthenting, og flere parametere påvirker hvordan komponenten henter informasjon fra disse dokumentene.
Alternativet Fra H1 hvis finnes instruerer retrieveren til å begynne å hente innhold fra H1-overskriften den finner (vanligvis artikkelens hovedtittel).
Hva skjer?
Eksempel på bruk:
Du ønsker kun å hente selve veiledningen, uten navigasjon eller sideoverskrifter som finnes på nettsiden din.
Merk:
Fra H1 hvis finnes er aktivert i Document Retriever-komponenten som standard.
Alternativet Last fra peker gir deg mer presisjon ved å la Document Retriever kun hente data fra en peker i den muligens lengre artikkelen.
Hva skjer?
Hva er en “peker”?
En peker er vanligvis en unik streng eller overskrift som finnes i dokumentet (for eksempel en H2, en bestemt frase eller seksjonstittel).
Eksempel på bruk:
Du ønsker å hoppe over introduksjonsseksjoner og hente informasjon for en spesifikk relevant del av en muligens lang artikkel eller et dokument (f.eks. fra “Trinn 4: Legg til en live chat-knapp” i en oppsettveiledning).
Alternativet Hopp over siste overskrift er nyttig for å ignorere den siste overskriften i dokumentet, som ofte gjentas eller brukes til navigasjon eller bunntekstformål.
Hva skjer?
Eksempel på bruk:
Du ønsker å unngå at Document Retriever laster inn en bunntekst-navigasjonsoverskrift (for eksempel “Andre artikler” på slutten av en hjelpeside), slik at bare hovedinnholdet blir behandlet.
Merk:
Hopp over siste overskrift kan være nyttig for dokumenter som automatisk genererer bunntekster eller repeterende navigasjonselementer. Har du ikke slike seksjoner, kan bruk av denne parameteren føre til at deler av artikkelen med gyldig informasjon ikke blir hentet ut. Det anbefales derfor å la dette alternativet være av frem til det foreligger en gyldig grunn til å aktivere det.
Parameteren Maks antall tokens lar deg styre det maksimale antallet tokens (ord og tegnsetting, slik AI-modellen teller) som Document Retriever vil hente fra teksten.
Hva skjer?
Standardverdi:
Standardverdien er vanligvis 3000 tokens, men du kan justere dette ved behov.
Eksempel på bruk:
Hvis du behandler lange dokumenter, kan en lavere verdi for Maks antall tokens bidra til å holde svarene korte. For best resultat bør du likevel vurdere å aktivere “Last fra peker”-parameteren. Da starter uthentingen på den mest relevante delen av dokumentet, i stedet for fra begynnelsen, slik at du får ut et fokusert og håndterbart tekstutdrag innenfor valgt token-grense. Denne kombinasjonen er spesielt nyttig når du ønsker korte, kontekstrelevante utdrag fra store kilder.
Merk:
Hvis du ser at informasjon blir kuttet, kan du øke verdien for Maks antall tokens. Ønsker du kortere, mer fokuserte utdata, reduser parameteren for Maks antall tokens.
Når Document Retriever finner flere relevante dokumenter, bestemmer parameteren Strategi hvordan de slås sammen til én tekst for chatboten din, med hensyn til “Maks antall tokens”.
To strategialternativer:
Inkluder lik størrelse fra hvert dokument:
Token-grensen deles jevnt. For eksempel, med tre dokumenter og en grense på 3 000 tokens, får hvert dokument opptil 1 000 tokens. Dette sikrer at alle kilder bidrar likt, noe som er nyttig hvis du ønsker et balansert svar som henter fra flere dokumenter.
Koble sammen dokumenter, fyll fra det første opp til token-grensen:
Dokumenter legges til etter relevans til grensen er nådd. Det mest relevante dokumentet fyller plassen først; hvis det er plass igjen, legges mindre relevante dokumenter til i rekkefølge. Hvis det første dokumentet er langt, kan det bruke hele grensen alene.
Hvordan velge?
Merk:
Disse strategiene påvirker kun hvordan teksten settes sammen fra de uthentede dokumentene før den sendes til neste steg (for eksempel AI-generering). De endrer ikke hvilke dokumenter som hentes—bare hvordan innholdet deres kombineres og kuttes for å passe innenfor innstillingen for Maks antall tokens.
Selv om denne artikkelen fokuserer på oppsett av parameterne ‘Fra H1 hvis finnes’, ‘Last fra peker’, ‘Hopp over siste overskrift’ og ‘Maks antall tokens’, tilbyr Document Retriever også flere andre parametere som hjelper med å styre hvordan dokumenter velges og hentes:
Denne innstillingen begrenser hvor mange dokumenter flyten skal hente, for å sikre relevante resultater og raske svar.
Denne valgfrie innstillingen lar deg begrense uthenting til én eller flere kategorier du har opprettet i Dokumenter-delen under Kunnskapskilder.
Dette lar deg inkludere eller skjule en egen seksjon, før selve chatbot-svaret, med en liste over ressurser som ble hentet av retrieveren. For integrasjon med LiveAgent må dette være valgt, da denne seksjonen ikke støttes og ikke vil vises riktig i LiveAgent chatbot-widgeten.
Lar deg begrense uthenting til én eller flere tidsplaner du har angitt for crawling eller oppdatering av innhold i Kunnskapskilder.
Styrer hvor tett de uthentede dokumentene må matche innspørringen, ved hjelp av en relevans-score (fra 0 til 1). For eksempel anbefales en terskel mellom 0,7–0,8 for svært relevante svar. Høyere terskel gir mer presise treff, mens lavere terskel kan inkludere mindre relevante dokumenter.
Eksempel:
Hvis du setter terskelverdien til 0,6 og har fire artikler med relevans-score på 0,8, 0,65, 0,5 og 0,9, vil kun de over 0,6 (altså 0,8, 0,65 og 0,9) brukes for uthenting.
Hvis svaret chatboten gir ikke inneholder informasjon du er sikker på at chatboten har tilgjengelig i dokumentene eller tidsplanene dine, kan du sjekke samtalehistorikken med “Verbose”-alternativet for å se detaljerte logger over om Document Retriever ble brukt og hvilke dokumenter som ble hentet. Juster eventuelt innstillinger og prompt basert på disse loggene.
Chatboten din kan umiddelbart få tilgang til og bruke dokumenter, HTML-sider og til og med YouTube-videoer for å tilpasse din unike kontekst. Perfekt for å legg...
En AI-drevet chatbot som gir presise svar på brukerens spørsmål, basert strengt på innholdet fra et gitt Google-dokument. Ideell for forskning, innholds-gjennom...

En detaljert guide for å importere kun bestemte seksjoner fra docs.cpanel.net til din FlowHunt-chatbot, slik at den blir ekspert på utvalgte cPanel-temaer uten ...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.