Fluxos
Os Fluxos são o cérebro por trás de tudo no FlowHunt. Aprenda a criá-los com um construtor visual sem código, desde a colocação do primeiro componente até a int...
2 min de leitura
AI
No-Code
+4

Automação de IA
O novo toolkit CLI open source da FlowHunt permite avaliação abrangente de fluxos com LLM como Juiz, fornecendo relatórios detalhados e avaliação automatizada de qualidade para workflows de IA.
Estamos entusiasmados em anunciar o lançamento do FlowHunt CLI Toolkit – nossa nova ferramenta de linha de comando open source projetada para revolucionar a forma como desenvolvedores avaliam e testam fluxos de IA. Este poderoso toolkit traz capacidades de avaliação de fluxos em nível empresarial para a comunidade open source, com relatórios avançados e nossa inovadora implementação do “LLM como Juiz”.
O FlowHunt CLI Toolkit representa um grande avanço nos testes e avaliações de workflows de IA. Disponível agora no GitHub , este toolkit open source oferece aos desenvolvedores ferramentas abrangentes para:
O toolkit reflete nosso compromisso com a transparência e o desenvolvimento colaborativo, tornando técnicas avançadas de avaliação de IA acessíveis a desenvolvedores do mundo todo.
Um dos recursos mais inovadores do nosso toolkit CLI é a implementação do “LLM como Juiz”. Essa abordagem utiliza inteligência artificial para avaliar a qualidade e a correção de respostas geradas por IA – essencialmente, colocando a IA para julgar o desempenho de outra IA com capacidades sofisticadas de raciocínio.
O que torna nossa implementação única é o fato de termos usado o próprio FlowHunt para criar o fluxo de avaliação. Essa abordagem meta demonstra o poder e a flexibilidade da nossa plataforma ao mesmo tempo que fornece um sistema de avaliação robusto. O fluxo LLM como Juiz consiste em vários componentes interligados:
1. Template de Prompt: Cria o prompt de avaliação com critérios específicos
2. Gerador de Saída Estruturada: Processa a avaliação usando um LLM
3. Parser de Dados: Formata a saída estruturada para relatórios
4. Saída de Chat: Apresenta os resultados finais da avaliação
No centro do nosso sistema LLM como Juiz está um prompt cuidadosamente elaborado que garante avaliações consistentes e confiáveis. Este é o template de prompt principal que usamos:
You will be given an ANSWER and REFERENCE couple.
Your task is to provide the following:
1. a 'total_rating' scoring: how close is the ANSWER to the REFERENCE
2. a binary label 'correctness' which can be either 'correct' or 'incorrect', which defines if the ANSWER is correct or not
3. and 'reasoning', which describes the reason behind your choice of scoring and correctness/incorrectness of ANSWER
An ANSWER is correct when it is the same as the REFERENCE in all facts and details, even if worded differently. the ANSWER is incorrect if it contradicts the REFERENCE, changes or omits details. its ok if the ANSWER has more details comparing to REFERENCE.
'total rating' is a scale of 1 to 4, where 1 means that the ANSWER is not the same as REFERENCE at all, and 4 means that the ANSWER is the same as the REFERENCE in all facts and details even if worded differently.
Here is the scale you should use to build your answer:
1: The ANSWER is contradicts the REFERENCE completely, adds additional claims, changes or omits details
2: The ANSWER points to the same topic but the details are omitted or changed completely comparing to REFERENCE
3: The ANSWER's references are not completely correct, but the details are somewhat close to the details mentioned in the REFERENCE. its ok, if there are added details in ANSWER comparing to REFERENCES.
4: The ANSWER is the same as the REFERENCE in all facts and details, even if worded differently. its ok, if there are added details in ANSWER comparing to REFERENCES. if there are sources available in REFERENCE, its exactly the same as ANSWER and is for sure mentioned in ANSWER
REFERENCE
===
{target_response}
===
ANSWER
===
{actual_response}
===
Esse prompt garante que nosso juiz LLM forneça:
Comece seu teste gratuito hoje e veja resultados em dias.
Nosso fluxo LLM como Juiz demonstra um design sofisticado de workflow de IA usando o construtor visual de fluxos da FlowHunt. Veja como os componentes trabalham juntos:
O fluxo começa com um componente de Chat Input que recebe a solicitação de avaliação contendo tanto a resposta real quanto a resposta de referência.
O componente Template de Prompt constrói dinamicamente o prompt de avaliação:
{target_response}{actual_response}O Gerador de Saída Estruturada processa o prompt usando um LLM selecionado e gera uma saída estruturada contendo:
total_rating: Pontuação numérica de 1 a 4correctness: Classificação binária de correto/incorretoreasoning: Explicação detalhada da avaliaçãoO componente Parse Data formata a saída estruturada para um formato legível, e o componente Chat Output apresenta os resultados finais da avaliação.
O sistema LLM como Juiz oferece diversas capacidades avançadas que o tornam especialmente eficaz para a avaliação de fluxos de IA:
Diferentemente de uma simples correspondência de strings, nosso juiz LLM entende:
A escala de classificação de 4 pontos permite avaliações granulares:
Cada avaliação inclui raciocínio detalhado, tornando possível:
Receba gratuitamente as últimas dicas, tendências e ofertas.
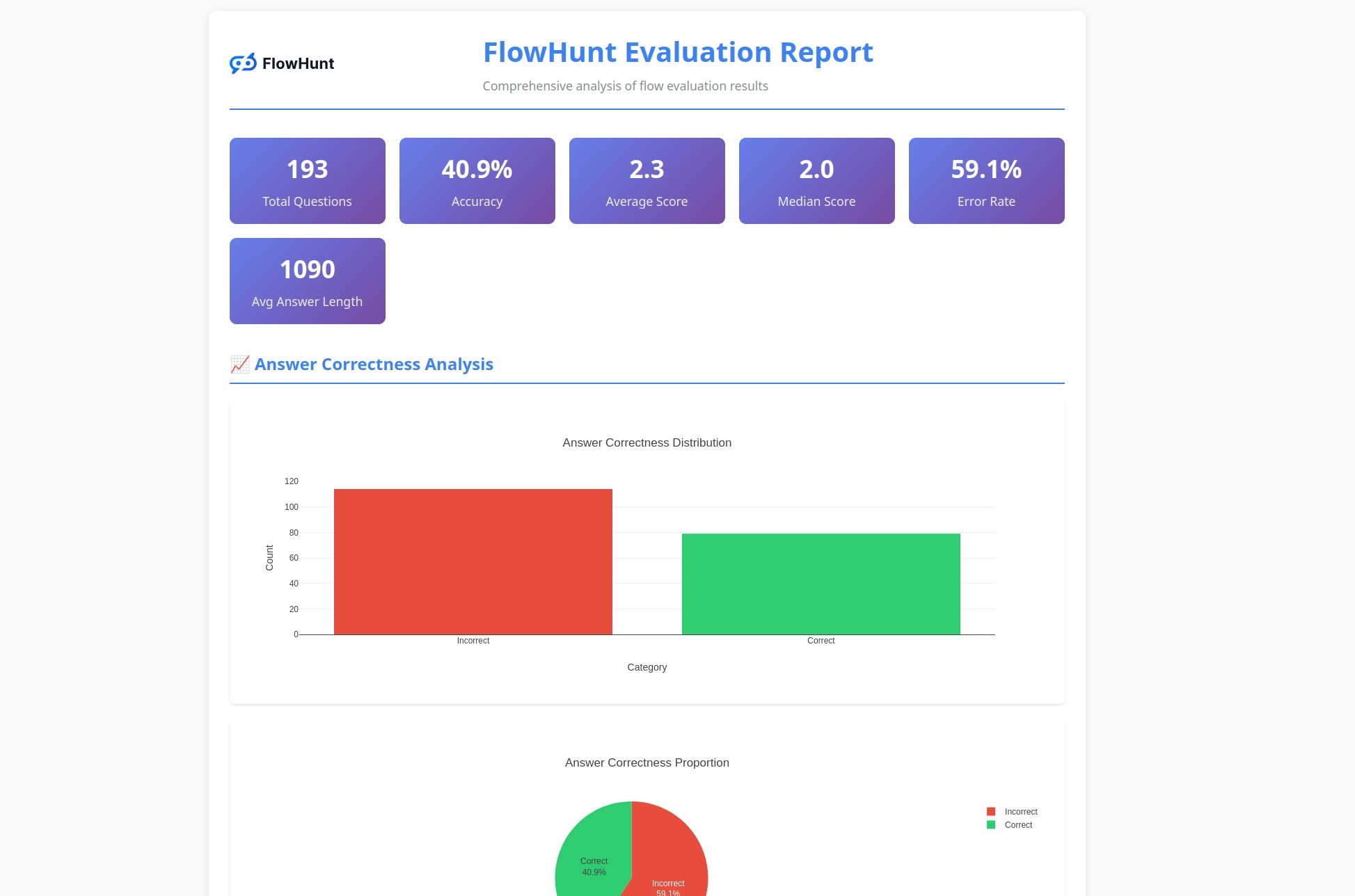
O toolkit CLI gera relatórios detalhados que fornecem insights acionáveis sobre o desempenho dos fluxos:
Pronto para começar a avaliar seus fluxos de IA com ferramentas profissionais? Veja como começar:
Instalação em Uma Linha (Recomendado) para macOS e Linux:
curl -sSL https://raw.githubusercontent.com/yasha-dev1/flowhunt-toolkit/main/install.sh | bash
Isso irá automaticamente:
flowhunt ao seu PATHInstalação Manual:
# Clone o repositório
git clone https://github.com/yasha-dev1/flowhunt-toolkit.git
cd flowhunt-toolkit
# Instale com pip
pip install -e .
Verifique a Instalação:
flowhunt --help
flowhunt --version
1. Autenticação
Primeiro, autentique-se com sua API da FlowHunt:
flowhunt auth
2. Liste Seus Fluxos
flowhunt flows list
3. Avalie um Fluxo Crie um arquivo CSV com seus dados de teste:
flow_input,expected_output
"O que é 2+2?","4"
"Qual é a capital da França?","Paris"
Execute a avaliação com LLM como Juiz:
flowhunt evaluate your-flow-id path/to/test-data.csv --judge-flow-id your-judge-flow-id
4. Execução em Lote de Fluxos
flowhunt batch-run your-flow-id input.csv --output-dir results/
O sistema de avaliação oferece análise abrangente:
flowhunt evaluate FLOW_ID TEST_DATA.csv \
--judge-flow-id JUDGE_FLOW_ID \
--output-dir eval_results/ \
--batch-size 10 \
--verbose
Recursos incluem:
O toolkit CLI integra-se perfeitamente com a plataforma FlowHunt, permitindo que você:
O lançamento do nosso toolkit CLI representa mais do que uma nova ferramenta – é uma visão para o futuro do desenvolvimento de IA onde:
Qualidade é Mensurável: Técnicas avançadas de avaliação tornam o desempenho da IA quantificável e comparável.
Testes são Automatizados: Frameworks completos de testes reduzem o esforço manual e aumentam a confiabilidade.
Transparência é o Padrão: Raciocínio detalhado e relatórios tornam o comportamento da IA compreensível e depurável.
A Comunidade Impulsiona a Inovação: Ferramentas open source possibilitam aprimoramento colaborativo e compartilhamento de conhecimento.
Ao tornar o FlowHunt CLI Toolkit open source, estamos demonstrando nosso compromisso com:
O FlowHunt CLI Toolkit com LLM como Juiz representa um grande avanço nas capacidades de avaliação de fluxos de IA. Ao combinar lógica sofisticada de avaliação com relatórios abrangentes e acessibilidade open source, estamos capacitando desenvolvedores a construir sistemas de IA melhores e mais confiáveis.
A abordagem meta de usar o FlowHunt para avaliar fluxos do próprio FlowHunt demonstra a maturidade e flexibilidade da nossa plataforma, ao mesmo tempo em que oferece uma ferramenta poderosa para a comunidade de desenvolvimento de IA em geral.
Seja você desenvolvendo chatbots simples ou sistemas multiagentes complexos, o FlowHunt CLI Toolkit fornece a infraestrutura de avaliação de que você precisa para garantir qualidade, confiabilidade e melhoria contínua.
Pronto para elevar sua avaliação de fluxos de IA? Visite nosso repositório no GitHub para começar a usar o FlowHunt CLI Toolkit hoje mesmo e experimente por si só o poder do LLM como Juiz.
O futuro do desenvolvimento de IA chegou – e ele é open source.
O FlowHunt CLI Toolkit é uma ferramenta de linha de comando open source para avaliar fluxos de IA com capacidades abrangentes de relatórios. Inclui recursos como avaliação LLM como Juiz, análise de resultados corretos/incorretos e métricas de desempenho detalhadas.
O LLM como Juiz utiliza um fluxo de IA sofisticado construído dentro do FlowHunt para avaliar outros fluxos. Ele compara respostas reais com respostas de referência, fornecendo avaliações, classificações de correção e raciocínio detalhado para cada avaliação.
O FlowHunt CLI Toolkit é open source e está disponível no GitHub em https://github.com/yasha-dev1/flowhunt-toolkit. Você pode clonar, contribuir e usá-lo livremente para suas necessidades de avaliação de fluxos de IA.
O toolkit gera relatórios abrangentes incluindo divisões de resultados corretos/incorretos, avaliações LLM como Juiz com notas e justificativas, métricas de desempenho e análise detalhada do comportamento dos fluxos em diferentes casos de teste.
Sim! O fluxo LLM como Juiz é construído usando a plataforma da FlowHunt e pode ser adaptado para diversos cenários de avaliação. Você pode modificar o template de prompt e os critérios de avaliação para atender a seus casos de uso específicos.
Yasha é um talentoso desenvolvedor de software especializado em Python, Java e aprendizado de máquina. Yasha escreve artigos técnicos sobre IA, engenharia de prompts e desenvolvimento de chatbots.

Construa e avalie workflows sofisticados de IA com a plataforma da FlowHunt. Comece hoje mesmo a criar fluxos que podem julgar outros fluxos.
Os Fluxos são o cérebro por trás de tudo no FlowHunt. Aprenda a criá-los com um construtor visual sem código, desde a colocação do primeiro componente até a int...

O FlowHunt apresenta grandes atualizações, incluindo servidores MCP personalizados, login SSO para clientes corporativos, integração com Odoo, novos modelos de ...
O editor de Fluxos permite que você arraste e solte componentes que representam diversas habilidades de IA. Nenhuma habilidade de programação é necessária, gara...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.