Como Criar Páginas de Base de Conhecimento Personalizadas no Hugo a partir de Tickets do LiveAgent
Aprenda como automatizar a criação de artigos de base de conhecimento no Hugo diretamente a partir de tickets de suporte ao cliente, utilizando agentes de IA e integração com o GitHub.
Automation
Knowledge Base
Hugo
GitHub
AI Agents
Customer Support
Equipes de suporte ao cliente geram insights valiosos todos os dias através de suas interações com os clientes. Essas perguntas, dúvidas e soluções representam uma mina de ouro de informações que poderiam beneficiar toda a sua base de usuários se fossem devidamente documentadas. No entanto, converter manualmente tickets de suporte em artigos bem elaborados para a base de conhecimento é uma tarefa demorada, repetitiva e frequentemente deixada de lado diante das demandas imediatas de suporte. E se você pudesse automatizar todo esse processo, transformando dúvidas brutas de clientes em páginas de base de conhecimento profissionalmente formatadas e otimizadas para SEO, que aparecem diretamente no seu site? Isso é exatamente o que os fluxos de automação modernos tornam possível. Ao conectar seu sistema de tickets LiveAgent com o gerador de site estático Hugo e o controle de versão do GitHub, você pode criar um pipeline integrado que transforma perguntas de clientes em conteúdo pesquisável e descobrível automaticamente. Neste guia completo, vamos explorar como construir esse sistema de automação poderoso, a arquitetura técnica por trás dele e os passos práticos para implementá-lo em sua própria organização.
Entendendo a Automação da Base de Conhecimento
Uma base de conhecimento é um repositório centralizado de informações, projetado para ajudar usuários a encontrar respostas para perguntas comuns sem precisar solicitar suporte diretamente. Bases de conhecimento tradicionais são construídas manualmente—equipes de suporte escrevem artigos, formatam, otimizam para motores de busca e publicam através de um sistema de gerenciamento de conteúdo. Esse processo demanda muito trabalho e cria um gargalo significativo, especialmente para empresas em crescimento que recebem centenas de solicitações de suporte diariamente. A automação da base de conhecimento muda esse paradigma ao usar inteligência artificial para extrair informações relevantes dos tickets de suporte, estruturá-las de acordo com modelos predefinidos e publicá-las diretamente em seu site. O sistema de automação atua como um intermediário inteligente entre sua equipe de suporte e o site, identificando quais tickets contêm conhecimento generalizável que beneficiaria outros usuários e, em seguida, transformando essa conversa bruta em documentação profissional e refinada. Essa abordagem não só economiza tempo, mas também garante consistência na formatação, estrutura e otimização para SEO em todos os artigos da base de conhecimento. O sistema pode ser configurado para entender o contexto específico do seu negócio, evitar a criação de conteúdo duplicado e manter uma base de conhecimento coerente, que cresce organicamente conforme sua equipe lida com mais solicitações.
Pronto para expandir seu negócio?
Comece seu teste gratuito hoje e veja resultados em dias.
Por Que a Automação da Base de Conhecimento é Importante para Seu Negócio
O argumento de negócios para a automação da base de conhecimento é atraente e multifacetado. Primeiro, ela reduz drasticamente o volume de suporte ao permitir que clientes encontrem respostas de forma independente. Estudos mostram consistentemente que clientes preferem opções de autoatendimento quando estas estão disponíveis e são eficazes, e uma base de conhecimento bem mantida pode reduzir os tickets de suporte em 20-30%. Segundo, ela melhora a satisfação do cliente ao fornecer respostas instantâneas para questões comuns, sem que o cliente precise aguardar um retorno da equipe. Terceiro, traz benefícios significativos de SEO—artigos da base de conhecimento são indexados por mecanismos de busca e podem atrair tráfego orgânico para seu site, aumentando sua visibilidade e atraindo novos clientes que descobrem seu conteúdo via pesquisa. Quarto, captura o conhecimento institucional que poderia ser perdido quando membros da equipe deixam a organização. Cada interação de suporte contém contexto e soluções valiosas que, quando documentadas, passam a fazer parte do repositório permanente de conhecimento da empresa. Quinto, possibilita que sua equipe de suporte foque em problemas complexos e de alto valor, ao invés de responder repetidamente às mesmas perguntas. Ao automatizar a criação de conteúdo da base de conhecimento a partir dos tickets de suporte, você está essencialmente criando um multiplicador de força para sua operação. O tempo gasto pela equipe respondendo dúvidas se transforma em conhecimento documentado que servirá milhares de clientes no futuro. Por fim, oferece dados valiosos sobre o que seus clientes têm dificuldade, podendo direcionar o desenvolvimento de produto, mensagens de marketing e iniciativas de educação do cliente.
A Arquitetura da Geração Automatizada da Base de Conhecimento
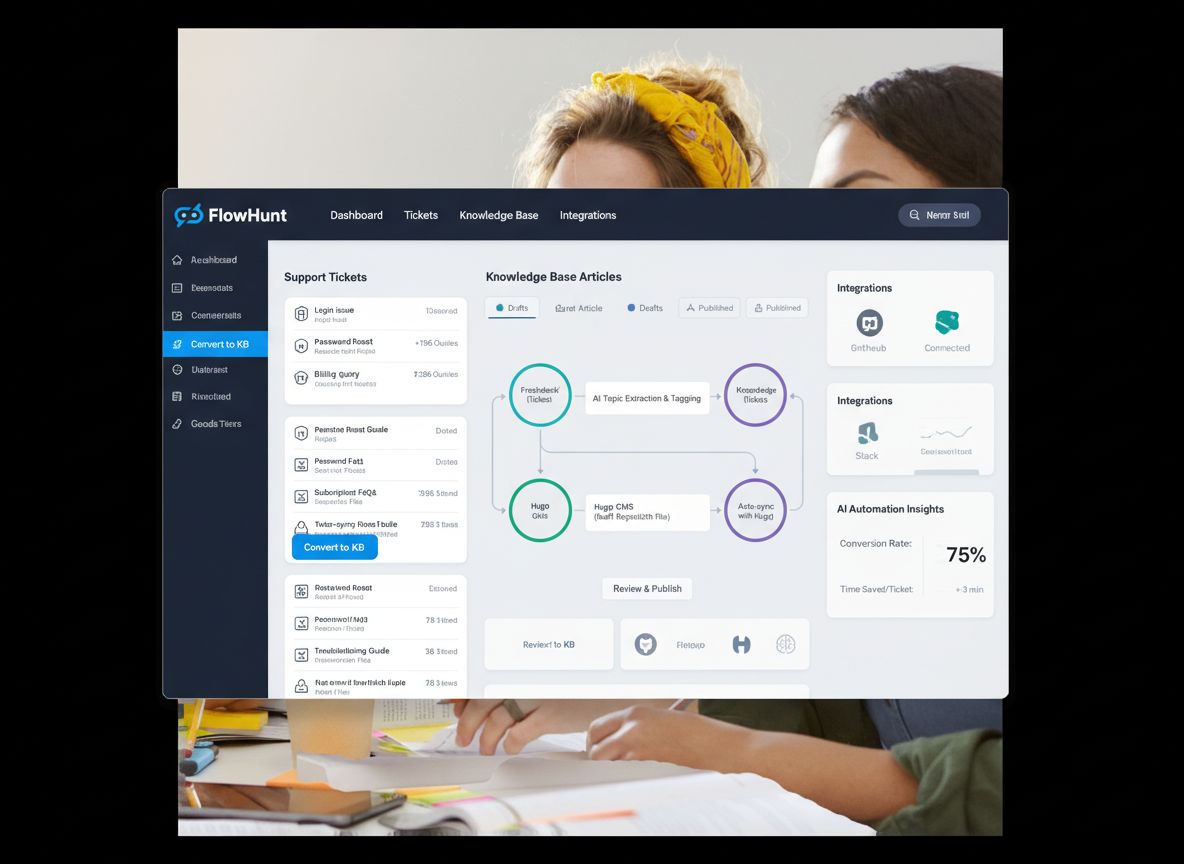
Construir um sistema automatizado de base de conhecimento exige a integração de diversas ferramentas e plataformas em um fluxo de trabalho coeso. O sistema geralmente é composto por quatro componentes principais: um sistema de tickets (LiveAgent), um agente de IA que processa os tickets, um sistema de controle de versão (GitHub) e um gerador de site estático (Hugo). O LiveAgent funciona como fonte principal das solicitações dos clientes, armazenando todas as conversas de suporte com metadados como tags, categorias e data/hora. O agente de IA é o orquestrador de todo o processo—ele recebe o ID do ticket, recupera o conteúdo completo e o histórico da conversa, analisa para determinar se é adequado para publicação na base de conhecimento, verifica o conhecimento existente para evitar duplicidades, gera conteúdo otimizado para SEO no formato correto e gerencia o fluxo de trabalho no GitHub. O GitHub atua como camada de gerenciamento de conteúdo e controle de versão, permitindo revisão, aprovação e rastreamento de todas as alterações na base de conhecimento. O Hugo, gerador de site estático, transforma os arquivos markdown armazenados no GitHub em um site rápido, seguro e otimizado para SEO. Essa arquitetura cria uma separação clara de responsabilidades: o LiveAgent cuida do suporte, o agente de IA da inteligência e tomada de decisão, o GitHub do versionamento e colaboração, e o Hugo da apresentação. O ponto forte desse sistema é que cada componente pode ser mantido e atualizado de forma independente, sem prejudicar os demais.
Junte-se à nossa newsletter
Receba gratuitamente as últimas dicas, tendências e ofertas.
Como a FlowHunt Possibilita a Automação da Base de Conhecimento
A FlowHunt fornece a camada de orquestração que conecta todos esses sistemas em um fluxo de trabalho integrado. Ao invés de exigir desenvolvimento personalizado ou integrações complexas, a FlowHunt permite desenhar visualmente o fluxo de automação, conectando LiveAgent, GitHub e Hugo em uma interface simples e intuitiva. A plataforma gerencia autenticação, tratamento de erros, lógica de retry e toda a complexidade técnica que normalmente demandaria esforço significativo de engenharia. Com a FlowHunt, você pode criar fluxos de automação sofisticados sem escrever código, tornando a automação da base de conhecimento acessível para equipes que não possuem desenvolvedores dedicados. A plataforma também oferece gerenciamento de memória e contexto, permitindo que a automação aprenda com execuções anteriores e tome decisões inteligentes sobre quando criar novos artigos ou atualizar existentes. A integração da FlowHunt com o GitHub permite a criação automática de pull requests, possibilitando que sua equipe revise o conteúdo gerado antes de ir ao ar. Essa abordagem de “humano no loop” garante qualidade, mantendo os ganhos de eficiência da automação.
O Fluxo Completo: Processo Passo a Passo
O fluxo de geração automatizada de base de conhecimento segue uma sequência cuidadosamente desenhada, em que cada etapa constrói a anterior para criar um artigo completo e pronto para produção. Compreender esse processo é essencial para implementá-lo de forma eficaz em sua organização.
Primeiro Passo: Recuperação e Validação do Ticket
O fluxo começa quando você fornece um ID de ticket do seu sistema LiveAgent. O agente de IA imediatamente recupera o conteúdo completo do ticket, incluindo assunto, corpo, todas as tags e o histórico integral da conversa entre cliente e suporte. Essa recuperação abrangente é crucial para garantir que a IA tenha todo o contexto necessário para gerar um conteúdo preciso e relevante. O agente também valida se o ticket possui informações suficientes e se é apropriado para publicação na base de conhecimento. Por exemplo, se sua organização recebe muitos pedidos de agendamento de demonstração, você pode configurar o sistema para pular automaticamente esses tickets, já que não representam conhecimento generalizável para outros usuários. Essa filtragem evita que sua base fique saturada com conteúdo administrativo ou transacional, sem valor para a base de usuários.
Segundo Passo: Detecção de Duplicidade Usando Memória
Antes de gerar novo conteúdo, o sistema verifica sua memória para saber se já existe artigo semelhante na base de conhecimento. Esse sistema de memória é uma das funcionalidades mais importantes da automação, pois impede a criação de artigos duplicados ou quase duplicados, que poderiam confundir usuários e prejudicar seu SEO. O agente de IA faz uma busca entre tickets e artigos já gerados para encontrar tópicos semelhantes. Se encontrar uma correspondência, ele pode atualizar o artigo existente com novas informações ou simplesmente pular a criação, conforme sua configuração. Caso não exista tópico semelhante, o agente adiciona o ticket à memória, criando um registro que será consultado em futuros tickets. Essa abordagem baseada em memória faz com que o sistema fique mais inteligente ao longo do tempo—conforme mais tickets são processados, o sistema constrói um mapa abrangente do seu conhecimento e toma decisões cada vez mais assertivas sobre criação e atualização de conteúdo.
Terceiro Passo: Análise da Estrutura da Base de Conhecimento
O sistema então analisa seu repositório de base de conhecimento existente para entender como o conteúdo é estruturado, formatado e organizado. Essa etapa é fundamental para garantir a consistência entre todos os artigos. O agente de IA analisa arquivos markdown existentes, formatos de frontmatter, estruturas de títulos e padrões de conteúdo para compreender as convenções da sua base. Ele verifica como os artigos são categorizados, quais metadados estão incluídos, como imagens são referenciadas e quais elementos de SEO estão presentes. Ao analisar o conteúdo já publicado, o sistema aprende seus requisitos específicos de estilo e estrutura, garantindo que os novos artigos se integrem perfeitamente à base já existente, sem parecer conteúdo obviamente automatizado.
Quarto Passo: Gerenciamento de Branches no GitHub
Para manter um controle de versão limpo e possibilitar fluxos de revisão adequados, o sistema cria ou utiliza um branch existente no GitHub para a atualização da base de conhecimento. Ao invés de criar um novo branch para cada ticket, o sistema gerencia inteligentemente os branches para manter o repositório organizado. Se já existir um branch para atualizações da base, o sistema o utiliza e adiciona o novo arquivo. Essa abordagem evita a proliferação de branches, mantendo a possibilidade de agrupar várias atualizações em um único pull request para revisão. O nome do branch costuma ser descritivo, como “knowledge-base-updates” ou “kb-automation”, facilitando o entendimento do propósito por parte da equipe.
Quinto Passo: Geração e Formatação do Conteúdo
Com todo o contexto reunido, o agente de IA gera o artigo da base de conhecimento. O conteúdo gerado inclui uma seção de frontmatter devidamente formatada, com metadados como título, descrição, palavras-chave, tags, categorias, data de publicação e elementos de chamada para ação. O corpo do artigo segue um formato estruturado, voltado tanto para a leitura do usuário quanto para a otimização em motores de busca. Geralmente, isso inclui um título principal, várias seções H2 com perguntas (como “O que é isso?”, “Por que fazer?”, e “Como fazer?”) e respostas detalhadas em parágrafos e listas. Essa estrutura é otimizada para snippets em destaque e outros recursos de busca que favorecem conteúdos claros e no formato pergunta-resposta. O conteúdo é escrito em markdown, formato padrão do Hugo e da maioria dos geradores de sites estáticos, garantindo compatibilidade e fácil edição.
Sexto Passo: Criação do Arquivo e Commit
O sistema cria um novo arquivo markdown na pasta da base de conhecimento, com um nome de arquivo apropriado baseado no tema do artigo. O nome geralmente é “slugificado” (minúsculo, hífens no lugar de espaços), seguindo os padrões web. O arquivo inclui o frontmatter completo e o conteúdo do corpo gerado no passo anterior. Após a criação do arquivo, o sistema faz o commit das alterações no branch do GitHub, com uma mensagem descritiva que referencia o ID do ticket original. Essa mensagem cria um registro permanente, ligando o artigo da base ao ticket de origem, permitindo rastreabilidade e contexto para consultas futuras.
Sétimo Passo: Criação e Revisão do Pull Request
Por fim, o sistema cria um pull request do branch da base de conhecimento para o branch principal. Esse pull request inclui uma descrição das alterações, o ID do ticket que motivou a criação e qualquer contexto relevante. O pull request serve como um ponto de checagem, onde sua equipe pode revisar o conteúdo gerado, fazer ajustes, verificar se o artigo atende aos padrões de qualidade e garantir alinhamento com a estratégia da base. Essa revisão humana é fundamental—embora o conteúdo gerado por IA seja geralmente de alta qualidade, a aprovação humana garante precisão, consistência da marca e adequação. Após a aprovação da equipe, o pull request pode ser mesclado ao branch principal, acionando o Hugo para reconstruir o site e publicar o novo artigo.
Implementação Prática: Encontrando e Usando IDs de Ticket
Para usar esse fluxo de automação, é preciso identificar o ID correto do ticket no LiveAgent. O LiveAgent exibe os IDs dos tickets em dois locais convenientes. Primeiro, diretamente na interface do LiveAgent, você verá o rótulo “Ticket” com o ID em destaque. Basta copiar esse ID. Segundo, e muitas vezes mais prático, você pode encontrar o ID na URL da página do ticket. Ao abrir um ticket no LiveAgent, a URL conterá um parâmetro como “ID=12345” no final. Esse é exatamente o ID que você deve fornecer ao fluxo de automação. Assim que tiver o ID, basta inseri-lo no fluxo da FlowHunt, e todo o processo começa automaticamente. O sistema recupera o ticket, analisa, verifica duplicidades, gera o artigo, cria o branch e o pull request no GitHub e notifica a equipe para revisão. Todo o processo normalmente é concluído em segundos ou minutos, dependendo da complexidade do ticket e do tamanho da base de conhecimento existente.
Potencialize Seu Fluxo de Trabalho com a FlowHunt
Veja como a FlowHunt automatiza a criação da sua base de conhecimento a partir de tickets de suporte — da análise do ticket e geração de conteúdo à integração com o GitHub e publicação no Hugo — tudo em um único fluxo integrado.
Após configurar o fluxo básico, há diversas opções avançadas para otimizar o sistema de acordo com suas necessidades. Você pode configurar o sistema para ignorar certos tipos de tickets com base em tags, categorias ou palavras-chave. Por exemplo, pode optar por pular todos os tickets com a tag “financeiro” ou “específico de conta”, já que geralmente não representam conhecimento generalizável. Também é possível definir limites mínimos de qualidade ou tamanho do artigo—se um ticket for muito curto ou não tiver detalhes suficientes, o sistema pode pulá-lo e aguardar por informações mais completas. O sistema de memória pode ser ajustado para usar diferentes algoritmos de correspondência, desde simples busca por palavras-chave até análise semântica sofisticada. Você também pode personalizar o frontmatter e a estrutura do conteúdo para adequar ao seu padrão, adicionando campos personalizados ou modificando o formato do artigo. Algumas organizações adicionam metadados como nível de dificuldade, público-alvo ou artigos relacionados. O sistema pode ser configurado para adicionar imagens automaticamente, gerando-as por IA ou buscando em sua biblioteca de ativos. Também é possível criar artigos em vários idiomas, se você atende um público internacional. Além disso, é viável configurar notificações e aprovações—por exemplo, exigir que membros específicos aprovem artigos de certas categorias antes da publicação.
Exemplo Prático: Erro de Integração com WordPress
Considere um exemplo real do fluxo em ação. Um cliente envia um ticket perguntando sobre um erro de integração com o WordPress. O ticket inclui mensagens de erro, capturas de tela e uma descrição detalhada das tentativas feitas. A equipe de suporte responde com etapas de resolução e, ao final, resolve o problema. Esse ticket é um candidato perfeito para automação da base de conhecimento. Quando o ID do ticket é inserido no fluxo, o sistema recupera toda a conversa, analisa e consulta sua memória. Como ainda não existe artigo sobre erros de integração com WordPress, o sistema adiciona esse tópico à memória e segue para a geração do artigo. O sistema examina sua base de conhecimento existente e identifica que você possui um formato específico para artigos técnicos, com seções de sintomas, causas, soluções e prevenção. O artigo gerado segue esse formato, criando um guia abrangente sobre erros de integração com WordPress, que ajudará futuros clientes a resolverem o problema de forma independente. O artigo é criado em um branch do GitHub, um pull request é gerado, sua equipe revisa, faz ajustes se necessário e aprova a publicação. Em poucos minutos, o artigo está no ar, indexado nos motores de busca e disponível para ajudar clientes. Na próxima vez que alguém buscar por “erro de integração WordPress” ou encontrar esse problema, encontrará o artigo na base de conhecimento e resolverá sozinho, sem acionar o suporte.
Medindo o Sucesso e o ROI
Para justificar o investimento na automação da base de conhecimento, é importante medir o impacto. Os principais indicadores incluem a redução no volume de tickets de suporte para dúvidas já cobertas por artigos da base, o aumento do tráfego orgânico dos mecanismos de busca, o tempo economizado pela equipe de suporte e a melhoria nos índices de satisfação do cliente. Você pode rastrear quantos clientes acessam artigos antes de buscar suporte, quantos tickets fazem referência à base de conhecimento e quantos clientes afirmam ter encontrado a resposta de que precisavam na base. Também é possível avaliar a qualidade dos artigos gerados por métricas de engajamento, como tempo na página, profundidade de rolagem e taxa de rejeição. Artigos valiosos terão métricas de engajamento mais altas. Além disso, monitore o número de artigos gerados, o tempo economizado em relação à criação manual e a economia de custos com a redução do volume de suporte. Na maioria das organizações, a automação da base de conhecimento se paga nos primeiros meses, graças à redução de custos e melhoria da satisfação do cliente.
Conclusão
Automatizar a criação de base de conhecimento a partir de tickets do LiveAgent representa uma grande oportunidade para melhorar a eficiência do suporte, potencializar o SEO do seu site e criar um recurso valioso que continuará ajudando seus clientes muito além da interação inicial de suporte. Ao conectar LiveAgent, GitHub, Hugo e automação com IA via FlowHunt, você constrói um sistema que transforma dúvidas brutas de clientes em artigos profissionais automaticamente. O fluxo é simples—basta fornecer o ID do ticket e o sistema cuida de tudo, desde a geração do conteúdo até a integração com o GitHub e a criação do pull request. O sistema de memória garante que você não crie conteúdo duplicado, enquanto a revisão humana mantém a qualidade e a consistência da marca. À medida que a base de conhecimento cresce, ela se torna um ativo cada vez mais valioso, reduzindo custos de suporte, aumentando a satisfação dos clientes e gerando tráfego orgânico para seu site. A implementação é acessível a equipes sem conhecimento técnico avançado, tornando essa poderosa automação disponível para organizações de todos os portes.
Perguntas frequentes
O que é um ticket do LiveAgent?
Um ticket do LiveAgent é uma solicitação ou dúvida de suporte ao cliente registrada no sistema de tickets do LiveAgent. Cada ticket contém um assunto, corpo, tags e todo o histórico da conversa, que pode ser usado para gerar conteúdo para a base de conhecimento.
Como encontro o ID do meu ticket no LiveAgent?
Você pode encontrar o ID do seu ticket de duas maneiras: (1) Procure pelo rótulo 'Ticket' com o ID exibido na interface do LiveAgent, ou (2) Verifique o final da URL, onde aparecerá 'ID=seu-id-do-ticket'. Copie esse ID para usar no fluxo de automação.
O fluxo pode ignorar certos tipos de tickets?
Sim, o fluxo pode ser configurado para ignorar tipos específicos de tickets. Por exemplo, é possível definir para pular solicitações de agendamento de demonstração, evitando criar páginas duplicadas na base de conhecimento para tópicos semelhantes.
O que acontece se já existir um artigo semelhante na base de conhecimento?
O fluxo utiliza memória para verificar se um tópico semelhante já foi processado antes. Se encontrar uma correspondência, ele atualizará o artigo existente, se necessário, ou irá pular a criação para evitar duplicidades.
Como o fluxo se integra ao GitHub?
O fluxo cria ou utiliza um branch existente no GitHub, gera um arquivo markdown com o frontmatter adequado, faz o commit das alterações e cria um pull request para revisão antes de mesclar no branch principal.
Arshia é Engenheira de Fluxos de Trabalho de IA na FlowHunt. Com formação em ciência da computação e paixão por IA, ela se especializa em criar fluxos de trabalho eficientes que integram ferramentas de IA em tarefas do dia a dia, aumentando a produtividade e a criatividade.
Arshia Kahani
Engenheira de Fluxos de Trabalho de IA
Automatize a Criação da Sua Base de Conhecimento
Transforme tickets de suporte ao cliente em artigos de base de conhecimento otimizados para SEO automaticamente com os fluxos de trabalho impulsionados por IA da FlowHunt.
Como automatizar respostas de tickets no LiveAgent com o FlowHunt
Aprenda como integrar fluxos de IA do FlowHunt ao LiveAgent para responder automaticamente aos tickets de clientes usando regras inteligentes de automação e int...
Integração Avançada FlowHunt–LiveAgent: Controle de Idioma, Filtro de Spam, Seleção de API e Melhores Práticas de Automação
Um guia técnico para dominar a integração avançada do FlowHunt com o LiveAgent, abordando direcionamento de idioma, supressão de markdown, filtragem de spam, ve...
Implemente um chatbot com IA em seu site que utiliza sua base de conhecimento interna para responder dúvidas dos clientes e, de forma transparente, encaminha qu...
4 min de leitura
Consentimento de Cookies Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.