Middleware Human-in-the-Loop em Python: Construindo Agentes de IA Seguros com Fluxos de Aprovação
Aprenda a implementar middleware human-in-the-loop em Python usando LangChain para adicionar capacidades de aprovação, edição e rejeição em agentes de IA antes da execução de ferramentas.
Construir agentes de IA capazes de executar ferramentas e tomar decisões de forma autônoma é poderoso, mas traz riscos inerentes. O que acontece quando um agente decide enviar um e-mail com informações incorretas, aprovar uma grande transação financeira ou modificar registros críticos no banco de dados? Sem salvaguardas adequadas, agentes autônomos podem causar grandes danos antes que alguém perceba o ocorrido. É aqui que o middleware human-in-the-loop se torna essencial. Neste guia completo, vamos explorar como implementar middleware human-in-the-loop em Python usando LangChain, permitindo que você desenvolva agentes de IA que pausam para aprovação humana antes de executar operações sensíveis. Você aprenderá a adicionar fluxos de aprovação, implementar capacidades de edição e tratar rejeições—tudo isso mantendo a eficiência e inteligência dos seus sistemas autônomos.
Compreendendo Loops de Agentes de IA e Execução de Ferramentas
Antes de mergulhar no middleware human-in-the-loop, é fundamental entender como agentes de IA funcionam em sua essência. Um agente de IA opera por meio de um loop contínuo que se repete até que o agente decida ter concluído sua tarefa. O loop principal do agente consiste em três componentes: um modelo de linguagem que raciocina sobre o que fazer em seguida, um conjunto de ferramentas que o agente pode acionar para agir e um sistema de gerenciamento de estado que rastreia o histórico da conversa e qualquer contexto relevante. O agente começa recebendo uma mensagem do usuário, então o modelo de linguagem analisa essa entrada junto às ferramentas disponíveis e decide se deve chamar uma ferramenta ou fornecer uma resposta final. Caso o modelo decida chamar uma ferramenta, essa ferramenta é executada e os resultados são adicionados ao histórico da conversa. Esse ciclo se repete—raciocínio do modelo, seleção de ferramenta, execução da ferramenta, integração do resultado—até que o modelo determine que não são necessárias mais chamadas de ferramentas e forneça uma resposta final ao usuário.
Esse padrão simples, porém poderoso, se tornou a base de centenas de frameworks de agentes de IA nos últimos anos. A elegância do loop do agente reside em sua flexibilidade: ao mudar as ferramentas disponíveis, você habilita o agente a desempenhar tarefas completamente diferentes. Um agente com ferramentas de e-mail pode gerenciar comunicações, um agente com ferramentas de banco de dados pode consultar e atualizar registros, e um agente com ferramentas financeiras pode processar transações. No entanto, essa flexibilidade também introduz riscos. Como o loop do agente opera de forma autônoma, não há um mecanismo embutido para pausar e perguntar a um humano se determinada ação realmente deve ser tomada. O modelo pode decidir enviar um e-mail, executar uma consulta no banco de dados ou aprovar uma transação financeira e, quando um humano percebe, a ação já foi realizada. É aqui que as limitações do loop básico de agente ficam evidentes em ambientes de produção.
Pronto para expandir seu negócio?
Comece seu teste gratuito hoje e veja resultados em dias.
Por Que a Supervisão Humana é Importante em Sistemas de IA em Produção
À medida que agentes de IA se tornam mais capazes e são implantados em ambientes de negócios reais, a necessidade de supervisão humana torna-se cada vez mais crítica. O impacto das ações dos agentes autônomos varia drasticamente conforme o contexto. Algumas chamadas de ferramenta são de baixo risco e podem ser executadas imediatamente sem revisão humana—por exemplo, ler um e-mail ou recuperar informações de um banco de dados. Outras são de alto risco e potencialmente irreversíveis, como enviar comunicações em nome de um usuário, transferir fundos, deletar registros ou assumir compromissos em nome da organização. Em sistemas de produção, o custo de um agente cometer um erro em uma operação de alto risco pode ser enorme. Um e-mail mal redigido enviado ao destinatário errado pode prejudicar relacionamentos comerciais. Um orçamento aprovado incorretamente pode gerar prejuízos financeiros. Uma exclusão de banco de dados feita por engano pode gerar perda de dados que leva horas ou dias para ser recuperada.
Além dos riscos operacionais imediatos, há também questões de conformidade e regulação. Muitos setores possuem requisitos rigorosos de que certos tipos de decisão devem envolver julgamento e aprovação humana. Instituições financeiras devem ter supervisão humana em transações acima de determinados valores. Sistemas de saúde precisam de revisão humana para determinadas decisões automatizadas. Escritórios de advocacia precisam garantir que comunicações sejam revisadas antes de serem enviadas em nome de clientes. Essas exigências regulatórias não são apenas burocracia—existem porque as consequências de decisões totalmente autônomas nessas áreas podem ser severas. Além disso, a supervisão humana fornece um mecanismo de feedback que ajuda a melhorar o agente ao longo do tempo. Quando um humano revisa uma ação proposta pelo agente e aprova ou sugere edições, esse feedback pode ser usado para refinar os prompts do agente, ajustar a lógica de seleção de ferramentas ou retreinar os modelos subjacentes. Isso cria um ciclo virtuoso, fazendo com que o agente se torne mais confiável e calibrado às necessidades e tolerância a risco da organização.
O Que é Middleware Human-in-the-Loop?
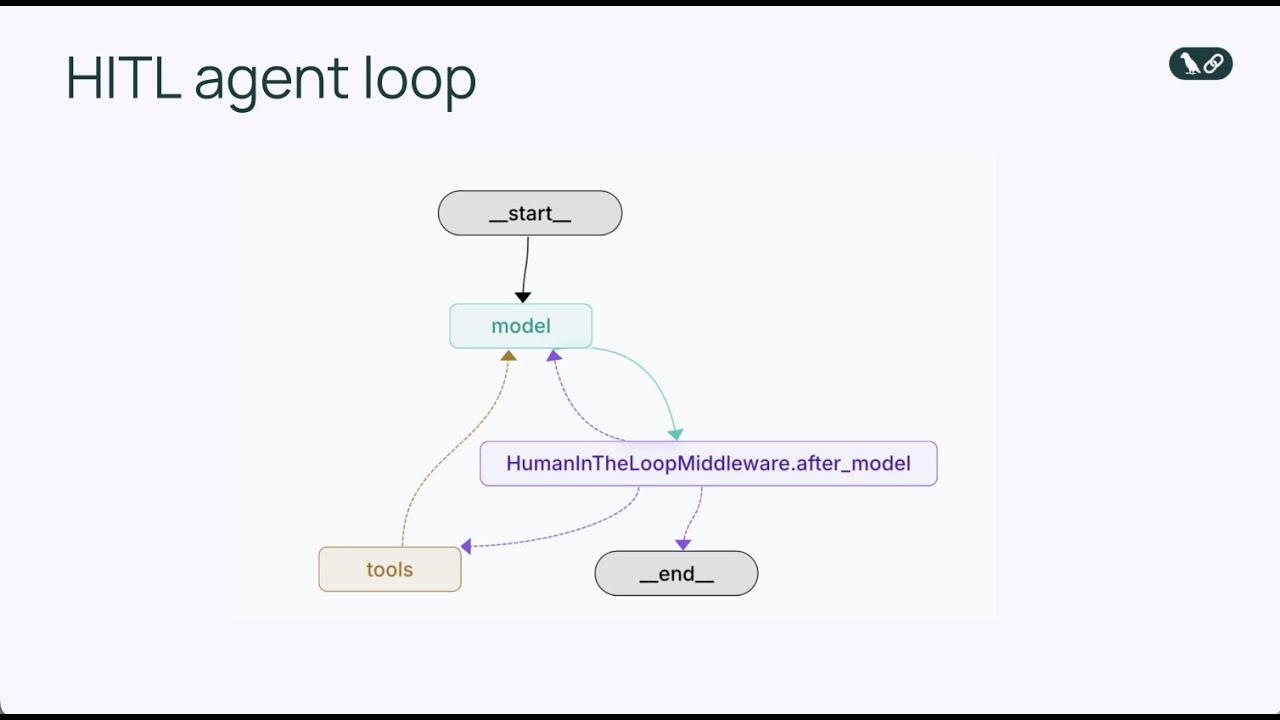
Middleware human-in-the-loop é um componente especializado que intercepta o loop do agente em um ponto crítico: logo antes da execução de uma ferramenta. Em vez de permitir que o agente execute imediatamente a chamada da ferramenta, o middleware pausa a execução e apresenta a ação proposta para revisão humana. O humano então tem várias opções de resposta. Pode aprovar a ação, permitindo que prossiga exatamente como o agente propôs. Pode editar a ação, modificando os parâmetros (como alterar o destinatário do e-mail ou o conteúdo da mensagem) antes de permitir a execução. Ou pode rejeitar completamente a ação, enviando feedback ao agente explicando por que a ação foi inadequada e pedindo para reconsiderar sua abordagem. Esse mecanismo de decisão tripla—aprovar, editar, rejeitar—oferece uma estrutura flexível que se adapta a diferentes tipos de necessidades de supervisão humana.
O middleware opera modificando o loop padrão do agente para incluir um ponto adicional de decisão. No loop básico, a sequência é: modelo chama ferramentas → ferramentas executam → resultados retornam ao modelo. Com middleware human-in-the-loop, a sequência se torna: modelo chama ferramentas → middleware intercepta → humano revisa → humano decide (aprovar/editar/rejeitar) → se aprovado ou editado, ferramenta executa → resultados retornam ao modelo. Essa inserção do ponto de decisão humana não quebra o loop do agente; ao contrário, o aprimora adicionando uma válvula de segurança. O middleware é configurável, ou seja, você pode especificar exatamente quais ferramentas devem disparar revisão humana e quais podem executar automaticamente. Talvez você queira interromper todas as ferramentas de envio de e-mail, mas permitir consultas de banco de dados somente leitura sem revisão. Esse controle granular garante que a supervisão humana seja aplicada onde realmente importa, sem criar gargalos desnecessários para operações de baixo risco.
Junte-se à nossa newsletter
Receba gratuitamente as últimas dicas, tendências e ofertas.
Os Três Tipos de Resposta: Aprovação, Edição e Rejeição
Quando o middleware human-in-the-loop intercepta a execução de uma ferramenta pelo agente, o revisor humano tem três maneiras principais de responder, cada uma servindo a um propósito específico no fluxo de aprovação.
Aprovação é o tipo de resposta mais simples. Quando um humano revisa uma chamada de ferramenta proposta e determina que ela é apropriada e deve prosseguir exatamente como o agente propôs, fornece uma decisão de aprovação. Isso sinaliza ao middleware que a ferramenta deve ser executada com os parâmetros exatos especificados pelo agente. No contexto de um assistente de e-mail, aprovação significa que o rascunho está adequado e deve ser enviado ao destinatário com o assunto e corpo definidos. Aprovação é o caminho de menor resistência—permite que a ação proposta pelo agente prossiga sem modificação. É apropriado quando o agente fez um bom trabalho e o revisor concorda com a proposta. Decisões de aprovação normalmente são rápidas, importante para não criar gargalos no fluxo.
Edição é uma resposta mais refinada, reconhecendo que a abordagem geral do agente está correta, mas alguns detalhes precisam ser ajustados antes da execução. Quando um humano fornece uma resposta de edição, não está rejeitando a decisão do agente de agir, mas refinando os detalhes de como a ação será realizada. Em um cenário de e-mail, editar pode significar trocar o endereço do destinatário, modificar o assunto para ficar mais profissional ou ajustar o corpo da mensagem para incluir contexto adicional ou remover linguagem inadequada. A característica-chave da resposta de edição é modificar os parâmetros da ferramenta mantendo a mesma chamada de ferramenta. O agente decidiu enviar um e-mail, o humano concorda que esse é o caminho, mas deseja ajustar o conteúdo ou o destinatário. Após as edições humanas, a ferramenta executa com os parâmetros modificados, e os resultados retornam ao agente. Isso é especialmente valioso pois permite que o agente proponha ações enquanto humanos ajustam os detalhes segundo sua experiência ou conhecimento do contexto organizacional.
Rejeição é o tipo de resposta mais impactante, pois não só impede a execução da ação proposta, mas também envia feedback ao agente explicando o motivo da inadequação. Ao rejeitar uma chamada de ferramenta, o humano indica que a ação não deve ser tomada e fornece orientação de como o agente deve reconsiderar sua abordagem. No exemplo do e-mail, a rejeição pode ocorrer se o agente propuser aprovar um grande pedido de orçamento sem detalhes suficientes. O humano rejeita e envia uma mensagem explicando que é necessário mais detalhamento antes da aprovação. Essa mensagem de rejeição passa a fazer parte do contexto do agente, que pode raciocinar sobre o feedback e propor uma nova abordagem. O agente pode então sugerir outro e-mail, solicitando mais informações sobre a proposta de orçamento antes de aprovar. Respostas de rejeição são cruciais para impedir que o agente proponha repetidamente a mesma ação inadequada. Ao fornecer feedback claro sobre o motivo da rejeição, você ajuda o agente a aprender e melhorar sua tomada de decisão.
Implementando Middleware Human-in-the-Loop: Um Exemplo Prático
Vamos passar por uma implementação concreta de middleware human-in-the-loop usando LangChain e Python. O exemplo será um assistente de e-mail—um cenário prático que demonstra o valor da supervisão humana de maneira fácil de entender. O assistente poderá enviar e-mails em nome do usuário, e adicionaremos middleware human-in-the-loop para garantir que todos os envios sejam revisados antes da execução.
Primeiro, precisamos definir a ferramenta de e-mail que o agente usará. Essa ferramenta recebe três parâmetros: destinatário, assunto e corpo do e-mail. É simples—representa a ação de enviar um e-mail. Em uma implementação real, poderia integrar-se com Gmail ou Outlook, mas para fins didáticos, manteremos simples. Veja a estrutura básica:
defsend_email(recipient: str, subject: str, body: str) -> str:
"""Enviar um e-mail para o destinatário especificado."""returnf"Email enviado para {recipient} com assunto '{subject}'"
Em seguida, criamos um agente que usa essa ferramenta. Utilizaremos o GPT-4 como modelo de linguagem e um prompt de sistema dizendo que ele é um assistente de e-mail prestativo. O agente é inicializado com a ferramenta de e-mail e está pronto para responder às solicitações do usuário:
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o")
tools = [send_email]
agent = create_agent(
model=model,
tools=tools,
system_prompt="Você é um assistente de e-mail prestativo para Sydney. Você pode enviar e-mails em nome do usuário.")
Neste ponto, temos um agente básico que pode enviar e-mails. Porém, não há supervisão humana—o agente pode enviar e-mails sem qualquer revisão. Agora vamos adicionar o middleware human-in-the-loop. A implementação é simples e requer apenas duas linhas de código:
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
system_prompt="Você é um assistente de e-mail prestativo para Sydney. Você pode enviar e-mails em nome do usuário.",
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={"send_email": True}
)
]
)
Ao adicionar o HumanInTheLoopMiddleware e especificar interrupt_on={"send_email": True}, dizemos ao agente para pausar antes de executar qualquer chamada da ferramenta send_email e aguardar aprovação humana. O valor True significa que todas as chamadas de envio de e-mail vão disparar uma interrupção com configuração padrão. Se quiséssemos mais controle, poderíamos especificar quais decisões são permitidas (aprovar, editar, rejeitar) ou fornecer descrições personalizadas para a interrupção.
Testando o Middleware em Cenários de Baixo Risco
Com o middleware em funcionamento, vamos testar em um cenário simples de e-mail. Imagine que o usuário pede ao agente para responder a um e-mail de uma colega chamada Alice sugerindo um café na próxima semana. O agente processa o pedido e decide enviar uma resposta simpática. Veja o que acontece:
O usuário envia uma mensagem: “Por favor, responda ao e-mail da Alice sobre tomar um café na semana que vem.”
O modelo do agente processa a solicitação e decide chamar a ferramenta send_email com parâmetros como recipient=“alice@example.com
”, subject=“Café na semana que vem?”, body=“Adoraria tomar um café com você na próxima semana!”
Antes do envio efetivo, o middleware intercepta a chamada da ferramenta e gera uma interrupção.
O revisor humano vê o e-mail proposto e o analisa. O e-mail está adequado—simpático, profissional e atende ao pedido do usuário.
O humano aprova a ação fornecendo uma decisão de aprovação.
O middleware permite a execução da ferramenta, e o e-mail é enviado.
Esse fluxo demonstra o caminho básico de aprovação. A revisão humana adiciona uma camada de segurança sem atrasar significativamente o processo. Para operações de baixo risco como essa, a aprovação geralmente é rápida, pois a ação proposta pelo agente é razoável.
Testando o Middleware em Cenários de Alto Risco: Resposta de Edição
Agora, vamos considerar um cenário mais crítico em que a edição se torna valiosa. Imagine que o agente recebe a solicitação de responder a um e-mail de um parceiro de startup pedindo para o usuário aprovar um orçamento de engenharia de US$ 1 milhão para o primeiro trimestre. Trata-se de uma decisão de alto risco que exige análise cuidadosa. O agente pode propor um e-mail como: “Revisei e aprovei a proposta de orçamento de US$ 1 milhão para o Q1.”
Quando esse e-mail chega ao revisor humano via interrupção do middleware, o humano percebe que é um compromisso financeiro significativo e que não deve ser aprovado sem mais análise. O humano não quer rejeitar a ideia de responder ao e-mail, mas deseja modificar a resposta para ser mais cautelosa. O humano fornece uma resposta de edição, mudando o corpo do e-mail para: “Obrigado pela proposta. Gostaria de revisar os detalhes com mais cuidado antes de aprovar. Pode me enviar um detalhamento de como o orçamento será alocado?”
Veja como uma resposta de edição aparece em código:
edit_decision = {
"type": "edit",
"edited_action": {
"name": "send_email",
"args": {
"recipient": "partner@startup.com",
"subject": "Proposta de Orçamento de Engenharia Q1",
"body": "Obrigado pela proposta. Gostaria de revisar os detalhes com mais cuidado antes de aprovar. Pode me enviar um detalhamento de como o orçamento será alocado?" }
}
}
Quando o middleware recebe essa decisão de edição, executa a ferramenta com os parâmetros modificados. O e-mail é enviado com o conteúdo revisado pelo humano, adequado à decisão financeira relevante. Isso demonstra o poder do tipo de resposta de edição: permite que humanos aproveitem o poder do agente de redigir comunicações, garantindo que o resultado final esteja alinhado ao julgamento humano e aos padrões da organização.
Testando o Middleware com Rejeição e Feedback
O tipo de resposta de rejeição é especialmente poderoso, pois não só impede uma ação inadequada, mas também fornece feedback que ajuda o agente a aprimorar seu raciocínio. Vamos considerar outro cenário com o mesmo e-mail de orçamento de alto valor. Suponha que o agente proponha um e-mail dizendo: “Revisei e aprovei o orçamento de US$ 1 milhão para o Q1.”
O revisor humano percebe que isso é precipitado demais. Um compromisso de US$ 1 milhão não deve ser aprovado sem análise detalhada, discussão com stakeholders e entendimento dos detalhes do orçamento. O humano não quer apenas editar o e-mail; deseja rejeitar completamente a abordagem e pedir ao agente para reconsiderar. O humano fornece uma resposta de rejeição com feedback:
reject_decision = {
"type": "reject",
"message": "Não posso aprovar esse orçamento sem mais informações. Por favor, redija um e-mail solicitando um detalhamento da proposta, incluindo como os fundos serão alocados entre as equipes de engenharia e quais entregáveis específicos são esperados."}
Quando o middleware recebe essa rejeição, não executa a ferramenta. Em vez disso, envia a mensagem de rejeição ao agente como parte do contexto da conversa. O agente percebe que sua proposta foi rejeitada e entende o motivo. Ele pode então raciocinar sobre o feedback e propor uma abordagem diferente. Neste caso, pode sugerir um novo e-mail pedindo mais detalhes sobre a proposta de orçamento, resposta mais adequada para um pedido financeiro relevante. O humano pode então revisar essa proposta revisada e aprová-la, editá-la ou rejeitá-la novamente, se necessário.
Esse processo iterativo—propor, revisar, rejeitar com feedback, propor novamente—é um dos maiores valores do middleware human-in-the-loop. Cria um fluxo colaborativo em que a velocidade e o raciocínio do agente se unem ao julgamento e experiência humana.
Impulsione Seu Workflow com o FlowHunt
Descubra como o FlowHunt automatiza seus fluxos de conteúdo e SEO com IA — do levantamento e geração de conteúdo à publicação e análise — tudo em um só lugar.
Configuração Avançada: Controle Granular das Interrupções
Embora a implementação básica do middleware human-in-the-loop seja simples, o LangChain oferece opções avançadas de configuração para refinar exatamente como e quando as interrupções ocorrem. Uma configuração importante é especificar quais tipos de decisão são permitidos para cada ferramenta. Por exemplo, você pode querer permitir aprovação e edição para envios de e-mail, mas não rejeição. Ou permitir todas as decisões em transações financeiras, mas apenas aprovação para consultas de leitura.
Veja um exemplo de configuração granular:
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"]
},
"read_database": False, # Aprovação automática, sem interrupção"delete_record": {
"allowed_decisions": ["approve", "reject"] # Sem edição para exclusões }
}
)
]
)
Neste exemplo, envios de e-mail vão interromper e permitir os três tipos de decisão. Operações de leitura serão executadas automaticamente sem interrupção. Operações de exclusão vão interromper, mas não permitir edição—o humano pode apenas aprovar ou rejeitar, não modificar os parâmetros de exclusão. Esse controle granular assegura que a supervisão humana seja aplicada apenas onde necessário, evitando gargalos em operações de baixo risco.
Outro recurso avançado é a possibilidade de fornecer descrições personalizadas para as interrupções. Por padrão, o middleware exibe uma mensagem genérica como “Execução da ferramenta requer aprovação.” Você pode personalizar para fornecer informações contextuais:
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"],
"description": "Envios de e-mail requerem aprovação humana antes da execução" }
}
)
Considerações Importantes de Implementação: Checkpointers e Gerenciamento de Estado
Um aspecto crítico fácil de ser negligenciado ao implementar middleware human-in-the-loop é a necessidade de um checkpointer. Um checkpointer é um mecanismo que salva o estado do agente no momento da interrupção, permitindo que o fluxo seja retomado depois. Isso é essencial porque a revisão humana não ocorre instantaneamente—pode haver um atraso entre a interrupção e a decisão do humano. Sem um checkpointer, o estado do agente seria perdido nesse intervalo e não seria possível retomar o fluxo adequadamente.
O LangChain oferece várias opções de checkpointer. Para desenvolvimento e testes, pode-se usar um checkpointer em memória:
Para sistemas de produção, normalmente você vai querer um checkpointer persistente, que salva o estado em banco de dados ou sistema de arquivos, garantindo que as interrupções possam ser retomadas mesmo após reinicializações. O checkpointer mantém um registro completo do estado do agente em cada etapa, incluindo histórico da conversa, chamadas de ferramentas feitas e seus resultados. Quando um humano fornece sua decisão (aprovar, editar ou rejeitar), o middleware usa o checkpointer para recuperar o estado salvo, aplicar a decisão e retomar o loop do agente a partir daquele ponto.
Aplicações e Casos de Uso Reais
O middleware human-in-the-loop se aplica a uma grande variedade de cenários reais onde agentes autônomos precisam agir, mas essas ações requerem supervisão humana. No setor financeiro, agentes que processam transações, aprovam empréstimos ou gerenciam investimentos podem usar o middleware para garantir que decisões de alto valor sejam revisadas antes da execução. Na saúde, agentes que recomendam tratamentos ou acessam registros de pacientes podem garantir conformidade com regulamentos de privacidade e protocolos clínicos. No setor jurídico, agentes que redigem comunicações ou acessam documentos confidenciais podem garantir supervisão advocatícia. No atendimento ao cliente, agentes que oferecem reembolsos, fazem compromissos ou tratam escalonamentos podem usar middleware para garantir alinhamento com políticas da empresa.
Além dessas aplicações setoriais, o middleware human-in-the-loop é útil em qualquer cenário onde o custo de um erro do agente seja significativo. Inclui sistemas de moderação de conteúdo, RH (decisões trabalhistas), supply chain (pedidos ou ajustes de estoque) e muito mais. O ponto em comum é que as ações propostas pelo agente têm consequências reais e relevantes, justificando a revisão humana antes da execução.
Comparação com Abordagens Alternativas
Vale a pena considerar como o middleware human-in-the-loop se compara a outras abordagens para adicionar supervisão humana a sistemas de agentes. Uma alternativa é revisar todas as saídas do agente após a execução, mas isso apresenta limitações sérias. Quando um humano revisa, a ação já foi executada e pode ser difícil ou impossível reverter—um e-mail já foi enviado, um registro já foi deletado, uma transação já foi processada. O middleware human-in-the-loop previne que essas ações irreversíveis aconteçam.
Outra alternativa é que humanos realizem manualmente todas as tarefas que os agentes podem executar, mas isso anula o propósito dos agentes. Agentes agregam valor justamente por realizarem tarefas rotineiras rapidamente e liberarem humanos para decisões mais complexas. O objetivo do middleware human-in-the-loop é o equilíbrio: agentes cuidam do trabalho rotineiro, mas pausam para revisão humana quando o risco é alto.
Uma terceira alternativa é implementar guardrails ou regras de validação que previnam ações inadequadas. Por exemplo, impedir que agentes enviem e-mails para endereços externos ou deletem registros sem confirmação. Guardrails são úteis e devem ser usados em conjunto, mas têm limitações: normalmente são baseados em regras e não conseguem prever todos os cenários inadequados. O julgamento humano é mais flexível e sensível ao contexto do que regras fixas, por isso o middleware human-in-the-loop é tão valioso.
Boas Práticas para Implementar Workflows Human-in-the-Loop
Ao implementar middleware human-in-the-loop em suas aplicações, algumas boas práticas ajudam a garantir eficácia e eficiência. Primeiro, seja estratégico ao escolher quais ferramentas requerem interrupção. Interromper toda chamada de ferramenta criará gargalos; foque nas que são caras, arriscadas ou com consequências relevantes. Operações somente leitura raramente exigem interrupção. Operações de escrita ou que tomam ações externas geralmente sim.
Segundo, forneça contexto claro aos revisores humanos. Quando ocorre uma interrupção, o humano precisa entender qual ação o agente propõe e o motivo. Certifique-se de que as descrições das interrupções sejam claras e tragam contexto relevante. Se for envio de e-mail, mostre o conteúdo completo. Se for exclusão de registro, mostre qual registro e por quê. Quanto mais contexto, mais rápida e precisa será a decisão humana.
Terceiro, torne o processo de aprovação o mais simples possível. Humanos tendem a aprovar ações rapidamente se o processo for fácil e direto. Ofereça botões ou opções claras para aprovar, editar e rejeitar. Se edição for permitida, facilite a modificação dos parâmetros relevantes, sem exigir conhecimento técnico.
Quarto, use feedback de rejeição de forma estratégica. Ao rejeitar uma ação, forneça feedback claro sobre o motivo e o que o agente deve fazer em vez disso. Esse feedback ajuda o agente a aprender e aprimorar suas decisões. Com o tempo, o agente deve se calibrar melhor aos padrões e tolerância a risco da sua organização.
Quinto, monitore e analise padrões das interrupções. Acompanhe quais ferramentas são mais interrompidas, quais decisões (aprovar, editar, rejeitar) são mais comuns e quanto tempo leva o processo de aprovação. Esses dados ajudam a identificar gargalos, refinar configurações de interrupção e potencialmente melhorar prompts ou lógica de seleção de ferramentas do agente.
Integrando Middleware Human-in-the-Loop com o FlowHunt
Para organizações que desejam implementar workflows human-in-the-loop em escala, o FlowHunt oferece uma plataforma abrangente que se integra perfeitamente às capacidades de middleware do LangChain. O FlowHunt permite criar, implantar e gerenciar agentes de IA com fluxos de aprovação integrados, facilitando adicionar supervisão humana aos processos de automação. Com o FlowHunt, você configura quais ferramentas requerem aprovação humana, personaliza a interface de aprovação para suas necessidades e rastreia todas as aprovações e rejeições para fins de conformidade e auditoria. A plataforma gerencia a complexidade do gerenciamento de estado, checkpointing e orquestração de workflow, permitindo que você foque na construção de agentes eficazes e definição de políticas de aprovação. A integração do FlowHunt com o LangChain permite aproveitar todo o poder do middleware human-in-the-loop, com uma interface amigável e confiabilidade de nível empresarial.
Conclusão
Middleware human-in-the-loop representa uma ponte essencial entre a eficiência de agentes de IA autônomos e a necessidade de supervisão humana em sistemas de produção. Ao implementar fluxos de aprovação, capacidades de edição e mecanismos de feedback para rejeições, você constrói agentes poderosos e seguros. O modelo de decisão tripla—aprovar, editar, rejeitar—oferece flexibilidade para atender diferentes níveis de supervisão humana, desde operações simples que podem ser rapidamente aprovadas até decisões críticas que exigem análise e modificação cuidadosas. A implementação é direta, exigindo poucas linhas de código no LangChain, mas o impacto na confiabilidade e segurança do sistema é substancial. À medida que agentes de IA se tornam mais capazes e assumem processos críticos de negócio, middleware human-in-the-loop será componente essencial para uma IA responsável. Seja construindo assistentes de e-mail, sistemas financeiros, aplicações em saúde ou qualquer outro domínio onde ações de agentes têm consequências reais, o middleware human-in-the-loop fornece a estrutura necessária para garantir que o julgamento humano permaneça central nos fluxos de automação.
Perguntas frequentes
Middleware human-in-the-loop é um componente que pausa a execução do agente de IA antes de rodar ferramentas específicas, permitindo que humanos aprovem, editem ou rejeitem a ação proposta. Isso adiciona uma camada de segurança para operações caras ou arriscadas.
Use para operações de alto risco, como envio de e-mails, transações financeiras, escritas em banco de dados ou qualquer execução de ferramenta que exija supervisão de conformidade ou possa ter consequências significativas se executada incorretamente.
Os três principais tipos de resposta são: Aprovação (executar a ferramenta conforme proposto), Edição (modificar os parâmetros da ferramenta antes da execução) e Rejeição (recusar a execução e enviar feedback ao modelo para revisão).
Importe HumanInTheLoopMiddleware de langchain.agents.middleware, configure com as ferramentas que deseja interromper e passe para a função de criação do agente. Você também precisará de um checkpointer para manter o estado entre as interrupções.
Arshia é Engenheira de Fluxos de Trabalho de IA na FlowHunt. Com formação em ciência da computação e paixão por IA, ela se especializa em criar fluxos de trabalho eficientes que integram ferramentas de IA em tarefas do dia a dia, aumentando a produtividade e a criatividade.
Arshia Kahani
Engenheira de Fluxos de Trabalho de IA
Automatize Seus Fluxos de IA com Segurança usando FlowHunt
Construa agentes inteligentes com fluxos de aprovação integrados e supervisão humana. O FlowHunt facilita a implementação de automação human-in-the-loop para seus processos de negócios.
Construindo Agentes de IA Extensíveis: Um Mergulho Profundo na Arquitetura de Middleware
Descubra como a arquitetura de middleware do LangChain 1.0 revoluciona o desenvolvimento de agentes, permitindo que desenvolvedores criem agentes profundos e po...
Human-in-the-Loop (HITL) é uma abordagem de IA e aprendizado de máquina que integra a experiência humana no treinamento, ajuste e aplicação de sistemas de IA, a...
Compreendendo o Human in the Loop para Chatbots: Aprimorando a IA com Expertise Humana
Descubra a importância e as aplicações do Human in the Loop (HITL) em chatbots de IA, onde a expertise humana aprimora sistemas de IA para maior precisão, padrõ...
7 min de leitura
AI
Chatbots
+5
Consentimento de Cookies Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.