
Observabilitate FlowHunt în Langfuse
Acest articol explică cum să conectezi FlowHunt cu Langfuse pentru o observabilitate cuprinzătoare, să urmărești performanța fluxurilor de lucru AI și să folose...
6 min citire
integration
Langfuse
+3

Noul toolkit CLI open-source al FlowHunt permite evaluarea completă a fluxurilor cu LLM ca Judecător, oferind raportare detaliată și evaluare automată a calității pentru fluxurile AI.
Suntem entuziasmați să anunțăm lansarea FlowHunt CLI Toolkit – noul nostru instrument open-source de linie de comandă creat pentru a revoluționa modul în care dezvoltatorii evaluează și testează fluxurile AI. Acest toolkit puternic aduce capabilități de evaluare a fluxurilor la nivel enterprise în comunitatea open-source, completate de raportare avansată și de implementarea inovatoare „LLM ca Judecător”.
FlowHunt CLI Toolkit reprezintă un pas semnificativ înainte în testarea și evaluarea fluxurilor AI. Disponibil acum pe GitHub , acest toolkit open-source oferă dezvoltatorilor instrumente complete pentru:
Toolkit-ul reflectă angajamentul nostru pentru transparență și dezvoltare orientată spre comunitate, făcând tehnicile avansate de evaluare AI accesibile dezvoltatorilor din întreaga lume.
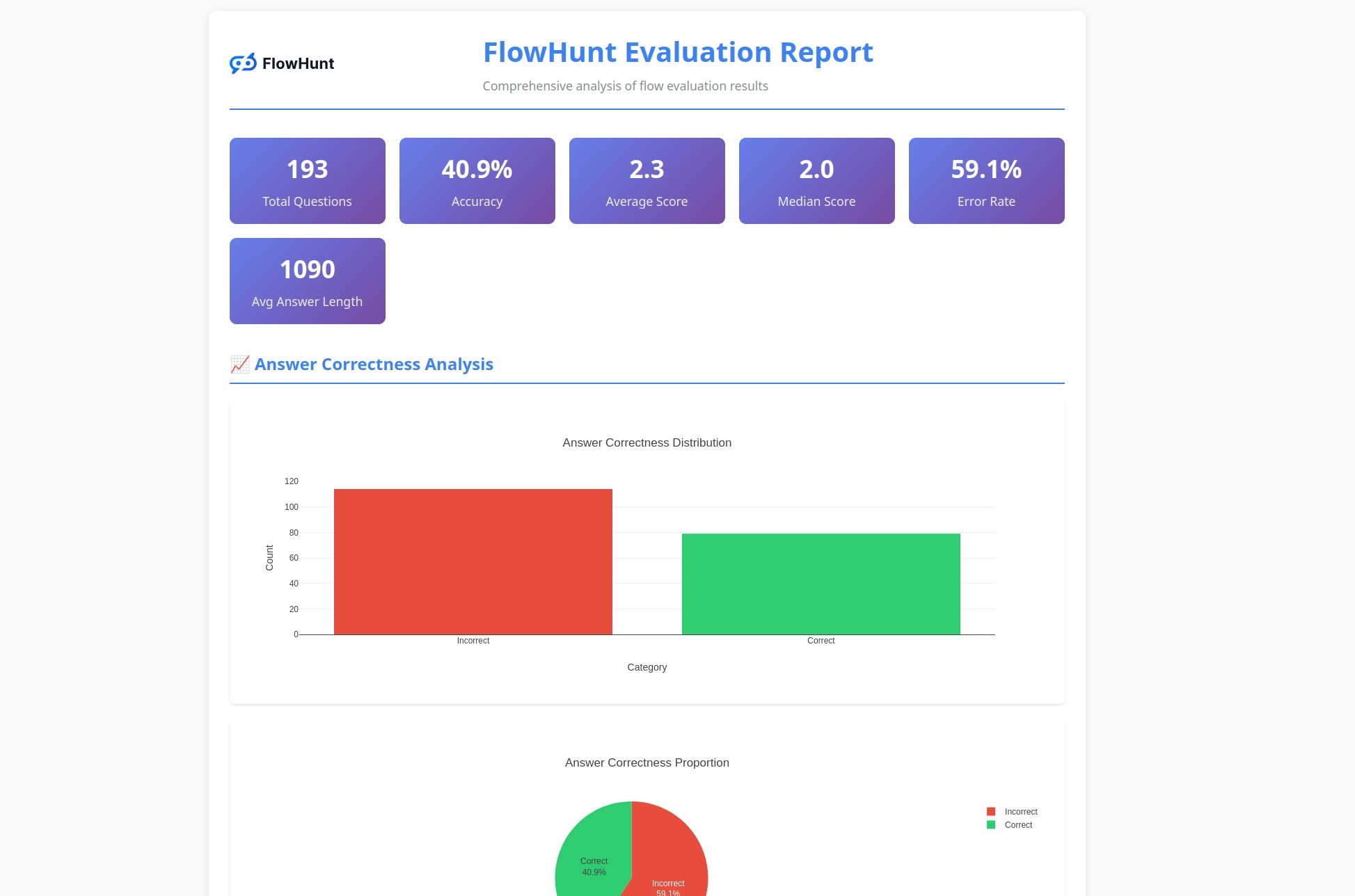
Una dintre cele mai inovatoare funcționalități ale toolkit-ului CLI este implementarea „LLM ca Judecător”. Această abordare folosește inteligența artificială pentru a evalua calitatea și corectitudinea răspunsurilor generate de AI – practic, AI evaluează performanța AI cu capabilități de raționament avansat.
Ce face implementarea noastră unică este faptul că am folosit chiar FlowHunt pentru a crea fluxul de evaluare. Această abordare meta demonstrează puterea și flexibilitatea platformei noastre, oferind în același timp un sistem robust de evaluare. Fluxul LLM ca Judecător constă din mai multe componente interconectate:
1. Șablon de prompt: Creează promptul de evaluare cu criterii specifice
2. Generator de Output Structurat: Procesează evaluarea folosind un LLM
3. Parser de date: Formatează rezultatul structurat pentru raportare
4. Output chat: Prezintă rezultatele finale ale evaluării
În centrul sistemului nostru LLM ca Judecător se află un prompt atent conceput, care asigură evaluări consistente și de încredere. Iată șablonul principal de prompt pe care îl folosim:
You will be given an ANSWER and REFERENCE couple.
Your task is to provide the following:
1. a 'total_rating' scoring: how close is the ANSWER to the REFERENCE
2. a binary label 'correctness' which can be either 'correct' or 'incorrect', which defines if the ANSWER is correct or not
3. and 'reasoning', which describes the reason behind your choice of scoring and correctness/incorrectness of ANSWER
An ANSWER is correct when it is the same as the REFERENCE in all facts and details, even if worded differently. the ANSWER is incorrect if it contradicts the REFERENCE, changes or omits details. its ok if the ANSWER has more details comparing to REFERENCE.
'total rating' is a scale of 1 to 4, where 1 means that the ANSWER is not the same as REFERENCE at all, and 4 means that the ANSWER is the same as the REFERENCE in all facts and details even if worded differently.
Here is the scale you should use to build your answer:
1: The ANSWER is contradicts the REFERENCE completely, adds additional claims, changes or omits details
2: The ANSWER points to the same topic but the details are omitted or changed completely comparing to REFERENCE
3: The ANSWER's references are not completely correct, but the details are somewhat close to the details mentioned in the REFERENCE. its ok, if there are added details in ANSWER comparing to REFERENCES.
4: The ANSWER is the same as the REFERENCE in all facts and details, even if worded differently. its ok, if there are added details in ANSWER comparing to REFERENCES. if there are sources available in REFERENCE, its exactly the same as ANSWER and is for sure mentioned in ANSWER
REFERENCE
===
{target_response}
===
ANSWER
===
{actual_response}
===
Acest prompt asigură că judecătorul nostru LLM oferă:
Începe perioada de probă gratuită astăzi și vezi rezultate în câteva zile.
Fluxul nostru LLM ca Judecător demonstrează un design sofisticat al fluxurilor AI folosind constructorul vizual de fluxuri al FlowHunt. Iată cum colaborează componentele:
Fluxul începe cu o componentă Chat Input care primește cererea de evaluare ce conține atât răspunsul real, cât și răspunsul de referință.
Componenta Prompt Template construiește dinamic promptul de evaluare prin:
{target_response}{actual_response}Structured Output Generator procesează promptul folosind un LLM selectat și generează output structurat ce conține:
total_rating: Scor numeric de la 1 la 4correctness: Clasificare binară corect/incorectreasoning: Explicație detaliată a evaluăriiComponenta Parse Data formatează output-ul structurat într-un format ușor de citit, iar componenta Chat Output prezintă rezultatul final al evaluării.
Sistemul LLM ca Judecător oferă mai multe capabilități avansate care îl fac deosebit de eficient pentru evaluarea fluxurilor AI:
Spre deosebire de simplele comparații de stringuri, judecătorul nostru LLM înțelege:
Scala de rating în 4 puncte oferă o evaluare granulară:
Fiecare evaluare include un raționament detaliat, ceea ce permite:
Primește cele mai recente sfaturi, tendințe și oferte gratuit.
Toolkit-ul CLI generează rapoarte detaliate care oferă perspective valoroase asupra performanței fluxurilor:
Ești gata să îți evaluezi fluxurile AI cu instrumente profesionale? Iată cum poți începe:
Instalare dintr-o linie (recomandat) pentru macOS și Linux:
curl -sSL https://raw.githubusercontent.com/yasha-dev1/flowhunt-toolkit/main/install.sh | bash
Aceasta va:
flowhunt în PATH-ul tăuInstalare manuală:
# Clonează repository-ul
git clone https://github.com/yasha-dev1/flowhunt-toolkit.git
cd flowhunt-toolkit
# Instalează cu pip
pip install -e .
Verifică instalarea:
flowhunt --help
flowhunt --version
1. Autentificare Mai întâi, autentifică-te cu API-ul FlowHunt:
flowhunt auth
2. Listează fluxurile tale
flowhunt flows list
3. Evaluează un flux Creează un fișier CSV cu datele de test:
flow_input,expected_output
"What is 2+2?","4"
"What is the capital of France?","Paris"
Rulează evaluarea cu LLM ca Judecător:
flowhunt evaluate your-flow-id path/to/test-data.csv --judge-flow-id your-judge-flow-id
4. Execuție batch a fluxurilor
flowhunt batch-run your-flow-id input.csv --output-dir results/
Sistemul de evaluare oferă analiză completă:
flowhunt evaluate FLOW_ID TEST_DATA.csv \
--judge-flow-id JUDGE_FLOW_ID \
--output-dir eval_results/ \
--batch-size 10 \
--verbose
Funcționalitățile includ:
Toolkit-ul CLI se integrează perfect cu platforma FlowHunt, permițându-ți să:
Lansarea toolkit-ului nostru CLI reprezintă mai mult decât un nou instrument – este o viziune pentru viitorul dezvoltării AI unde:
Calitatea este Măsurabilă: Tehnici avansate de evaluare fac performanța AI cuantificabilă și comparabilă.
Testarea este Automată: Cadrul de testare complet reduce efortul manual și crește fiabilitatea.
Transparența este Standard: Raționamentele și rapoartele detaliate fac comportamentul AI inteligibil și ușor de depanat.
Comunitatea Impulsionează Inovația: Instrumentele open-source permit îmbunătățirea colaborativă și schimbul de cunoștințe.
Prin open-sourcing-ul FlowHunt CLI Toolkit, ne demonstrăm angajamentul pentru:
FlowHunt CLI Toolkit cu LLM ca Judecător reprezintă un avans semnificativ în capabilitățile de evaluare a fluxurilor AI. Prin combinarea logicii de evaluare sofisticate cu raportare completă și accesibilitate open-source, oferim dezvoltatorilor infrastructura necesară pentru a construi sisteme AI mai bune și mai fiabile.
Abordarea meta de a folosi FlowHunt pentru a evalua fluxurile FlowHunt demonstrează maturitatea și flexibilitatea platformei noastre, oferind în același timp un instrument puternic pentru întreaga comunitate AI.
Fie că dezvolți chatboți simpli sau sisteme multi-agent complexe, FlowHunt CLI Toolkit oferă infrastructura de evaluare de care ai nevoie pentru a asigura calitate, fiabilitate și îmbunătățire continuă.
Ești gata să treci la următorul nivel în evaluarea fluxurilor AI? Vizitează repository-ul nostru GitHub pentru a începe cu FlowHunt CLI Toolkit și experimentează puterea LLM ca Judecător.
Viitorul dezvoltării AI este aici – și este open source.
FlowHunt CLI Toolkit este un instrument open-source de linie de comandă pentru evaluarea fluxurilor AI cu capabilități avansate de raportare. Include funcționalități precum evaluarea LLM ca Judecător, analiză a rezultatelor corecte/incorecte și metrici de performanță detaliate.
LLM ca Judecător folosește un flux AI sofisticat construit în FlowHunt pentru a evalua alte fluxuri. Compară răspunsurile reale cu răspunsurile de referință, oferind scoruri, evaluări de corectitudine și raționamente detaliate pentru fiecare evaluare.
FlowHunt CLI Toolkit este open-source și disponibil pe GitHub la https://github.com/yasha-dev1/flowhunt-toolkit. Îl poți clona, contribui și folosi gratuit pentru evaluarea fluxurilor AI.
Toolkit-ul generează rapoarte detaliate care includ analiza rezultatelor corecte/incorecte, evaluări cu LLM ca Judecător cu scoruri și raționamente, metrici de performanță și analiză detaliată a comportamentului fluxului pe diverse cazuri de testare.
Da! Fluxul LLM ca Judecător este construit folosind platforma FlowHunt și poate fi adaptat pentru diverse scenarii de evaluare. Poți modifica șablonul prompt-ului și criteriile de evaluare în funcție de cazurile tale specifice.
Yasha este un dezvoltator software talentat, specializat în Python, Java și învățare automată. Yasha scrie articole tehnice despre inteligența artificială, ingineria prompturilor și dezvoltarea chatboturilor.

Construiește și evaluează fluxuri AI sofisticate cu platforma FlowHunt. Începe să creezi fluxuri care pot evalua alte fluxuri chiar azi.
Acest articol explică cum să conectezi FlowHunt cu Langfuse pentru o observabilitate cuprinzătoare, să urmărești performanța fluxurilor de lucru AI și să folose...

FlowHunt 2.4.1 introduce noi modele AI majore, inclusiv Claude, Grok, Llama, Mistral, DALL-E 3 și Stable Diffusion, extinzând opțiunile tale de experimentare, c...
Editorul de Fluxuri îți permite să tragi și să plasezi componente care reprezintă diverse abilități AI. Nu sunt necesare cunoștințe de programare, asigurând un ...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.