Programe
Funcția Programe din FlowHunt îți permite să accesezi periodic domenii și canale YouTube, menținând chatbot-urile și fluxurile tale la zi cu cele mai noi inform...
3 min citire
AI
Schedules
+4
Află cum să configurezi programe automate pentru crawlarea site-urilor web, sitemap-urilor, domeniilor și canalelor YouTube pentru a menține baza de cunoștințe a Agentului tău AI actualizată.
Funcția de Programare a FlowHunt îți permite să automatizezi crawling-ul și indexarea site-urilor web, sitemap-urilor, domeniilor și canalelor YouTube. Astfel, baza de cunoștințe a Agentului tău AI rămâne actualizată cu conținut nou, fără intervenție manuală.
Crawling automatizat:
Programează crawl-uri recurente care rulează zilnic, săptămânal, lunar sau anual pentru a menține baza de cunoștințe actualizată.
Tipuri multiple de crawl:
Poți alege între crawl de domeniu, crawl de sitemap, crawl de URL sau crawl de canal YouTube, în funcție de sursa ta de conținut.
Opțiuni avansate:
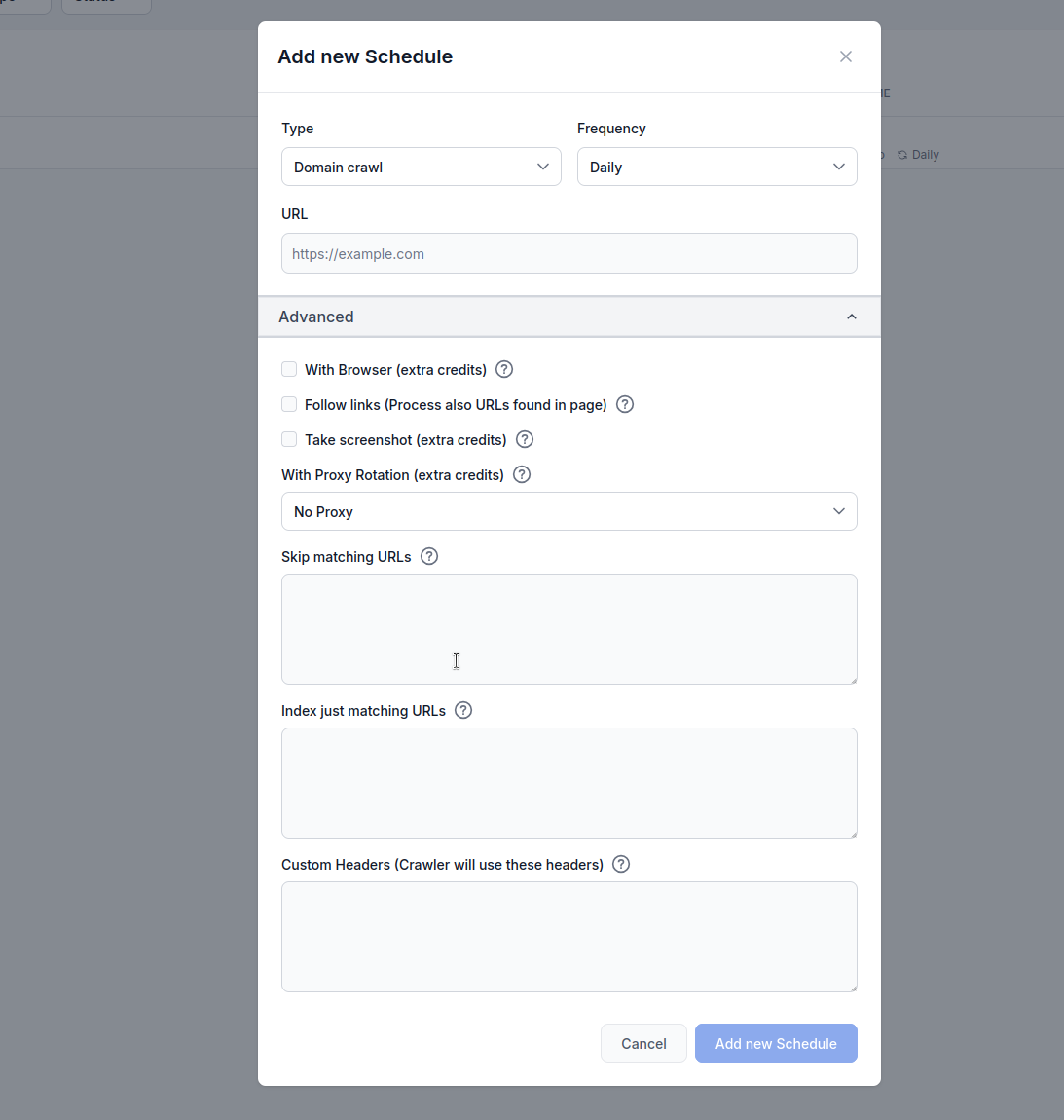
Configurează randarea cu browser, urmărirea link-urilor, capturi de ecran, rotația proxy-urilor și filtrarea URL-urilor pentru rezultate optime.
Tip: Alege metoda de crawling:
Frecvență: Setează cât de des rulează crawl-ul:
URL: Introdu URL-ul țintă, domeniul sau canalul YouTube de crawlat
Cu browser (credit suplimentar): Activează când crawlezi site-uri web bogate în JavaScript ce necesită randare completă cu browserul. Această opțiune este mai lentă și mai costisitoare, dar necesară pentru site-urile care încarcă dinamic conținutul.
Urmărește link-uri (credit suplimentar): Procesează URL-uri suplimentare găsite în pagini. Util când sitemap-ul nu conține toate URL-urile, dar poate consuma multe credite deoarece crawlează și link-urile descoperite.
Fă captură de ecran (credit suplimentar): Realizează capturi vizuale în timpul crawling-ului. Util pentru site-urile fără og:images sau cele care necesită context vizual pentru procesarea AI.
Cu rotație proxy (credit suplimentar): Rotește adresa IP la fiecare cerere pentru a evita detecția de către firewall-uri de aplicație web (WAF) sau sisteme anti-bot.
Sări peste URL-urile care se potrivesc: Introdu șiruri (câte unul pe linie) pentru a exclude din crawling URL-urile ce conțin aceste modele. Exemplu:
/admin/
/login
.pdf
Acest exemplu explică ce se întâmplă când utilizezi funcția Programări a FlowHunt pentru a crawla domeniul flowhunt.io cu setarea /blog ca URL de sărit în setările de filtrare URL.
Setări de configurare
flowhunt.io/blogCe se întâmplă
Inițierea crawl-ului:
flowhunt.io, țintind toate paginile accesibile de pe domeniu (ex: flowhunt.io, flowhunt.io/features, flowhunt.io/pricing etc.).Aplicarea filtrării URL:
/blog./blog (ex: flowhunt.io/blog, flowhunt.io/blog/post1, flowhunt.io/blog/category) este exclus din crawling.flowhunt.io/about, flowhunt.io/contact sau flowhunt.io/docs, sunt crawlate deoarece nu se potrivesc cu modelul /blog.Execuția crawl-ului:
flowhunt.io, indexând conținutul lor pentru baza ta de cunoștințe AI.Rezultat:
flowhunt.io, excluzând orice se află sub calea /blog./blog), fără intervenție manuală.Indexează doar URL-urile care se potrivesc: Introdu șiruri (câte unul pe linie) pentru a crawla doar URL-urile ce conțin aceste modele. Exemplu:
/blog/
/articles/
/knowledge/
Setări de configurare
flowhunt.io/blog/
/articles/
/knowledge/
Inițierea crawl-ului:
flowhunt.io, țintind toate paginile accesibile de pe domeniu (ex: flowhunt.io, flowhunt.io/blog, flowhunt.io/articles etc.).Aplicarea filtrării URL:
/blog/, /articles/ și /knowledge/.flowhunt.io/blog/post1, flowhunt.io/articles/news, flowhunt.io/knowledge/guide) sunt incluse în crawling.flowhunt.io/about, flowhunt.io/pricing sau flowhunt.io/contact, sunt excluse deoarece nu se potrivesc cu modelele specificate.Execuția crawl-ului:
/blog/, /articles/ sau /knowledge/, indexând conținutul acestora pentru baza ta de cunoștințe AI.Rezultat:
flowhunt.io aflate sub căile /blog/, /articles/ și /knowledge/.Header-e personalizate:
Adaugă header-e HTTP personalizate pentru cererile de crawling. Formatează ca HEADER=Valoare (câte unul pe linie):
Această funcționalitate este extrem de utilă pentru a adapta crawling-ul la cerințele specifice ale unui site web. Activând header-ele personalizate, utilizatorii pot autentifica cererile pentru a accesa conținut restricționat, pot imita anumite comportamente de browser sau se pot conforma politicilor API sau de acces ale unui site. De exemplu, setarea unui header Authorization poate permite accesul la pagini protejate, iar un User-Agent personalizat poate evita detecția bot-ului sau poate asigura compatibilitatea cu site-urile care restricționează anumite crawlere. Această flexibilitate asigură colectarea de date mai precisă și cuprinzătoare, facilitând indexarea conținutului relevant pentru baza de cunoștințe a unui Agent AI, respectând în același timp protocoalele de securitate sau acces ale site-ului.
MYHEADER=Orice valoare
Authorization=Bearer token123
User-Agent=Custom crawler
Începe perioada de probă gratuită astăzi și vezi rezultate în câteva zile.
Navighează la Programe în dashboard-ul tău FlowHunt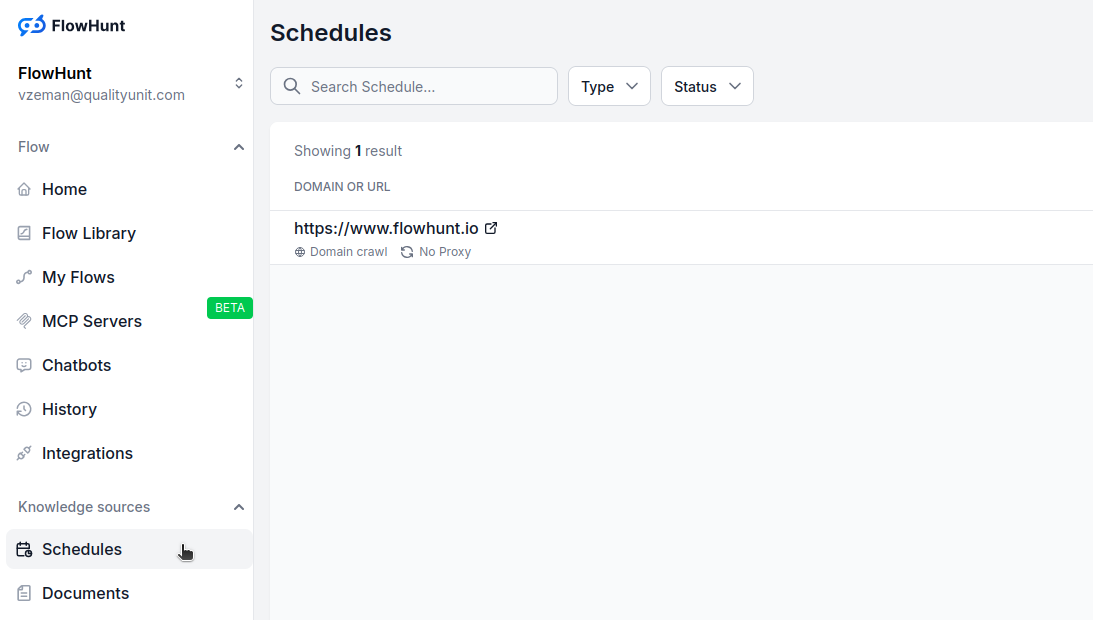
Apasă “Adaugă program nou”
Configurează setările de bază:
Extinde opțiunile avansate dacă este necesar:
Apasă “Adaugă program nou” pentru a activa
Pentru majoritatea site-urilor:
Pentru site-uri cu mult JavaScript:
Pentru site-uri mari:
Pentru e-commerce sau conținut dinamic:
Primește cele mai recente sfaturi, tendințe și oferte gratuit.
Funcțiile avansate consumă credite suplimentare:
Monitorizează consumul de credite și ajustează programele în funcție de nevoile și bugetul tău.
Eșecuri la crawling:
Prea multe/prea puține pagini:
Conținut lipsă:
Funcția Programe din FlowHunt îți permite să accesezi periodic domenii și canale YouTube, menținând chatbot-urile și fluxurile tale la zi cu cele mai noi inform...
Află cum agenții AI pot genera automat articole de blog optimizate SEO, pot crea fișiere markdown și pot trimite pull request-uri pe GitHub — totul pornind de l...
Integrează FlowHunt cu Firecrawl MCP Server pentru a activa funcționalități avansate de web scraping, crawling și cercetare automată aprofundată. Simplifică des...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.