
Snowflake MCP-server
Snowflake MCP-server möjliggör sömlös AI-driven interaktion med Snowflake-databaser genom att exponera avancerade verktyg och resurser via Model Context Protoco...
4 min läsning
AI
Database
+5
FlowHunt erbjuder ett extra säkerhetslager mellan dina interna system och AI-verktyg, vilket ger dig granulär kontroll över vilka verktyg som är tillgängliga från dina MCP-servrar. MCP-servrar som hostas i vår infrastruktur kan sömlöst integreras med FlowHunts chatbot samt populära AI-plattformar som ChatGPT, Claude och olika AI-redigerare.
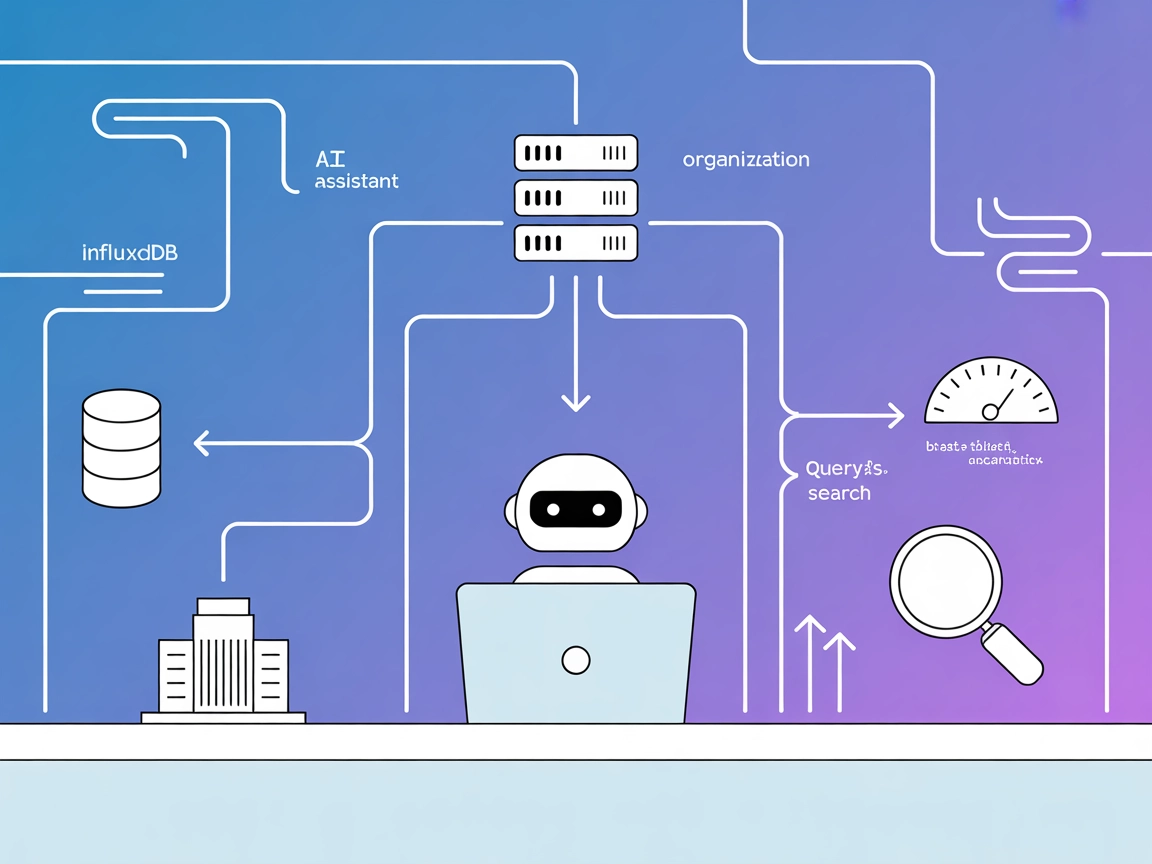
InfluxDB MCP-servern är en Model Context Protocol (MCP)-server som är utformad för att ge sömlös åtkomst till en InfluxDB-instans via InfluxDB OSS API v2. Den fungerar som ett mellanliggande verktyg som kopplar AI-assistenter till tidsseriedata lagrad i InfluxDB, vilket möjliggör förbättrade arbetsflöden för utvecklare och AI-system. Genom sitt standardiserade gränssnitt exponerar servern både resurser (såsom organisationer, buckets och mätningar) och verktyg (såsom att fråga och skriva data), vilket ger AI-klienter möjlighet att utföra uppgifter som att köra databasfrågor, hantera databuckets eller integrera tidsserieanalys i sina applikationer. Denna robusta integrering säkerställer att utvecklare kan automatisera datahantering, effektivisera utvecklingsprocesser och stärka applikationens intelligens genom att utnyttja realtids- och historisk data från InfluxDB.
Starta din kostnadsfria provperiod idag och se resultat inom några dagar.
influxdb://orgs): Visar alla organisationer i InfluxDB-instansen.influxdb://buckets): Visar alla buckets med tillhörande metadata.influxdb://bucket/{bucketName}/measurements): Listar alla mätningar inom en specificerad bucket.influxdb://query/{orgName}/{fluxQuery}): Kör en Flux-fråga och returnerar resultat som en resurs.Få de senaste tipsen, trenderna och erbjudandena gratis.
Kontrollera att Node.js är installerat på din dator.
Öppna Windsurf-konfigurationsfilen (t.ex. windsurf.json eller motsvarande).
Lägg till InfluxDB MCP-servern i objektet mcpServers:
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
]
}
}
}
Spara filen och starta om Windsurf.
Verifiera genom att kontrollera att InfluxDB MCP-servern visas i listan över MCP-servrar.
Skydda API-nycklar
Ange känsliga värden som miljövariabler. Exempel:
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
],
"env": {
"INFLUXDB_TOKEN": "${INFLUXDB_TOKEN_ENV}"
}
}
}
}
Installera Node.js om det inte redan finns.
Lokalisera Claudes konfigurationsfil.
Lägg till InfluxDB MCP-servern till mcpServers:
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
]
}
}
}
Spara ändringar och starta om Claude.
Bekräfta installationen via Claudes gränssnitt.
Skydda API-nycklar
(Se Windsurf-exemplet ovan.)
Kontrollera att Node.js finns installerat.
Öppna Cursors inställningar eller konfigurationsfil.
Lägg till InfluxDB MCP-servern med:
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
]
}
}
}
Spara och starta om Cursor.
Kontrollera MCP-serverns uppkoppling.
Skydda API-nycklar
(Se Windsurf-exemplet ovan.)
Kontrollera att Node.js är installerat.
Redigera Clines konfigurationsfil.
Lägg in följande under mcpServers:
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
]
}
}
}
Spara filen och starta om Cline.
Kontrollera att servern är aktiv i Cline.
Skydda API-nycklar
(Se Windsurf-exemplet ovan.)
Använda MCP i FlowHunt
För att integrera MCP-servrar i ditt FlowHunt-arbetsflöde, börja med att lägga till MCP-komponenten i ditt flöde och koppla den till din AI-agent:

Klicka på MCP-komponenten för att öppna konfigurationspanelen. I systemets MCP-konfigurationssektion, lägg in dina MCP-serveruppgifter med detta JSON-format:
{
"influxdb-mcp": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
När detta är konfigurerat kan AI-agenten nu använda denna MCP som ett verktyg med tillgång till alla dess funktioner och möjligheter. Kom ihåg att ändra “influxdb-mcp” till det faktiska namnet på din MCP-server och ersätt URL:en med din egen MCP-server-URL.
| Sektion | Tillgänglighet | Detaljer/Noteringar |
|---|---|---|
| Översikt | ✅ | Finns i README.md |
| Lista över prompts | ✅ | flux-query-examples, line-protocol-guide |
| Lista över resurser | ✅ | orgs, buckets, bucket measurements, Flux query |
| Lista över verktyg | ✅ | write-data, query-data, create-bucket, create-org |
| Skydda API-nycklar | ✅ | Exempel med miljövariabel finns i konfigurationsavsnittet |
| Sampling-stöd (mindre viktigt i utvärdering) | ⛔ | Ej nämnt i dokumentationen |
Baserat på ovanstående är denna MCP-server väl dokumenterad för sina kärnfunktioner för InfluxDB-integrering. Den exponerar tydligt resurser och verktyg, inkluderar promptmallar och ger bra vägledning för installation. Dock är avancerade MCP-funktioner som roots och sampling inte dokumenterade, vilket något begränsar dess utbyggbarhet för vissa arbetsflöden.
Detta är en robust, praktisk MCP-server för InfluxDB med tydlig nytta för tidsseriedata och automatiseringsuppgifter. Den får höga betyg för praktisk användning för utvecklare, även om dokumentation om avancerade MCP-funktioner saknas.
| Har LICENS | ✅ (MIT) |
|---|---|
| Har minst ett verktyg | ✅ |
| Antal forks | 6 |
| Antal stjärnor | 13 |
Den kopplar samman FlowHunt (eller andra AI-assistenter) med en InfluxDB-databas och låter dig fråga, skriva och hantera tidsseriedata via ett standardiserat MCP-gränssnitt—vilket möjliggör analys, automatisering och förbättrade arbetsflöden.
Den exponerar organisationer, buckets, bucket measurements och stödjer direkta Flux-frågor. Verktyg inkluderar att skriva data (line protocol), fråga data, skapa buckets och skapa organisationer.
Använd verktyget 'write-data' för automatiserad inmatning med line protocol, eller verktyget 'query-data' för avancerade Flux-frågor—allt tillgängligt via FlowHunt-flöden.
Ja, du bör använda miljövariabler för att lagra API-tokens eller hemligheter, så att inloggningsuppgifter aldrig hårdkodas i konfigurationsfiler.
AI-drivna tidsserieanalyser, automatiserade IoT-telemetripipelines, databashantering för organisationer/buckets och dynamisk datautforskning—allting i FlowHunt.
Roots och sampling är för närvarande inte dokumenterade för denna server, men alla kärnfunktioner för InfluxDB-integrering stöds robust.
Snowflake MCP-server möjliggör sömlös AI-driven interaktion med Snowflake-databaser genom att exponera avancerade verktyg och resurser via Model Context Protoco...

GibsonAI MCP-servern kopplar AI-assistenter till dina GibsonAI-projekt och databaser, vilket möjliggör hantering av scheman, frågor, driftsättningar och mer med...
iFlytek Workflow MCP-server integrerar AI-assistenter med iFlyteks plattform för arbetsflödesautomation och möjliggör smidig schemaläggning, orkestrering och kö...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.