Những Giải Pháp Thay Thế Browse AI Tốt Nhất Năm 2026: So Sánh 8 Công Cụ Web Scraping
Đang tìm kiếm các giải pháp thay thế Browse AI? Chúng tôi đã so sánh 8 công cụ web scraping và trích xuất dữ liệu — từ các scraper được hỗ trợ AI đến các nền tảng tự động hóa đầy đủ — để tìm ra giải pháp phù hợp nhất.
Web Scraping
Browse AI
Alternatives
Data Extraction
Browse AI là một trong những công cụ web scraping không có mã phổ biến nhất trên thị trường — chỉ vào một trang web, nhấp vào dữ liệu bạn muốn và nó trích xuất và giám sát nó tự động. Nhưng nó có những khoảng trống có ý nghĩa: tự động hóa hạ lưu hạn chế, giá dựa trên tín chỉ trở nên đắt tiền ở quy mô và một câu chuyện tích hợp dừng lại ở xuất CSV và webhook cơ bản.
Nếu bạn đang tìm kiếm các giải pháp thay thế Browse AI — cho dù vì bạn đã vượt qua nó, chạm vào tường giá hoặc cần dữ liệu được scrape để thực sự làm gì — hướng dẫn này bao gồm tám công cụ đáng được đánh giá.
Câu trả lời nhanh:FlowHunt
là giải pháp thay thế tốt nhất nếu bạn muốn scraping cộng với hành động hạ lưu tự động. Apify chiến thắng cho crawling quy mô doanh nghiệp. Octoparse là giải pháp thay thế không có mã dễ nhất cho người dùng không kỹ thuật.
Browse AI là một nền tảng trích xuất dữ liệu web không có mã được ra mắt vào năm 2021 và nhanh chóng trở nên phổ biến vì cách tiếp cận kéo và nhấp dễ tiếp cận của nó. Thay vì viết mã hoặc bộ chọn XPath, bạn cài đặt tiện ích Chrome, điều hướng đến một trang web, nhấp vào các điểm dữ liệu bạn muốn trích xuất và Browse AI xử lý phần còn lại — bao gồm lên lịch trích xuất định kỳ và giám sát các trang để tìm kiếm thay đổi.
Các trường hợp sử dụng Browse AI phổ biến bao gồm giám sát giá cạnh tranh, trích xuất danh mục sản phẩm, tổng hợp danh sách công việc, bộ sưu tập danh sách bất động sản và tạo khách hàng tiềm năng từ các thư mục kinh doanh.
Nơi Browse AI bị thiếu:
Tự động hóa nông cạn. Browse AI trích xuất dữ liệu vào một bảng hoặc CSV, nhưng làm gì đó với dữ liệu đó — làm giàu nó, định tuyến nó, kích hoạt quy trình làm việc tiếp theo — yêu cầu các công cụ riêng biệt.
Giá dựa trên tín chỉ không mở rộng tốt. Các trang phức tạp với nhiều hàng tiêu thụ nhiều tín chỉ, đẩy chi phí lên nhanh chóng cho các trường hợp sử dụng khối lượng cao.
Suy luận AI hạn chế. Browse AI sử dụng AI để xác định các trường dữ liệu, nhưng nó không thể thông minh giải thích hoặc thực hiện hành động trên dữ liệu nó thu thập.
Độ sâu tích hợp. Kết nối với các công cụ hạ lưu (CRM, cơ sở dữ liệu, nền tảng tự động hóa) bị giới hạn so với các công cụ tự động hóa quy trình làm việc chuyên dụng.
Sẵn sàng phát triển doanh nghiệp của bạn?
Bắt đầu dùng thử miễn phí ngay hôm nay và xem kết quả trong vài ngày.
1. FlowHunt — Tốt Nhất Cho Scraping + Tự Động Hóa Đầu Cuối
FlowHunt
sử dụng một cách tiếp cận khác nhau đối với vấn đề web scraping: thay vì coi trích xuất như một bước riêng biệt, nó nhúng web scraping trực tiếp vào các quy trình tự động hóa được hỗ trợ AI. Bạn có thể scrape một trang, có một AI agent giải thích dữ liệu, làm giàu nó bằng các nguồn bổ sung và đẩy nó đến CRM của bạn — tất cả trong một quy trình trực quan duy nhất.
Nơi Browse AI kết thúc ở trích xuất dữ liệu, FlowHunt tiếp tục: các AI agent có thể đọc nội dung được scrape, đưa ra quyết định về nó và kích hoạt các hành động trên hơn 1.400 công cụ được kết nối. Điều này làm cho FlowHunt phù hợp duy nhất cho các trường hợp sử dụng nơi dữ liệu được scrape cung cấp một quy trình kinh doanh thay vì chỉ hạ cánh trong một bảng tính.
Quy trình ví dụ: Scrape một trang web danh sách công việc cho các bài đăng mới → AI agent trích xuất tên công ty, vai trò và yêu cầu → làm giàu với dữ liệu công ty từ LinkedIn → định tuyến các khách hàng tiềm năng đủ tiêu chuẩn đến HubSpot → thông báo cho nhóm qua Slack.
Giá: Tầng miễn phí có sẵn. Giá dựa trên mức sử dụng mở rộng với các chạy quy trình thực tế — thanh toán cho AI và tự động hóa bạn sử dụng, không phải ghế hoặc giới hạn trang cố định.
Các tính năng chính:
Trình tạo quy trình trực quan kết hợp web scraping, xử lý AI và các hành động hạ lưu
Các AI agent giải thích và thực hiện hành động trên nội dung được scrape thông qua ngôn ngữ tự nhiên
Hơn 1.400 tích hợp gốc bao gồm CRM, bảng tính và công cụ nhắn tin
Các quy trình agent đa bước cho các quy trình làm giàu dữ liệu phức tạp
Không cơ sở hạ tầng để quản lý — hoàn toàn được lưu trữ và tự động mở rộng
Hỗ trợ thực thi quy trình theo lịch, được kích hoạt và theo yêu cầu
Ưu điểm: Kết hợp web scraping với tự động hóa hạ lưu đầy đủ trong một canvas trực quan; các AI agent có thể giải thích, làm giàu và thực hiện hành động trên dữ liệu được scrape; hơn 1.400 tích hợp — không có dữ liệu bị kẹt trong CSV; trình tạo quy trình trực quan — không cần mã; hỗ trợ đa agent cho các quy trình dữ liệu đa bước phức tạp
Nhược điểm: Không được xây dựng theo mục đích như một công cụ scraping — yêu cầu cấu hình quy trình; chọn phần tử kéo và thả ít được phát triển hơn tiện ích Chrome của Browse AI
Tốt nhất cho: Các nhóm cần trích xuất dữ liệu web và ngay lập tức thực hiện hành động trên nó — làm giàu khách hàng tiềm năng, kích hoạt quy trình hoặc cung cấp cho các AI agent — thay vì chỉ lưu trữ nó trong một bảng tính.
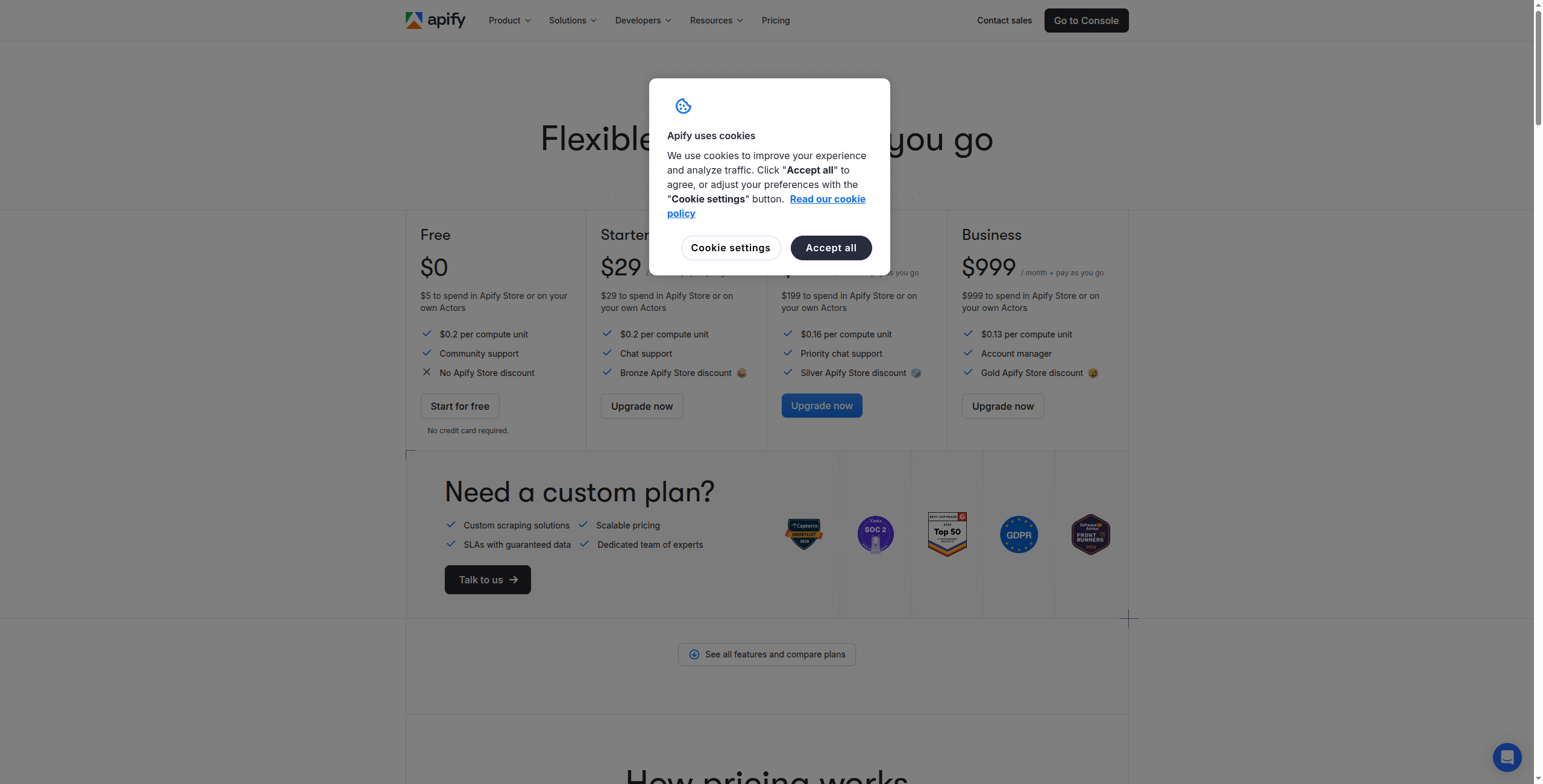
2. Apify — Tốt Nhất Cho Scraping Quy Mô Doanh Nghiệp
Apify là nền tảng web scraping mạnh mẽ nhất có sẵn, được xây dựng cho các nhóm cần crawl hàng triệu trang, xử lý các biện pháp chống bot và duy trì các hoạt động scraping phức tạp ở quy mô. Thị trường của nó gồm hơn 1.500 “Actors” sẵn sàng sử dụng (scraper được xây dựng trước) có nghĩa là bạn thường có thể tìm thấy một scraper hoạt động cho trang đích của bạn mà không cần viết bất kỳ mã nào.
Giá:
Miễn phí — $5 tín chỉ nền tảng/tháng, truy cập vào tất cả Actors, hỗ trợ cộng đồng
Starter — $49/tháng. $49 tín chỉ nền tảng, 1 chạy Actor đồng thời, proxy tiêu chuẩn
Scale — $499/tháng. $499 tín chỉ nền tảng, 10 chạy đồng thời, proxy cao cấp, hỗ trợ ưu tiên
Business — $999/tháng. $999 tín chỉ nền tảng, 20 chạy đồng thời, hỗ trợ chuyên dụng, tùy chọn SLA
Enterprise — Liên hệ bộ phận bán hàng để phân bổ tín chỉ tùy chỉnh, Actors riêng tư và cơ sở hạ tầng chuyên dụng
Các tính năng chính:
Hơn 1.500 Actors thị trường bao gồm Amazon, LinkedIn, Google Maps, mạng xã hội và hơn thế nữa
Apify SDK (JavaScript/Python) để xây dựng scrapers hoàn toàn tùy chỉnh
Hỗ trợ trình duyệt headless (Playwright, Puppeteer) cho các trang nặng JavaScript
Quản lý proxy tích hợp với xoay IP dân cư và trung tâm dữ liệu
Chạy Actor được lên lịch, được kích hoạt sự kiện và được kích hoạt webhook
Kho dữ liệu và kho cặp khóa-giá trị cho lưu trữ và truy xuất kết quả có cấu trúc
Ưu điểm: Hơn 1.500 Actors thị trường để triển khai tức thì trên các trang phổ biến; xử lý kết xuất JavaScript, giải CAPTCHA và xoay proxy; mở rộng từ sử dụng cá nhân đến cơ sở hạ tầng crawling cấp doanh nghiệp; SDK JavaScript cho phát triển scraper tùy chỉnh; tầng miễn phí hào phóng ($5 tín chỉ nền tảng mỗi tháng)
Nhược điểm: Kỹ thuật hơn Browse AI cho các trường hợp sử dụng tùy chỉnh; chất lượng Actor thay đổi — danh sách thị trường không phải tất cả được duy trì bằng nhau; chi phí mở rộng với thời gian tính toán, không chỉ số lượng hàng
Tốt nhất cho: Các nhóm phát triển và doanh nghiệp cần các hoạt động crawling quy mô lớn, phát triển scraper tùy chỉnh hoặc một thị trường phong phú của scrapers được xây dựng trước cho các trang web phổ biến.
Tham gia bản tin của chúng tôi
Nhận các mẹo, xu hướng và ưu đãi mới nhất miễn phí.
3. Firecrawl — Tốt Nhất Cho Các Quy Trình AI và LLM
Firecrawl là một API web crawling tập trung vào nhà phát triển được xây dựng theo mục đích cho các ứng dụng AI. Nó chuyển đổi các trang web — bao gồm các trang được hiển thị bằng JavaScript — thành markdown có cấu trúc sạch sẽ mà các LLM có thể trực tiếp tiêu thụ. Nếu bạn đang xây dựng một AI agent, quy trình RAG hoặc ứng dụng LLM cần dữ liệu web tươi, Firecrawl là tùy chọn được xây dựng theo mục đích nhất.
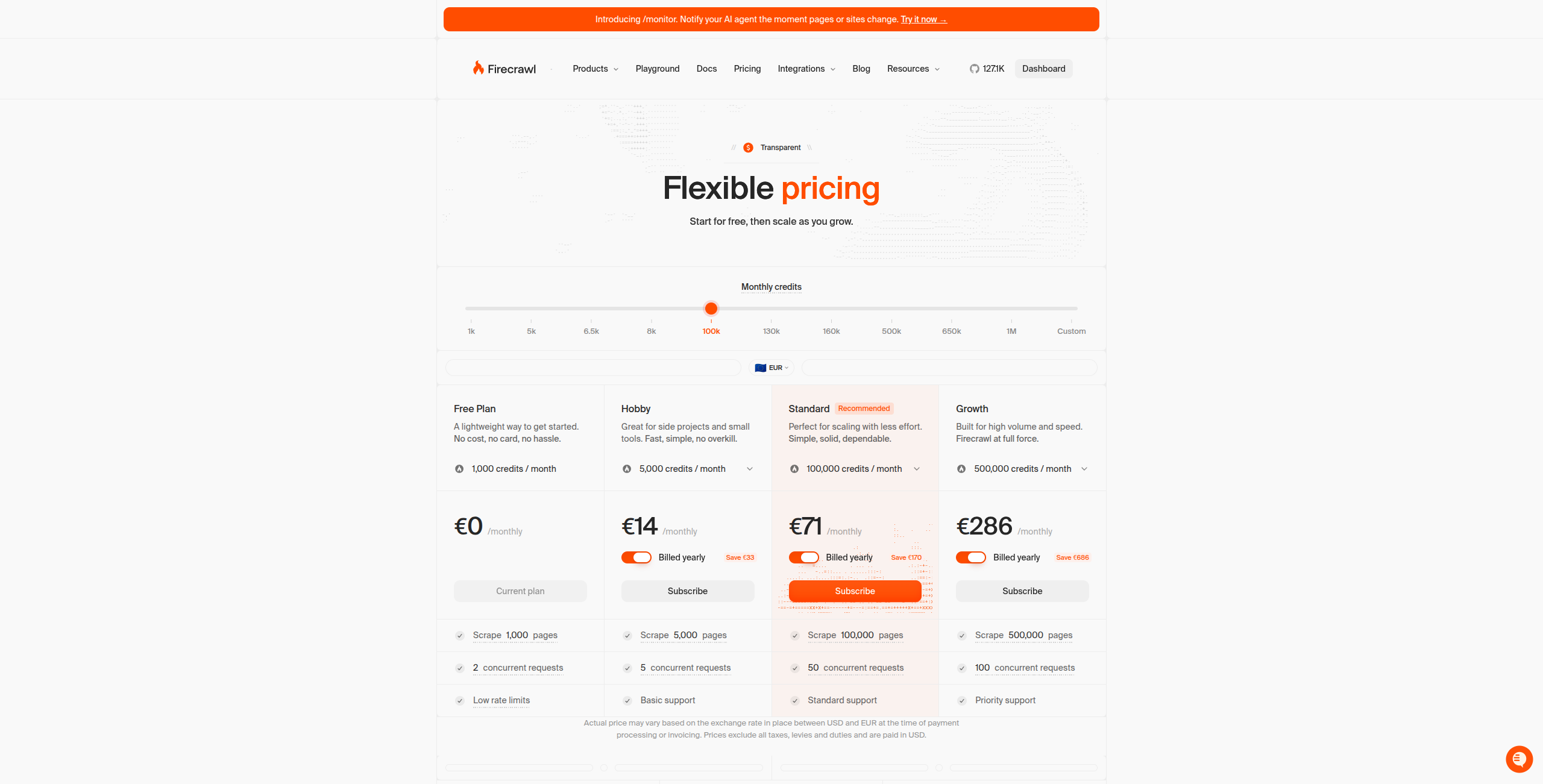
Giá:
Miễn phí — 500 tín chỉ/tháng, lên đến 500 trang được scrape, truy cập API đầy đủ
Hobby — $16/tháng. 3.000 tín chỉ/tháng, giới hạn tỷ lệ cao hơn, hỗ trợ cơ bản
Standard — $83/tháng. 100.000 tín chỉ/tháng, giới hạn tỷ lệ ưu tiên, hỗ trợ email
Growth — $333/tháng. 500.000 tín chỉ/tháng, hỗ trợ chuyên dụng, các tính năng nâng cao
Enterprise — Liên hệ bộ phận bán hàng để có khối lượng tùy chỉnh, triển khai tại chỗ và SLA
Các tính năng chính:
Scrape endpoint: chuyển đổi bất kỳ URL nào thành markdown sẵn sàng cho LLM sạch sẽ trong một lệnh gọi API
Crawl endpoint: recursively crawls toàn bộ trang web với khám phá sitemap
Extract endpoint: kéo dữ liệu có cấu trúc khớp với lược đồ JSON được xác định
Search endpoint: tìm kiếm web được hỗ trợ AI trả về kết quả markdown sạch sẽ
Kết xuất JavaScript cho SPA và nội dung động
SDK cho Python, Node.js, Go và Rust với tích hợp đơn giản
Ưu điểm: Markdown sạch sẽ được tối ưu hóa cho tiêu thụ LLM; xử lý kết xuất JS, xác thực và nội dung động; REST API đơn giản — dễ dàng tích hợp vào bất kỳ ngăn xếp nào; tầng miễn phí có sẵn để phát triển và thử nghiệm
Nhược điểm: API nhà phát triển duy nhất — không có giao diện không có mã; không được thiết kế cho tự phục vụ người dùng kinh doanh; không có lên lịch hoặc giám sát tích hợp (mang theo cách sắp xếp của riêng bạn)
Tốt nhất cho: Các nhà phát triển xây dựng các AI agent, cơ sở kiến thức RAG hoặc các ứng dụng LLM cần nội dung web chính xác và sạch sẽ làm dữ liệu đầu vào.
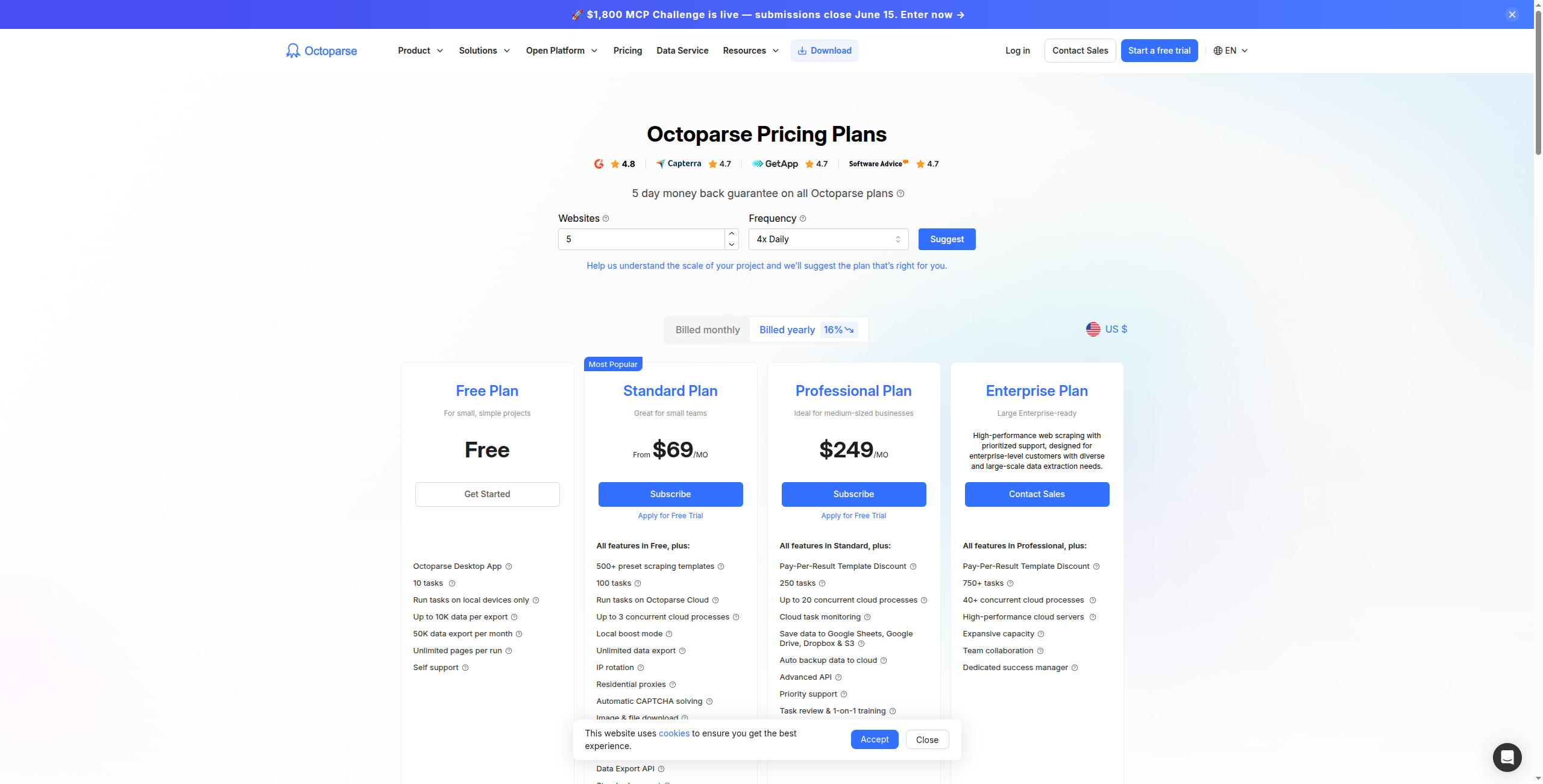
4. Octoparse — Giải Pháp Thay Thế Không Có Mã Tốt Nhất Cho Người Dùng Không Kỹ Thuật
Octoparse là công cụ web scraping không có mã được thiết lập lâu nhất trên thị trường, tiền thân Browse AI bằng vài năm. Giao diện kéo và thả trực quan của nó cho phép người dùng không kỹ thuật xây dựng scrapers cho các trang web phức tạp, được phân trang và nặng JavaScript. Trích xuất dựa trên đám mây chạy scrapers theo lịch mà không cần bật máy tính của bạn.
Giá:
Miễn phí — Scraping cục bộ duy nhất, giới hạn ở 10.000 bản ghi trên mỗi xuất, không chạy đám mây
Standard — $75/tháng. Scraping đám mây, 10 tác vụ đám mây đồng thời, lên lịch, truy cập API
Professional — $149/tháng. 30 tác vụ đám mây đồng thời, xoay IP, thực thi đám mây nhanh hơn, hỗ trợ ưu tiên
Enterprise — Liên hệ bộ phận bán hàng. Tác vụ không giới hạn, máy chủ chuyên dụng, tích hợp tùy chỉnh và SLA
Các tính năng chính:
Trình tạo quy trình kéo và thả trực quan — không cần mã hoặc bộ chọn CSS
Xử lý phân trang, cuộn vô hạn, trang được bảo vệ bằng đăng nhập và điều hướng thả xuống
Scraping đám mây với lên lịch và chạy lại tự động khi thất bại
Tính năng tự động phát hiện để tạo mẫu nhanh chóng từ bố cục trang phổ biến
Hơn 1.000 mẫu được xây dựng trước cho thương mại điện tử, bất động sản, công việc và hơn thế nữa
Xuất sang Excel, CSV, Google Sheets, MySQL, SQL Server và qua API
Ưu điểm: Scraper trực quan không có mã trưởng thành với các mẫu mở rộng; xử lý phân trang, trang yêu cầu đăng nhập và cuộn vô hạn; trích xuất đám mây và lên lịch bao gồm; xuất sang Excel, CSV, cơ sở dữ liệu và API
Nhược điểm: Giao diện cảm thấy lỗi thời so với Browse AI; giá cao hơn Browse AI ở khối lượng trích xuất tương đương; không có giải thích dữ liệu được trích xuất bằng AI
Tốt nhất cho: Người dùng kinh doanh không kỹ thuật và nhà phân tích cần một công cụ scraping đáng tin cậy, tự phục vụ cho dữ liệu được cập nhật thường xuyên từ các trang web phức tạp.
5. Clay — Tốt Nhất Cho Làm Giàu Khách Hàng Tiềm Năng và Tìm Kiếm Khách Hàng Tiềm Năng
Clay lấy web scraping theo một hướng cụ thể: xây dựng và làm giàu danh sách khách hàng tiềm năng. Nó kéo từ hơn 50 nguồn dữ liệu (LinkedIn, Apollo, Clearbit và hơn thế nữa) cùng với web scraping để cho phép các nhóm bán hàng và tăng trưởng xây dựng danh sách khách hàng tiềm năng được nhắm mục tiêu cao với dữ liệu liên hệ được làm giàu. Nếu Browse AI là nguồn khách hàng tiềm năng B2B của bạn, Clay là bản nâng cấp được xây dựng theo mục đích.
Giá:
Miễn phí — 100 tín chỉ/tháng, truy cập vào các nguồn dữ liệu cơ bản, làm giàu thủ công
Starter — $149/tháng. 2.000 tín chỉ/tháng, truy cập vào tất cả hơn 50 nhà cung cấp dữ liệu, đẩy CRM cơ bản
Explorer — $349/tháng. 10.000 tín chỉ/tháng, các AI research agent, làm giàu nâng cao
Pro — $800/tháng. 50.000 tín chỉ/tháng, khả năng AI agent đầy đủ, hỗ trợ ưu tiên
Enterprise — Liên hệ bộ phận bán hàng để có khối lượng tín chỉ tùy chỉnh, SSO, onboarding chuyên dụng và SLA
Các tính năng chính:
Hơn 50 nguồn dữ liệu tích hợp để làm giàu liên hệ và công ty (LinkedIn, Apollo, Clearbit, Hunter.io và hơn thế nữa)
AI research agent duyệt web và viết outreach được cá nhân hóa dựa trên nghiên cứu
Làm giàu thác nước — cố gắng nhiều nhà cung cấp liên tiếp để tối đa hóa độ phủ dữ liệu
Giao diện kiểu bảng tính quen thuộc với người dùng bán hàng và tiếp thị không kỹ thuật
Đẩy CRM gốc sang HubSpot, Salesforce và các công cụ bán hàng khác
Xây dựng danh sách tự động từ bảng công việc, tìm kiếm LinkedIn và thư mục công ty
Ưu điểm: Hơn 50 nguồn dữ liệu để làm giàu liên hệ và công ty; nghiên cứu được hỗ trợ AI cá nhân hóa từng hàng; tích hợp CRM gốc (HubSpot, Salesforce); được thiết kế cho các nhóm bán hàng — giao diện kiểu bảng tính trực quan
Nhược điểm: Không phải scraper mục đích chung — tập trung chặt chẽ vào tạo khách hàng tiềm năng; giá dựa trên tín chỉ có thể tốn kém cho danh sách lớn; kém hiệu quả cho các trường hợp sử dụng scraping không phải tạo khách hàng tiềm năng
Tốt nhất cho: Các nhóm bán hàng và tăng trưởng xây dựng danh sách outbound được nhắm mục tiêu và làm giàu hồ sơ CRM bằng dữ liệu liên hệ và công ty được xác minh.
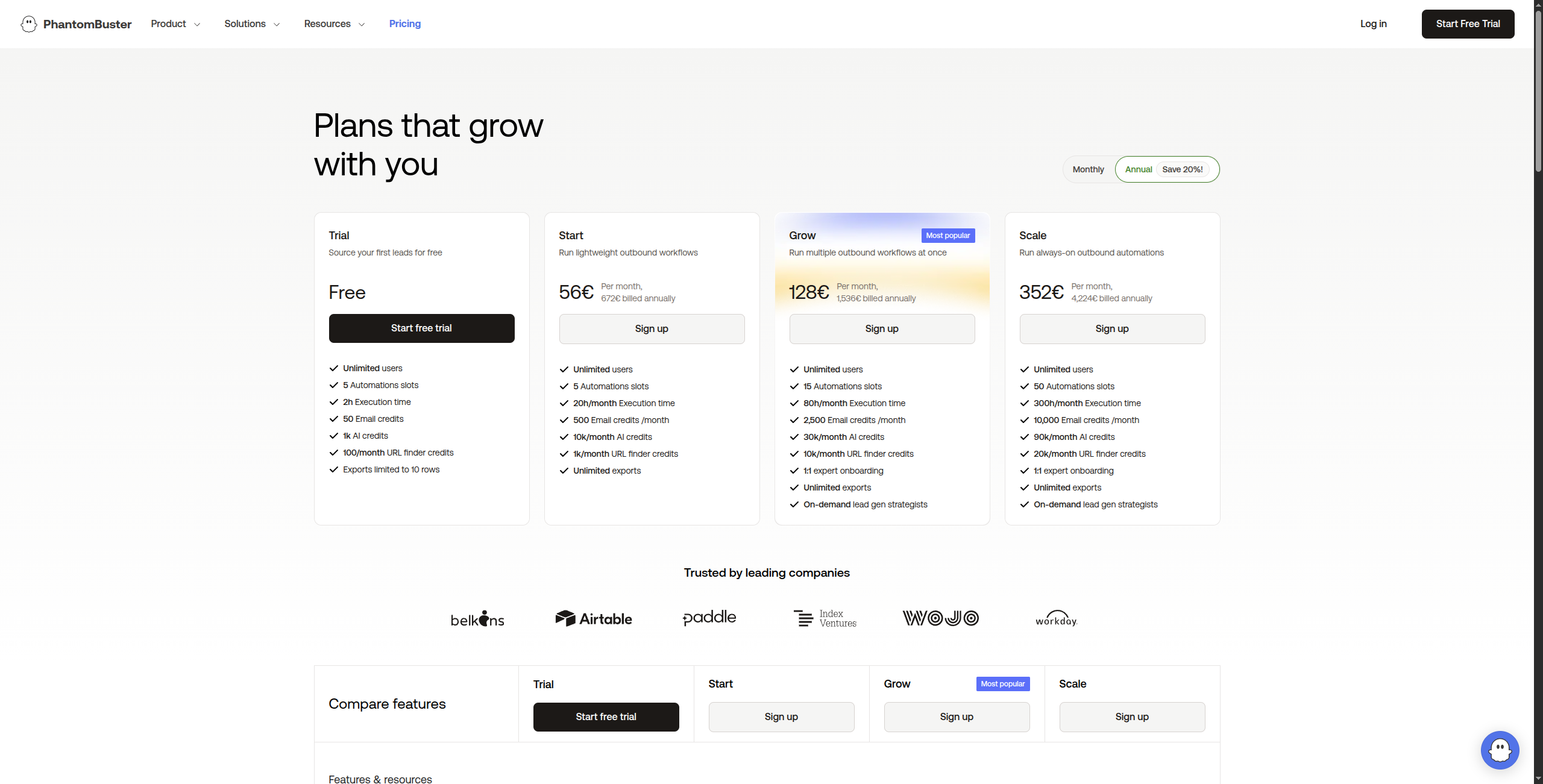
6. PhantomBuster — Tốt Nhất Cho Trích Xuất LinkedIn và Mạng Xã Hội
PhantomBuster là công cụ để trích xuất dữ liệu LinkedIn: scraping hồ sơ, trang công ty, tương tác bài đăng, kết quả Trình điều hướng Bán hàng và hơn thế nữa. Nó cũng bao gồm Twitter/X, Instagram và các nền tảng xã hội khác. Nếu các trường hợp sử dụng Browse AI của bạn là trung tâm mạng xã hội, PhantomBuster xử lý chúng tốt hơn.
Giá:
Dùng thử miễn phí — 14 ngày truy cập đầy đủ
Starter — $56/tháng. 20 giờ thời gian thực thi/tháng, 5 Phantoms đồng thời, hỗ trợ email
Pro — $128/tháng. 80 giờ thời gian thực thi/tháng, 15 Phantoms đồng thời, hỗ trợ ưu tiên
Team — $352/tháng. 300 giờ thời gian thực thi/tháng, Phantoms đồng thời không giới hạn, hỗ trợ chuyên dụng
Enterprise — Liên hệ bộ phận bán hàng để có thời gian thực thi tùy chỉnh, quản lý ghế nhiều và cơ sở hạ tầng chuyên dụng
Các tính năng chính:
Hơn 100 Phantoms được xây dựng trước cho LinkedIn, Twitter/X, Instagram, Facebook, Google Maps và hơn thế nữa
Scraping LinkedIn: hồ sơ, trang công ty, kết quả Trình điều hướng Bán hàng, người tham dự sự kiện, thích bài đăng
Tự động hóa yêu cầu kết nối và nhắn tin với giới hạn hàng ngày có thể cấu hình
Chạy theo lịch với cài đặt điều chỉnh để giảm nguy hiểm phát hiện nền tảng
Xuất sang CSV, Google Sheets và đẩy CRM trực tiếp qua webhook
Hỗ trợ tài khoản nhiều để quản lý nhiều hồ sơ xã hội
Ưu điểm: Công cụ tự động hóa và trích xuất LinkedIn tốt nhất có sẵn; loạt Phantoms được xây dựng trước rộng cho các nền tảng xã hội; tích hợp CRM tốt cho đẩy khách hàng tiềm năng trực tiếp; giá hợp lý cho các khả năng
Nhược điểm: Nguy hiểm tuân thủ ToS nền tảng xã hội — LinkedIn tích cực giới hạn scraping; không phù hợp cho scraping trang web chung; khả năng AI bị hạn chế
Tốt nhất cho: Các nhóm bán hàng và nhà tuyển dụng cần trích xuất và tự động hóa các hành động trên LinkedIn và các nền tảng xã hội cho tạo khách hàng tiềm năng và các chiến dịch outreach.
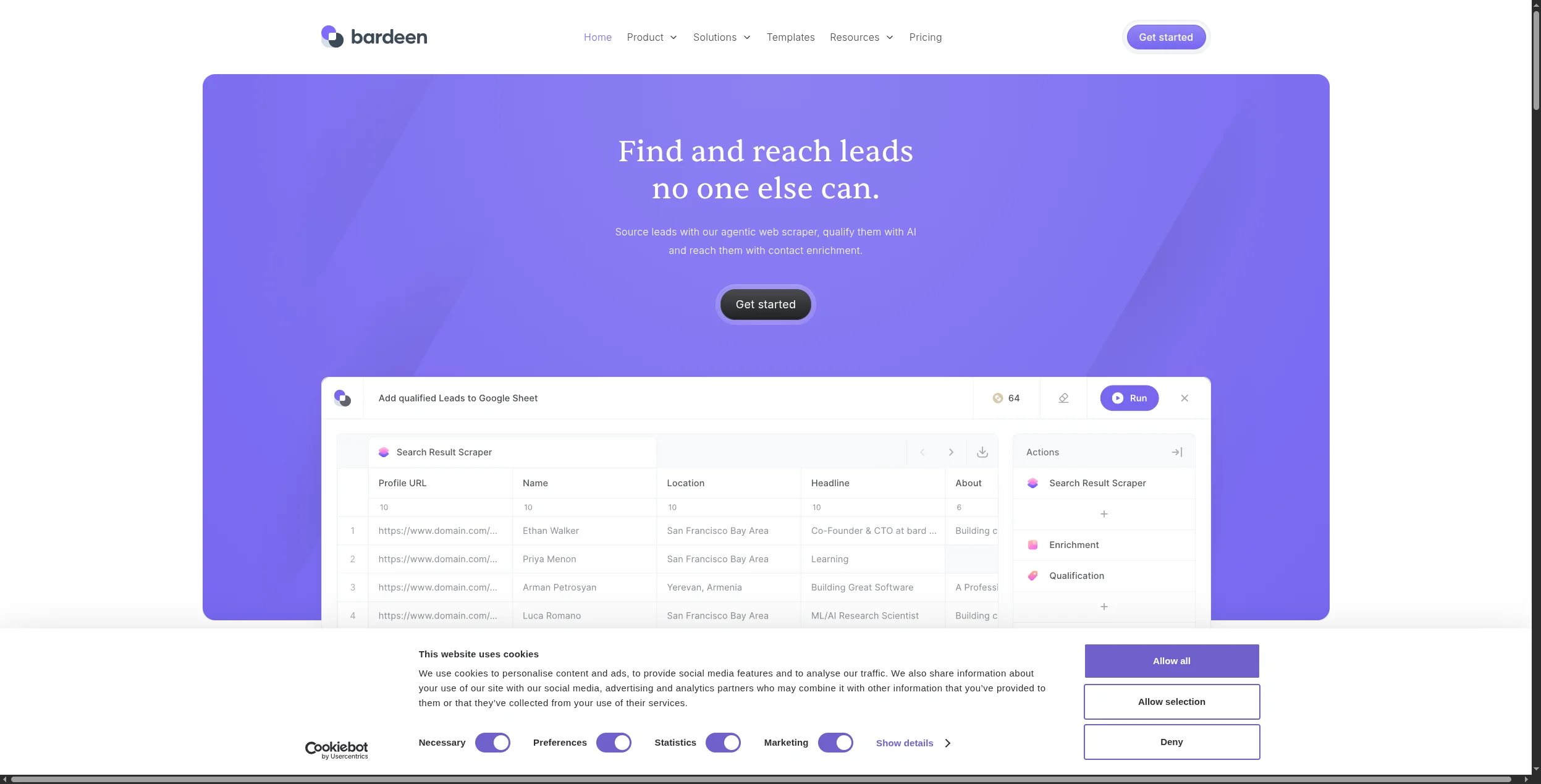
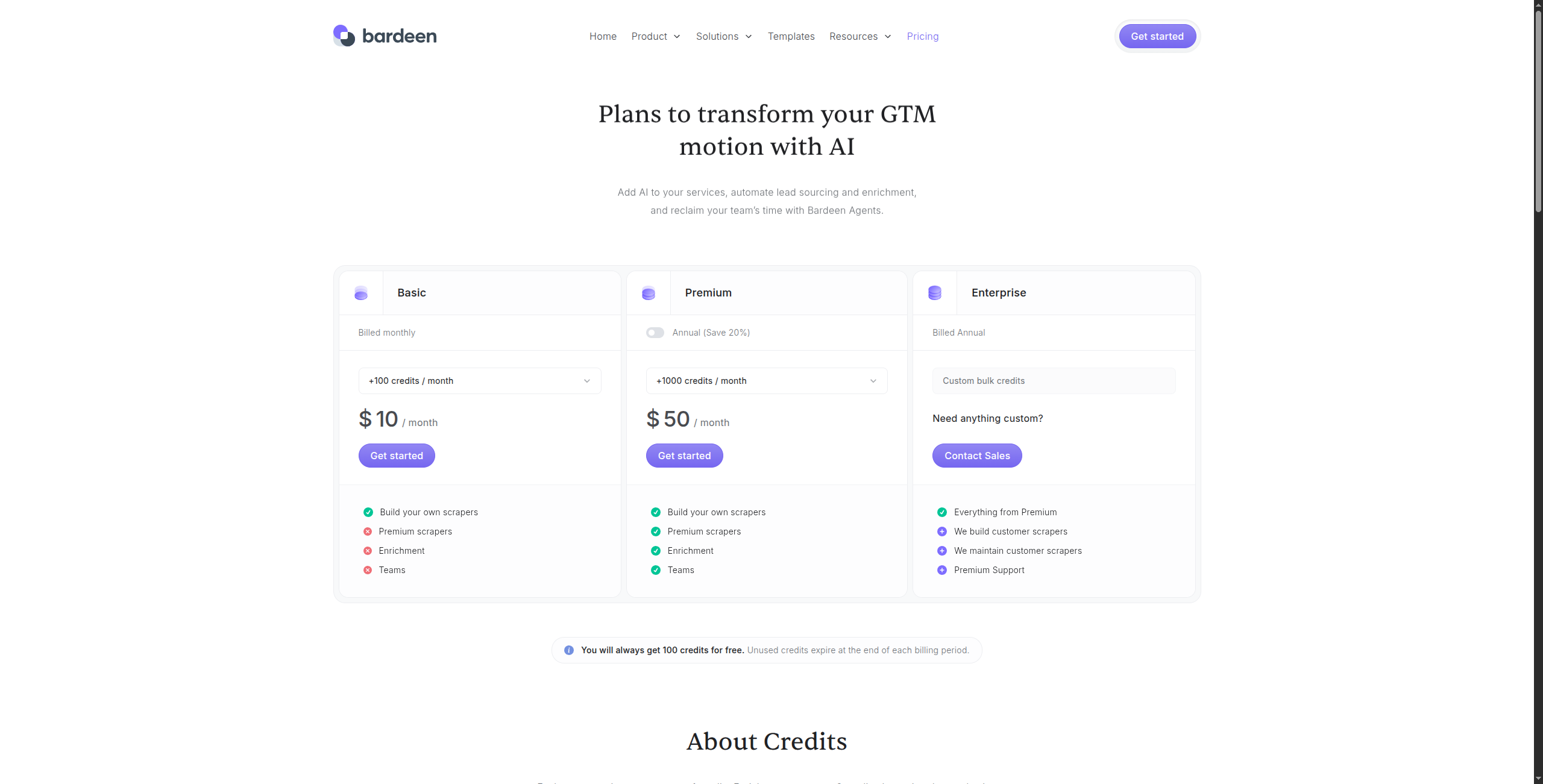
7. Bardeen — Tốt Nhất Cho Scraping Dựa Trên Trình Duyệt Với AI
Bardeen hoạt động như một tiện ích Chrome kết hợp scraping, xử lý AI và tích hợp ứng dụng trong giao diện dựa trên trình duyệt. AI của nó có thể giải thích nội dung trang và trích xuất dữ liệu có cấu trúc ngay cả khi cấu trúc trang không hoàn toàn nhất quán — làm cho nó có khả năng phục hồi hơn các scraper dựa trên quy tắc cho các trang thay đổi thường xuyên.
Giá:
Miễn phí — Chạy thủ công không giới hạn, tích hợp cơ bản, hỗ trợ cộng đồng
Professional — $10/tháng. Chạy tự động không giới hạn, tích hợp cao cấp, lưu trữ đám mây cho dữ liệu được scrape
Business — $15/người dùng/tháng. Chia sẻ nhóm, thư viện tự động hóa chia sẻ, kiểm soát quản trị viên
Enterprise — Liên hệ bộ phận bán hàng để có SSO, bảo mật nâng cao và tích hợp tùy chỉnh
Các tính năng chính:
AI Magic Actions — mô tả những gì cần trích xuất bằng tiếng Anh thuần túy, không cần bộ chọn
Ghi âm và phát lại quy trình làm việc trình duyệt để tự động hóa có thể lặp lại
Thích ứng AI thời gian thực khi cấu trúc trang thay đổi
Tích hợp với hơn 100 ứng dụng: Notion, Airtable, HubSpot, Salesforce, Google Sheets, Slack
Tự động hóa dựa trên kích hoạt (dựa trên thời gian, thay đổi URL, webhook hoặc thủ công)
Scrapes bảng, danh sách và các phần tử có cấu trúc từ bất kỳ trang nào mà người dùng có thể truy cập
Ưu điểm: Trích xuất được hỗ trợ AI thích ứng với các thay đổi cấu trúc trang; dựa trên trình duyệt — hoạt động trên bất kỳ trang nào bạn có thể duyệt thủ công; kết hợp scraping với tự động hóa quy trình trong một công cụ; tích hợp tốt với CRM và công cụ năng suất
Nhược điểm: Chỉ Chrome — không có thực thi phía máy chủ hoặc headless; không phù hợp cho scraping quy mô lớn hoặc được lên lịch ở nền; tầng miễn phí giới hạn số hành động mỗi tháng
Tốt nhất cho: Các nhà nghiên cứu cá nhân, đại diện bán hàng và các nhóm nhỏ cần tự động hóa các tác vụ nghiên cứu dựa trên trình duyệt lặp lại và thu thập dữ liệu với hỗ trợ AI.
8. ScraperAPI — Tốt Nhất Cho Các Nhà Phát Triển Cần HTML Đáng Tin Cậy Ở Quy Mô
ScraperAPI là dịch vụ proxy và kết xuất cho các nhà phát triển HTML thô đáng tin cậy từ bất kỳ trang web nào ở quy mô. Nó xử lý xoay proxy, giải CAPTCHA, kết xuất trình duyệt và nhắm mục tiêu địa lý thông qua một lệnh gọi API duy nhất. Nếu bạn là một nhà phát triển viết logic phân tích cú pháp của riêng bạn nhưng cần cơ sở hạ tầng đáng tin cậy, ScraperAPI loại bỏ các vấn đề cơ sở hạ tầng khó nhất.
Giá:
Miễn phí — 1.000 lệnh gọi API/tháng, lên đến 5 yêu cầu đồng thời
Hobby — $49/tháng. 100.000 lệnh gọi API, 10 yêu cầu đồng thời, kết xuất JS bao gồm
Startup — $149/tháng. 1.000.000 lệnh gọi API, 25 yêu cầu đồng thời, proxy cao cấp
Business — $299/tháng. 3.000.000 lệnh gọi API, 50 yêu cầu đồng thời, quản lý tài khoản chuyên dụng
Enterprise — Liên hệ bộ phận bán hàng để có khối lượng tùy chỉnh, proxy chuyên dụng và SLA
Các tính năng chính:
Lệnh gọi API duy nhất trả về HTML được kết xuất đầy đủ từ bất kỳ URL nào
Xoay proxy tự động với hơn 40 triệu IP dân cư và trung tâm dữ liệu
Kết xuất JavaScript qua Chrome headless cho SPA và trang động
Giải CAPTCHA và bỏ qua vân tay chống bot
Nhắm mục tiêu địa lý với chọn proxy cấp quốc gia và thành phố
Các điểm cuối API dữ liệu có cấu trúc cho Amazon, Google SERP, Walmart và hơn thế nữa
Ưu điểm: API đơn giản — một dòng mã để lấy HTML được kết xuất từ bất kỳ trang nào; quản lý proxy, CAPTCHA và vân tay trình duyệt tự động; giá cạnh tranh ở quy mô (mỗi lệnh gọi API); tầng miễn phí hào phóng (1.000 lệnh gọi/tháng)
Nhược điểm: Chỉ API — không có giao diện không có mã; bạn mang theo logic phân tích cú pháp của riêng bạn (không có trích xuất dữ liệu có cấu trúc tích hợp); không được thiết kế cho người dùng không kỹ thuật
Tốt nhất cho: Các nhà phát triển xây dựng scrapers tùy chỉnh hoặc quy trình dữ liệu cần một lớp kết xuất và proxy đáng tin cậy, có thể mở rộng mà không cần quản lý cơ sở hạ tầng của riêng họ.
Cách Chọn Giải Pháp Thay Thế Browse AI Phù Hợp
Bạn cần scraping + tự động hóa hạ lưu → FlowHunt. Nếu dữ liệu của bạn cần thực sự làm gì đó sau khi trích xuất — kích hoạt quy trình, cập nhật CRM, cung cấp cho AI agent — FlowHunt xử lý toàn bộ quy trình trong một canvas trực quan duy nhất.
Bạn cần crawling quy mô doanh nghiệp → Apify. Không có gì phù hợp với Apify cho các hoạt động crawl quy mô lớn, phức tạp với một thị trường phong phú của scrapers được xây dựng trước.
Bạn đang xây dựng một ứng dụng AI/LLM → Firecrawl. API sạch sẽ nhất để cung cấp dữ liệu web cho các mô hình ngôn ngữ.
Bạn là người dùng không kỹ thuật muốn đơn giản hóa Browse AI → Octoparse. Scraper không có mã trưởng thành nhất với một hồ sơ theo dõi lâu dài.
Trường hợp sử dụng của bạn là tạo khách hàng tiềm năng B2B → Clay. Được xây dựng theo mục đích để làm giàu và xây dựng danh sách khách hàng tiềm năng từ nhiều nguồn dữ liệu.
Trường hợp sử dụng của bạn là LinkedIn/mạng xã hội → PhantomBuster. Công cụ mạnh nhất trong khoảng cách cụ thể này.
Dòng Dưới Cùng
Browse AI lấp đầy một khoảng cách rõ ràng trên thị trường — web scraping không có mã với giao diện sạch sẽ — nhưng nó dừng lại ở trích xuất. Các công cụ ở trên đi xa hơn, cho dù điều đó có nghĩa là quy mô tốt hơn (Apify), tích hợp AI tốt hơn (FlowHunt, Firecrawl) hay tạo khách hàng tiềm năng tốt hơn (Clay, PhantomBuster).
Đối với các nhóm có mục tiêu thực sự không chỉ trích xuất dữ liệu mà hành động trên nó, FlowHunt
là giải pháp thay thế hoàn chỉnh nhất — biến những gì Browse AI làm trong sự cô lập thành bước đầu tiên của một quy trình hoàn toàn tự động.
Giải pháp thay thế Browse AI tốt nhất phụ thuộc vào trường hợp sử dụng của bạn. FlowHunt là lựa chọn tốt nhất nếu bạn cần scraping cộng với tự động hóa hạ lưu trong một quy trình duy nhất. Apify tốt hơn cho scraping quy mô doanh nghiệp với logic crawl phức tạp. Octoparse là tùy chọn không có mã hàng đầu cho người dùng không kỹ thuật. Đối với làm giàu khách hàng tiềm năng cụ thể, Clay được xây dựng theo mục đích.
Browse AI cung cấp một gói miễn phí với 50 tín chỉ mỗi tháng — đủ để kiểm tra nhẹ nhàng nhưng không phải sử dụng sản xuất. Các gói trả tiền bắt đầu từ $49/tháng cho 2.000 tín chỉ. Apify và Firecrawl đều cung cấp các tầng miễn phí với giới hạn cao hơn để sử dụng ban đầu.
Browse AI chủ yếu được sử dụng để web scraping không có mã: giám sát giá cạnh tranh, trích xuất dữ liệu sản phẩm từ các trang web thương mại điện tử, theo dõi danh sách công việc và thu thập dữ liệu khách hàng tiềm năng từ các thư mục. Nó cho phép người dùng không kỹ thuật kéo và nhấp để xác định dữ liệu cần trích xuất mà không cần viết mã.
Có, Browse AI có thể xử lý các trang được hiển thị bằng JavaScript vì nó sử dụng một trình duyệt thực để trích xuất. Tuy nhiên, nó có thể chậm hơn và tốn kém hơn cho scraping quy mô lớn nặng JS so với các công cụ nhà phát triển như Apify hoặc ScraperAPI, được tối ưu hóa để kết xuất trình duyệt ở quy mô.
Browse AI là một công cụ không có mã được thiết kế cho người dùng kinh doanh muốn trích xuất dữ liệu bằng cách nhấp vào một trang web. Apify là một nền tảng tập trung vào nhà phát triển với SDK JavaScript của riêng nó, thị trường hơn 1.500 scraper được xây dựng trước (được gọi là Actors) và cơ sở hạ tầng cấp doanh nghiệp cho các hoạt động scraping quy mô lớn. Browse AI đơn giản hơn để thiết lập; Apify mạnh hơn và mở rộng được.
Arshia là Kỹ sư Quy trình AI tại FlowHunt. Với nền tảng về khoa học máy tính và niềm đam mê AI, anh chuyên tạo ra các quy trình hiệu quả tích hợp công cụ AI vào các nhiệm vụ hàng ngày, nâng cao năng suất và sự sáng tạo.
Arshia Kahani
Kỹ sư Quy trình AI
Scrape Bất Kỳ Trang Web Nào Bằng AI — Thử FlowHunt Miễn Phí
Các AI agent của FlowHunt có thể scrape, trích xuất và thực hiện hành động trên dữ liệu web trong một quy trình duy nhất — không cần công cụ scraping riêng biệt. Kết nối với hơn 1.400 ứng dụng và tự động hóa toàn bộ quy trình.
10 Công Cụ Cạo Dữ Liệu Web Tốt Nhất Năm 2026: Xếp Hạng và Đánh Giá
10 công cụ cạo dữ liệu web AI tốt nhất năm 2026, xếp hạng theo độ chính xác trích xuất, dễ sử dụng, xử lý chống bot và giá cả. Tìm công cụ cạo dữ liệu AI phù hợ...
8 Lựa Chọn Thay Thế Apify Tốt Nhất Năm 2026 (Quét Web & Trích Xuất Dữ Liệu)
Apify mạnh mẽ nhưng phức tạp và đắt đỏ cho hầu hết các trường hợp sử dụng. Chúng tôi đã so sánh 8 lựa chọn thay thế Apify để quét web và trích xuất dữ liệu — từ...
Tích hợp FlowHunt với Máy chủ Browserbase MCP để kích hoạt tự động hóa trình duyệt bằng AI, trích xuất dữ liệu, chụp ảnh màn hình và tương tác web đa phiên thôn...
6 phút đọc
AI
Browser Automation
+4
Đồng Ý Cookie Chúng tôi sử dụng cookie để cải thiện trải nghiệm duyệt web của bạn và phân tích lưu lượng truy cập của mình. See our privacy policy.