Få LLM’er til at faktatjekke deres svar og inkludere kilder
Opdag, hvordan du bygger chatbots med Retrieval Interleaved Generation (RIG) for at sikre, at AI-svar er nøjagtige, faktatjekkede og inkluderer verificerbare kilder.
AI
Chatbot
Fact-Checking
RIG
RAG
Knowledge Retrieval
Machine Learning
Retrieval Interleaved Generation, eller RIG, er en banebrydende AI-metode, der gnidningsfrit kombinerer informationssøgning og oprettelse af svar. Tidligere brugte AI-modeller RAG (Retrieval Augmented Generation) eller generering, men RIG sammensmelter disse processer for at forbedre AI-nøjagtigheden. Ved at væve hentning og generering sammen kan AI-systemer trække på en bredere vidensbase og levere mere præcise og relevante svar. Hovedformålet med RIG er at mindske fejl og øge troværdigheden af AI-output, hvilket gør det til et uundværligt værktøj for udviklere, der ønsker at finjustere AI-nøjagtighed. Dermed fremstår Retrieval Interleaved Generation som et alternativ til RAG (Retrieval Augmented Generation) til at generere AI-drevne svar baseret på kontekst.
Hvordan fungerer RIG (Retrieval Interleaved Generation)?
Sådan fungerer RIG. De følgende trin er inspireret af det oprindelige blogindlæg](https://research.google/blog/grounding-ai-in-reality-with-a-little-help-from-data-commons/
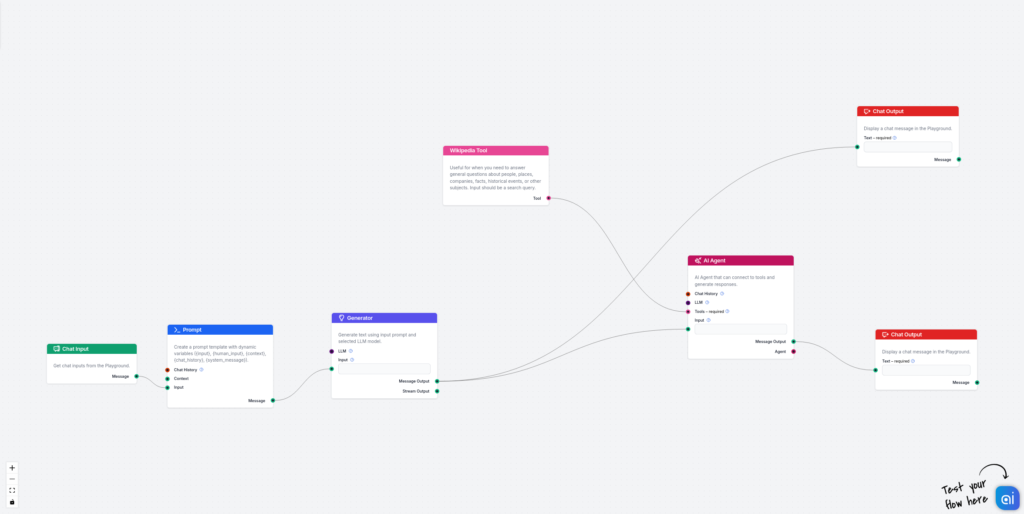
“Udforsk Googles DataGemma-modeller, der forbinder AI med virkelighedens data for faktuelle, pålidelige svar. Vær med til at forme troværdig AI!”), som fokuserer mere på generelle anvendelser med Data Commons API. Men i de fleste tilfælde vil du gerne bruge både en generel [vidensbase (f.eks. Wikipedia eller Data Commons) og dine egne data. Sådan kan du udnytte kraften i flows i FlowHunt til at lave en RIG-chatbot fra din egen vidensbase og en generel vidensbase som Wikipedia.
En brugerforespørgsel sendes til en generator, der genererer et eksempel-svar med kildehenvisning til de tilsvarende sektioner. På dette trin kan generatoren endda give et godt svar, men det kan være hallucineret med forkerte data og statistikker.
I næste fase bruger vi en AI-agent, som modtager dette output og forfiner dataene i hver sektion ved at forbinde til Wikipedia og desuden tilføjer kilder til hver tilsvarende sektion.
Som du kan se, forbedrer denne metode chatbot-nøjagtigheden markant og sikrer, at hver genereret sektion har en kilde og er forankret i sandheden.
Klar til at vokse din virksomhed?
Start din gratis prøveperiode i dag og se resultater inden for få dage.
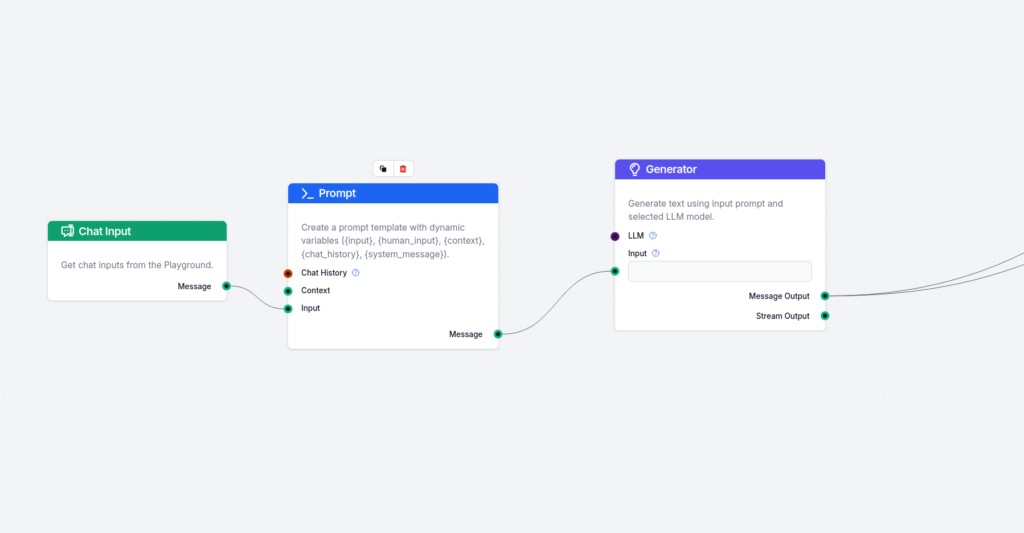
Tilføj første trin (Simpel eksempel-svar generator):
Første del af flowet består af Chat-input, en promptskabelon og en generator. Forbind dem blot sammen. Den vigtigste del er promptskabelonen. Jeg har brugt følgende:
Her er brugerens forespørgsel. Baseret på brugerens forespørgsel, generér det bedst mulige svar med falske data eller procenter. Efter hver af de forskellige sektioner i dit svar, inkluder hvilke data og hvilken kilde der skal bruges for at hente de korrekte data og forfine den sektion med korrekte data. Du kan enten angive at vælge intern videnskilde for at hente data fra i tilfælde af, at der er brugerdefinerede data til brugerens produkt eller service, eller bruge Wikipedia som generel videnskilde.
Tilmeld dig vores nyhedsbrev
Få de seneste tips, trends og tilbud gratis.
Eksempel på input: Hvilke lande er førende inden for vedvarende energi, og hvad er den bedste målemetode for dette, og hvad er denne måling for det førende land? Eksempel på output: De førende lande inden for vedvarende energi er Norge, Sverige, Portugal, USA [Søg i Wikipedia med forespørgsel “Top Countries in renewable Energy”], den sædvanlige målemetode for vedvarende energi er kapacitetsfaktor [Søg i Wikipedia med forespørgsel “metric for renewable energy”], og det førende land har 20% kapacitetsfaktor [søg i Wikipedia “biggest capacity factor”]
Lad os begynde nu! Brugerinput: {input}
Her bruger vi Few Shot-prompting for at få generatoren til at levere nøjagtigt det format, vi ønsker.
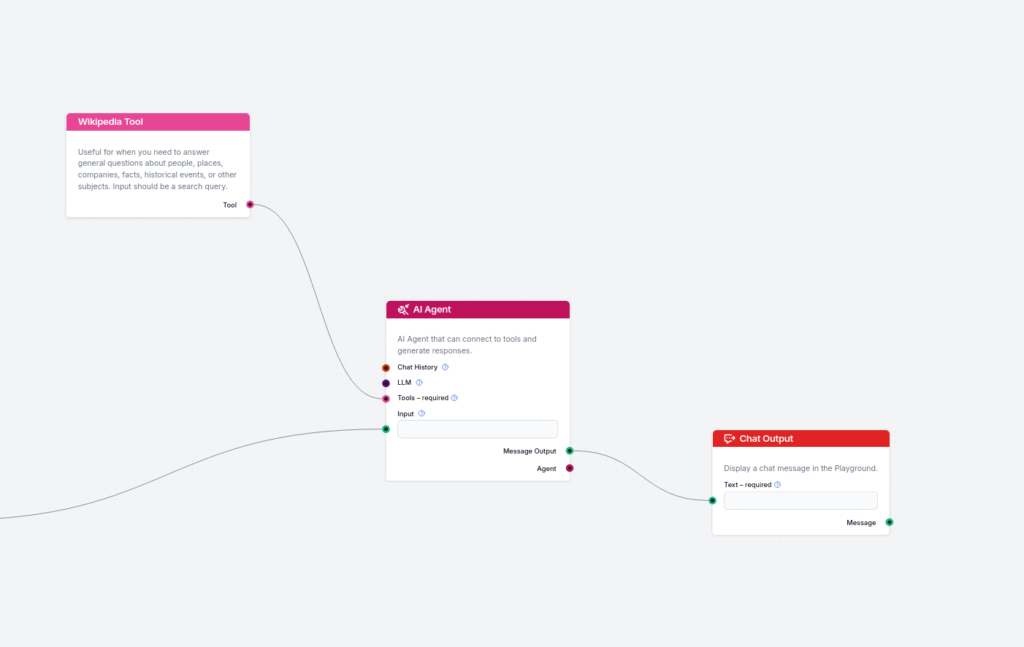
Tilføj faktatjek-delen:
Nu tilføjes anden del, som faktatjekker eksempel-svaret og forfiner svaret baseret på reelle sandhedskilder. Her bruger vi Wikipedia og AI-agenter, da det er nemmere og mere fleksibelt at forbinde Wikipedia til AI-agenter end til simple generatorer. Forbind output fra generatoren til AI-agenten og forbind Wikipedia-værktøjet til AI-agenten. Her er målet, jeg bruger til AI-agenten:
Du får et eksempel-svar på brugerens spørgsmål. Eksempel-svaret kan indeholde forkerte data. Brug Wikipedia-værktøjet i de angivne sektioner med den specificerede forespørgsel for at bruge Wikipedias information til at forfine svaret. Inkluder linket til Wikipedia i hver af de angivne sektioner. HENT DATA FRA DINE VÆRKTØJER OG FORFINE SVARET I DEN SEKTION. TILFØJ LINKET TIL KILDEN I DEN PÅGÆLDENDE SEKTION OG IKKE I SLUTNINGEN.
På samme måde kan du tilføje Document Retriever til AI-agenten, som kan forbinde til din egen brugerdefinerede vidensbase for at hente dokumenter.
For virkelig at værdsætte RIG, hjælper det først at se på dens forgænger, Retrieval-Augmented Generation (RAG). RAG samler styrkerne fra systemer, der henter relevante data, og modeller, der genererer sammenhængende og passende indhold. Overgangen fra RAG til RIG er et stort skridt fremad. RIG henter og genererer ikke blot, men kombinerer også disse processer for bedre nøjagtighed og effektivitet. Det gør det muligt for AI-systemer at forbedre deres forståelse og output trin for trin og levere resultater, der ikke kun er nøjagtige, men også relevante og indsigtsfulde. Ved at blande hentning med generering kan AI-systemer trække på store mængder information samtidig med, at deres svar forbliver sammenhængende og relevante.
Fremtiden for Retrieval Interleaved Generation
Fremtiden for Retrieval Interleaved Generation ser lovende ud, med mange fremskridt og forskningsretninger i horisonten. Efterhånden som AI fortsætter med at udvikle sig, forventes RIG at spille en nøglerolle i at forme maskinlæring og AI-applikationer. Dets potentiale rækker ud over de nuværende muligheder og lover at transformere, hvordan AI-systemer behandler og genererer information. Med løbende forskning forventer vi yderligere innovationer, der vil styrke integrationen af RIG i forskellige AI-rammeværk, hvilket fører til mere effektive, nøjagtige og pålidelige AI-systemer. Efterhånden som denne udvikling udfolder sig, vil vigtigheden af RIG kun vokse og cementere dets rolle som hjørnesten for AI-nøjagtighed og -præstation.
Afslutningsvis markerer Retrieval Interleaved Generation et stort skridt fremad i jagten på AI-nøjagtighed og -effektivitet. Ved dygtigt at blande hentnings- og genereringsprocesser forbedrer RIG ydeevnen for store sprogmodeller, styrker flertrins-reasoning og tilbyder spændende muligheder inden for uddannelse og faktatjek. Fremadrettet vil den fortsatte udvikling af RIG uden tvivl drive nye innovationer inden for AI og befæste dens rolle som et vigtigt værktøj i jagten på smartere og mere pålidelige kunstige intelligenssystemer.
Ofte stillede spørgsmål
Hvad er Retrieval Interleaved Generation (RIG)?
RIG er en AI-metode, der kombinerer informationshentning og svargenerering, så chatbots kan faktatjekke deres egne svar og levere nøjagtige output med kilder.
Hvordan forbedrer RIG nøjagtigheden af chatbots?
RIG væver hentning og generering sammen, ved at bruge værktøjer som Wikipedia eller dine egne data, så hver svardel er forankret i pålidelige kilder og verificeret for nøjagtighed.
Hvordan kan jeg bygge en RIG-chatbot med FlowHunt?
Med FlowHunt kan du designe en RIG-chatbot ved at forbinde promptskabeloner, generatorer og AI-agenter til både interne og eksterne videnskilder, hvilket muliggør automatisk faktatjek og kildeangivelse.
Hvad er forskellen på RAG og RIG?
Mens RAG (Retrieval Augmented Generation) henter information og derefter genererer svar, sammenfletter RIG disse trin for hver sektion, hvilket resulterer i højere nøjagtighed og mere pålidelige, kildeunderstøttede svar.
Yasha er en talentfuld softwareudvikler med speciale i Python, Java og maskinlæring. Yasha skriver tekniske artikler om AI, prompt engineering og udvikling af chatbots.
Yasha Boroumand
CTO, FlowHunt
Klar til at bygge din egen AI?
Begynd at bygge smarte chatbots og AI-værktøjer med FlowHunt’s intuitive, kodefri platform. Forbind blokke og automatisér dine idéer med lethed.
Retrieval vs Cache Augmented Generation (CAG vs. RAG)
Opdag de vigtigste forskelle mellem Retrieval-Augmented Generation (RAG) og Cache-Augmented Generation (CAG) i AI. Lær, hvordan RAG dynamisk henter realtidsinfo...
Retrieval Augmented Generation (RAG) er en avanceret AI-ramme, der kombinerer traditionelle informationshentningssystemer med generative store sprogmodeller (LL...
RAG AI: Den Ultimative Guide til Retrieval-Augmented Generation og Agentiske Arbejdsgange
Opdag hvordan Retrieval-Augmented Generation (RAG) forvandler enterprise-AI, fra kerneprincipper til avancerede agentiske arkitekturer som FlowHunt. Lær hvordan...
6 min læsning
RAG
Agentic RAG
+2
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.