Ydelsesvurdering af Gemini 2.0 Thinking: En Omfattende Evaluering
En omfattende vurdering af Gemini 2.0 Thinking, Googles eksperimentelle AI-model, med fokus på dens ydeevne, gennemsigtighed i ræsonnement og praktiske anvendelser på centrale opgavetyper.
AI
Gemini 2.0
Model Evaluation
AI Transparency
AI Reasoning
Content Generation
Summarization
Calculation
Comparison
Analytical Writing
Vores evalueringsmetode omfattede test af Gemini 2.0 Thinking på fem repræsentative opgavetyper:
Indholdsgenerering – Oprettelse af struktureret, informativt indhold
Beregning – Løsning af matematiske problemer i flere trin
Opsummering – Effektiv kondensering af kompleks information
Sammenligning – Analyse og kontrast af komplekse emner
Kreativ/analytisk skrivning – Udarbejdelse af detaljerede scenarioanalyser
For hver opgave målte vi:
Behandlingstid
Outputkvalitet
Ræsonnementstilgang
Mønstre i værktøjsbrug
Læselighedsmetrikker
Opgave 1: Ydelse i Indholdsgenerering
Opgavebeskrivelse: Generér en omfattende artikel om projektledelsens grundprincipper, med fokus på at definere mål, scope og delegering.
Ydelsesvurdering:
Gemini 2.0 Thinking’s synlige ræsonnement er bemærkelsesværdigt. Modellen demonstrerede en systematisk, flertrins research- og synteseproces på tværs af to opgavevarianter:
Startede med Wikipedia for grundlæggende kontekst
Brugte Google Søgning til specifikke detaljer og best practices
Forfinede søgninger på baggrund af indledende fund
Crawlede specifikke URL’er for dybere information
Styrker i informationsbearbejdning:
I variant to blev avanceret kildeidentifikation demonstreret og flere URL’er crawlet for detaljeret viden
Skabte meget struktureret output med klar hierarkisk organisering (læsbarhed på 13. klassetrin)
Indarbejdede specifikke frameworks som ønsket (SMART, OKRs, WBS, RACI Matrix)
Balancerede effektivt teoretiske begreber med praktiske anvendelser
Effektivitetsmetrikker:
Behandlingstider: 30 sekunder (variant 1) vs. 56 sekunder (variant 2)
Længere behandlingstid i variant 2 hang sammen med mere omfattende research og et mere detaljeret output (710 vs. ~500 ord)
Ydelsesvurdering:9/10
Indholdsgenereringen opnår en høj vurdering på grund af modellens evne til at:
Gennemføre research på tværs af flere kilder selvstændigt
Strukturere information logisk med passende overskrifter/underoverskrifter
Balancere teori med praktiske frameworks
Tilpasse researchdybde efter promptens specifikationer
Generere professionelt indhold hurtigt (under 1 minut)
Den største styrke i Thinking-versionen er synligheden i research-metoden, hvor man kan se, hvilke værktøjer der bruges på hvert trin, dog blev eksplicit ræsonnement vist inkonsekvent.
Klar til at vokse din virksomhed?
Start din gratis prøveperiode i dag og se resultater inden for få dage.
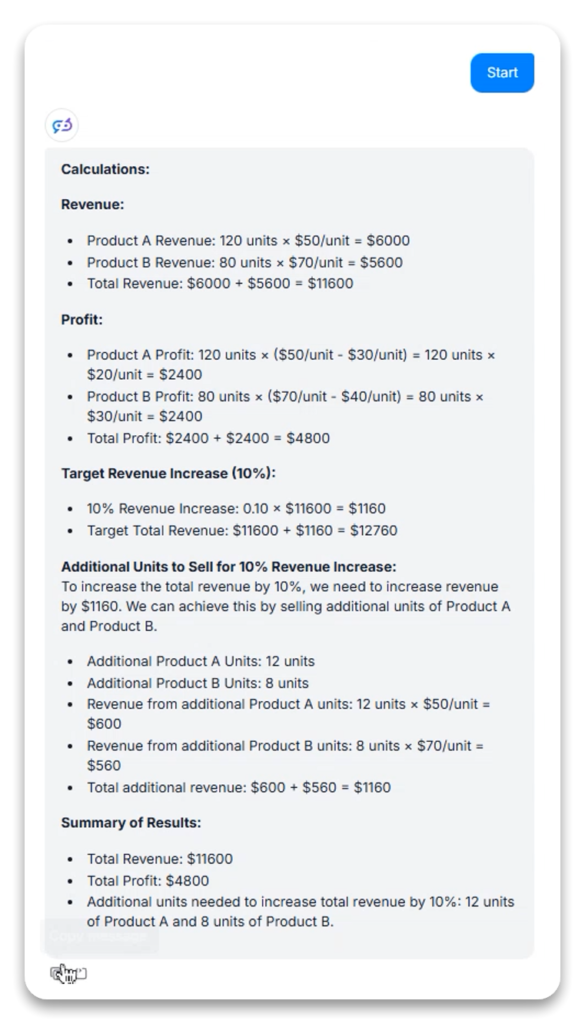
Opgavebeskrivelse: Løs et flerleddet forretningsberegningsproblem med fokus på omsætning, profit og optimering.
Ydelsesvurdering:
På tværs af begge opgavevarianter demonstrerede modellen stærke matematiske ræsonnementsevner:
Decomposition: Delte komplekse problemer op i logiske delberegninger (omsætning pr. produkt → total omsætning → omkostning pr. produkt → total omkostning → profit pr. produkt → total profit)
Optimering: I den første variant, hvor det blev bedt om at beregne, hvor mange ekstra enheder der krævedes for 10% højere omsætning, redegjorde modellen eksplicit for sin optimeringsstrategi (prioritering af dyrere produkter for at minimere antal enheder)
Verifikation: I anden variant viste modellen resultatverifikation ved at udregne, om den foreslåede løsning (12 enheder A, 8 enheder B) ville opnå den nødvendige ekstra omsætning
Styrker i matematisk bearbejdning:
Præcision i beregninger uden matematiske fejl
Transparent trinvis opdeling, der gør verifikation let
Effektiv brug af formatering (punktform, tydelige afsnitsoverskrifter) til at organisere beregningstrin
Forskellige løsningsmetoder mellem varianter, der viser fleksibilitet
Effektivitetsmetrikker:
Behandlingstider: 19 sekunder (variant 1) vs. 23 sekunder (variant 2)
Konsistent ydeevne på tværs af begge varianter trods forskellige tilgange
Ydelsesvurdering:9,5/10
Beregningen får topkarakter på baggrund af:
Fejlfri beregningspræcision
Klar trinvis procesdokumentation
Flere løsningsmetoder, der demonstrerer fleksibilitet
Effektiv behandlingstid
Effektiv præsentation og verifikation af resultater
“Thinking”-egenskaben var særligt værdifuld i første variant, hvor modellen tydeligt redegjorde for antagelser og optimeringsstrategi, hvilket giver gennemsigtighed i beslutningsprocessen, der ellers ville mangle i standardmodeller.
Opgave 3: Ydelse i Opsummering
Opgavebeskrivelse: Opsummer de vigtigste resultater fra en artikel om AI-reasoning på 100 ord.
Ydelsesvurdering:
Modellen viste bemærkelsesværdig effektivitet i tekstopsummering på begge opgavevarianter:
Behandlingshastighed: Fuldførte opsummeringen på ca. 3 sekunder i begge varianter
Overholdelse af længdekrav: Genererede opsummeringer på godt under 100 ord (70-71 ord)
Indholdsvalg: Identificerede og inkluderede de væsentligste aspekter fra kildeteksten
Informationsdensitet: Bevarede høj informationsdensitet og sammenhæng i opsummeringen
Styrker i opsummering:
Ekstraordinær behandlingshastighed (3 sekunder)
Perfekt overholdelse af længdekravet
Bevarelse af centrale tekniske begreber
Logisk flow trods kraftig komprimering
Balanceret dækning af kildens afsnit
Effektivitetsmetrikker:
Behandlingstid: ~3 sekunder i begge varianter
Opsummeringslængde: 70-71 ord (inden for 100-ordsgrænsen)
Informationskompressionsforhold: Ca. 85-90% reduktion fra kilde
Ydelsesvurdering:10/10
Opsummeringsydelsen får topkarakter på grund af:
Ekstremt hurtig behandlingstid
Perfekt overholdelse af krav
Fremragende prioritering af information
Stærk sammenhæng trods høj kompression
Konsistent ydeevne på begge testvarianter
Interessant nok viste “Thinking”-funktionen ikke eksplicit ræsonnement i denne opgave, hvilket antyder, at modellen kan bruge forskellige kognitive strategier afhængigt af opgaven—opsummering kan være mere intuitiv end trinvis.
Tilmeld dig vores nyhedsbrev
Få de seneste tips, trends og tilbud gratis.
Opgave 4: Ydelse i Sammenligningsopgave
Opgavebeskrivelse: Sammenlign miljøpåvirkningen fra elbiler med brintdrevne biler på tværs af flere faktorer.
Ydelsesvurdering:
Modellen viste forskellige tilgange på de to varianter, med bemærkelsesværdige forskelle i behandlingstid og kildebrug:
Variant 1: Baserede sig primært på Google Søgning, færdig på 20 sekunder
Variant 2: Brugte Google Søgning efterfulgt af URL-crawling for dybere viden, færdig på 46 sekunder
Styrker i sammenlignende analyse:
Velstrukturerede sammenligningsrammer med klar kategorisk organisering
Balanceret perspektiv på begge teknologiers fordele og begrænsninger
Integration af specifikke datapunkter (effektivitetsprocenter, tankningstider)
Passende teknisk dybde (læsbarhed på 14.-15. klassetrin)
I variant 2 korrekt angivelse af informationskilde (Earth.org-artikel)
Variant 2 havde tydeligere brug af specifikke kilder
Begge havde tilsvarende læselighedsniveau (14.-15. klassetrin)
Ydelsesvurdering:8,5/10
Sammenligningsopgaven får en stærk vurdering pga.:
Velstrukturerede sammenligningsrammer
Balanceret analyse af fordele/ulemper
Teknisk nøjagtighed og passende dybde
Klar organisering efter relevante faktorer
Tilpasning af researchstrategi efter informationsbehov
“Thinking”-funktionen var synlig i værktøjsloggene, hvor man kunne følge modellens sekventielle tilgang til informationsindsamling: først bred søgning, derefter målrettet crawling for dybere viden. Denne gennemsigtighed hjælper brugeren med at forstå baggrunden for sammenligningen.
Opgave 5: Kreativ/Analytisk Skrivning
Opgavebeskrivelse: Analyser miljøændringer og samfundsmæssige konsekvenser i en verden, hvor elbiler fuldstændigt har erstattet forbrændingsmotorer.
Ydelsesvurdering:
På tværs af begge varianter viste modellen stærke analytiske evner uden synlig værktøjsbrug:
Behandlingstider: 43 sekunder (variant 1) vs. 39 sekunder (variant 2)
Ordtælling: ~543 ord (variant 1) vs. 1829 ord (variant 2)
Ydelsesvurdering:9/10
Den kreative/analytiske skrivning får en fremragende vurdering på baggrund af:
Omfattende dækning af alle ønskede aspekter
Imponerende længde og detaljeringsgrad
Balance mellem optimistisk vision og praktiske udfordringer
Stærke tværfaglige forbindelser
Hurtig behandling trods kompleks analyse
Ved denne opgave var “Thinking”-aspektet mindre synligt i loggene, hvilket antyder, at modellen benytter intern viden og syntese frem for ekstern værktøjsbrug til kreative/analytiske opgaver.
Samlet Ydelsesvurdering
På baggrund af vores omfattende evaluering udviser Gemini 2.0 Thinking imponerende evner på tværs af forskellige opgavetyper, hvor den særlige styrke er gennemsigtigheden i problemløsningsmetoden:
Det, der adskiller Gemini 2.0 Thinking fra standard-AI-modeller, er dens eksperimentelle tilgang til at synliggøre interne processer. Centrale fordele:
Gennemsigtighed i værktøjsbrug – Brugere kan se, hvornår og hvorfor modellen benytter specifikke værktøjer som Wikipedia, Google Søgning eller URL-crawling
Indblik i ræsonnement – Ved visse opgaver, især beregninger, deler modellen eksplicit sine ræsonnementstrin og antagelser
Sekventiel problemløsning – Loggene viser modellens trin-for-trin-tilgang til komplekse opgaver, hvor forståelsen opbygges gradvist
Indsigt i researchstrategi – Den synlige proces viser, hvordan modellen forfiner søgninger baseret på indledende fund
Fordele ved denne gennemsigtighed:
Øget tillid gennem procesgennemsigtighed
Pædagogisk værdi ved at observere ekspert-problemløsning
Fejlfinding når output ikke lever op til forventninger
Forskningsindsigt i AI’s ræsonnementsmønstre
Praktiske Anvendelser
Gemini 2.0 Thinking udmærker sig især til anvendelser, der kræver:
Research og syntese – Effektiv indsamling og organisering af information fra flere kilder
Pædagogiske demonstrationer – Synlig ræsonnementproces gør den værdifuld til undervisning i problemløsningsmetoder
Kompleks analyse – Stærke evner i tværfagligt ræsonnement med transparent metode
Samarbejde – Ræsonnements-gennemsigtighed gør det lettere for mennesker at forstå og bygge videre på modellens arbejde
Modellens hastighed, kvalitet og procesgennemsigtighed gør den særligt egnet til professionelle sammenhænge, hvor forståelsen af “hvorfor” bag AI-konklusioner er lige så vigtig som selve konklusionerne.
Konklusion
Gemini 2.0 Thinking repræsenterer en interessant eksperimentel retning inden for AI-udvikling, hvor fokus ikke kun er på outputkvalitet, men også på procesgennemsigtighed. Dens præstationer på tværs af vores testpakke viser stærke evner inden for research, beregning, opsummering, sammenligning og kreativ/analytisk skrivning—med særligt fremragende resultater i opsummering (10/10).
“Thinking”-tilgangen giver værdifuld indsigt i, hvordan modellen tackler forskellige opgaver, om end graden af gennemsigtighed varierer betydeligt mellem opgavetyper. Denne inkonsistens er det primære forbedringspunkt—større ensartethed i visning af ræsonnement vil øge modellens pædagogiske og samarbejdsværdi.
Samlet set står Gemini 2.0 Thinking med en samlet score på 9,2/10 som et yderst kompetent AI-system med den ekstra fordel af procesgennemsigtighed, hvilket gør den særligt velegnet til anvendelser, hvor forståelsen af ræsonnementsvejen er lige så vigtig som det endelige output.
Ofte stillede spørgsmål
Hvad er Gemini 2.0 Thinking?
Gemini 2.0 Thinking er en eksperimentel AI-model fra Google, der åbent viser sin ræsonnementproces og tilbyder gennemsigtighed i, hvordan den løser problemer på tværs af forskellige opgaver såsom indholdsgenerering, beregning, opsummering og analytisk skrivning.
Hvad adskiller Gemini 2.0 Thinking fra andre AI-modeller?
Dens unikke 'tænke'-gennemsigtighed lader brugere se værktøjsbrug, ræsonnementstrin og problemløsningsstrategier, hvilket øger tilliden og den pædagogiske værdi—særligt i forsknings- og samarbejdssammenhænge.
Hvordan blev Gemini 2.0 Thinking evalueret i denne analyse?
Modellen blev benchmark-testet på fem centrale opgavetyper: indholdsgenerering, beregning, opsummering, sammenligning og kreativ/analytisk skrivning, med målinger af blandt andet behandlingstid, outputkvalitet og synlighed i ræsonnement.
Hvad er de vigtigste styrker ved Gemini 2.0 Thinking?
Styrkerne omfatter research på tværs af flere kilder, høj beregningspræcision, hurtig opsummering, velstrukturerede sammenligninger, omfattende analyse og enestående procesgennemsigtighed.
Hvilke områder skal forbedres i Gemini 2.0 Thinking?
Modellen vil have gavn af mere ensartet gennemsigtighed i visning af ræsonnement på tværs af alle opgavetyper og tydeligere logning af værktøjsbrug i alle scenarier.
Arshia er AI Workflow Engineer hos FlowHunt. Med en baggrund inden for datalogi og en passion for AI, specialiserer han sig i at skabe effektive workflows, der integrerer AI-værktøjer i daglige opgaver og øger produktivitet og kreativitet.
Arshia Kahani
AI Workflow Engineer
Klar til at opleve gennemsigtig AI-ræsonnement?
Oplev hvordan procesgennemsigtighed og avanceret ræsonnement i Gemini 2.0 Thinking kan løfte dine AI-løsninger. Book en demo eller prøv FlowHunt i dag.
Gemini 2.0 Flash-Lite: Hastighed møder kapacitet i Googles nyeste AI
Opdag hvordan Googles Gemini 2.0 Flash-Lite klarer sig inden for indholdsskabelse, beregninger, opsummering og kreative opgaver. Vores dybdegående analyse afslø...
Gemini 2.5 Pro Preview: Ydelsesanalyse på Tværs af Nøgleopgaver
En omfattende gennemgang af Googles Gemini 2.5 Pro Preview, hvor dens reelle ydeevne vurderes på fem centrale opgaver, herunder indholdsgenerering, forretningsb...
Udforsk tankeprocessen, arkitekturen og beslutningstagningen bag Gemini 1.5 Pro, en alsidig AI-agent, gennem virkelige opgaver og dybdegående analyse af dens ræ...
10 min læsning
AI Agents
Reasoning
+5
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.