
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) ist ein fortschrittliches KI-Framework, das traditionelle Informationsabrufsysteme mit generativen großen Sprachmodellen (L...
3 Min. Lesezeit
RAG
AI
+4

Fragebeantwortung mit RAG verbessert LLMs durch die Integration von Echtzeit-Datenabruf und natürlicher Sprachgenerierung für präzise, kontextuell relevante Antworten.
Fragebeantwortung mit Retrieval-Augmented Generation (RAG) verbessert Sprachmodelle, indem Echtzeitdaten aus externen Quellen für präzise und relevante Antworten integriert werden. Sie optimiert die Leistung in dynamischen Bereichen und bietet verbesserte Genauigkeit, dynamische Inhalte und höhere Relevanz.
Fragebeantwortung mit Retrieval-Augmented Generation (RAG) ist eine innovative Methode, die die Stärken von Informationsabruf und natürlicher Sprachgenerierung kombiniert, um menschenähnlichen Text aus Daten zu erstellen und so KI, Chatbots, Berichte und personalisierte Erlebnisse zu verbessern. Dieser hybride Ansatz erweitert die Fähigkeiten großer Sprachmodelle (LLMs), indem deren Antworten mit relevanten, aktuellen Informationen aus externen Datenquellen ergänzt werden. Im Gegensatz zu herkömmlichen Methoden, die ausschließlich auf vortrainierten Modellen basieren, integriert RAG dynamisch externe Daten, sodass Systeme genauere und kontextuell relevantere Antworten liefern können – insbesondere in Bereichen, die aktuelle Informationen oder spezialisiertes Wissen erfordern.
RAG optimiert die Leistung von LLMs, indem sichergestellt wird, dass Antworten nicht nur aus einem internen Datensatz, sondern auch durch Echtzeit-Quellen mit Autoritätscharakter untermauert werden. Dieser Ansatz ist entscheidend für Fragebeantwortungsaufgaben in dynamischen Bereichen, in denen sich Informationen ständig verändern.
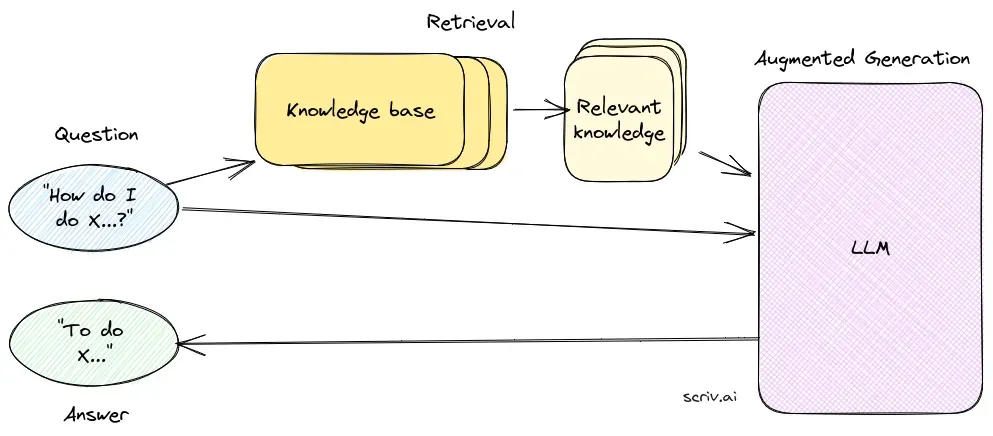
Die Retrieval-Komponente ist zuständig für das Auffinden relevanter Informationen aus großen Datensätzen, die typischerweise in einer Vektordatenbank gespeichert sind. Diese Komponente nutzt semantische Suchverfahren, um Textabschnitte oder Dokumente zu identifizieren und zu extrahieren, die für die Anfrage des Nutzers besonders relevant sind.
Die Generierungskomponente, meist ein LLM wie GPT-3 oder BERT, synthetisiert eine Antwort, indem sie die ursprüngliche Benutzeranfrage mit dem abgerufenen Kontext kombiniert. Diese Komponente ist entscheidend für die Erzeugung kohärenter und kontextuell angemessener Antworten.
Die Implementierung eines RAG-Systems umfasst mehrere technische Schritte:
Forschung zur Fragebeantwortung mit Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) ist eine Methode, die Fragebeantwortungssysteme durch die Kombination von Retrieval-Mechanismen mit generativen Modellen verbessert. Aktuelle Forschung untersucht die Wirksamkeit und Optimierung von RAG in verschiedenen Kontexten.
RAG ist eine Methode, die Informationsabruf und natürliche Sprachgenerierung kombiniert, um genaue und aktuelle Antworten zu liefern, indem externe Datenquellen in große Sprachmodelle integriert werden.
Ein RAG-System besteht aus einer Retrieval-Komponente, die relevante Informationen aus Vektordatenbanken mittels semantischer Suche bezieht, und einer Generierungskomponente, meist ein LLM, das Antworten unter Verwendung der Benutzeranfrage und des abgerufenen Kontexts synthetisiert.
RAG verbessert die Genauigkeit durch das Abrufen kontextuell relevanter Informationen, unterstützt dynamische Inhaltsaktualisierungen aus externen Wissensdatenbanken und erhöht die Relevanz und Qualität der generierten Antworten.
Gängige Anwendungsfälle umfassen KI-Chatbots, Kundensupport, automatisierte Inhaltserstellung und Bildungstools, die präzise, kontextbewusste und aktuelle Antworten benötigen.
RAG-Systeme können ressourcenintensiv sein, erfordern eine sorgfältige Integration für optimale Leistung und müssen die sachliche Genauigkeit der abgerufenen Informationen sicherstellen, um irreführende oder veraltete Antworten zu vermeiden.
Entdecken Sie, wie Retrieval-Augmented Generation Ihre Chatbot- und Support-Lösungen mit präzisen Echtzeit-Antworten verbessern kann.
Retrieval Augmented Generation (RAG) ist ein fortschrittliches KI-Framework, das traditionelle Informationsabrufsysteme mit generativen großen Sprachmodellen (L...
Entdecken Sie, wie Retrieval-Augmented Generation (RAG) die Unternehmens-KI revolutioniert – von den Grundprinzipien bis hin zu fortschrittlichen agentischen Ar...
Entdecken Sie die wichtigsten Unterschiede zwischen Retrieval-Augmented Generation (RAG) und Cache-Augmented Generation (CAG) in der KI. Erfahren Sie, wie RAG d...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.

