
Integración de MotherDuck MCP
Integra FlowHunt con el servidor DuckDB MCP de MotherDuck para habilitar análisis SQL seguros, escalables y sin servidor para tus asistentes de IA e IDEs. Conec...
5 min de lectura
AI
MotherDuck
+6
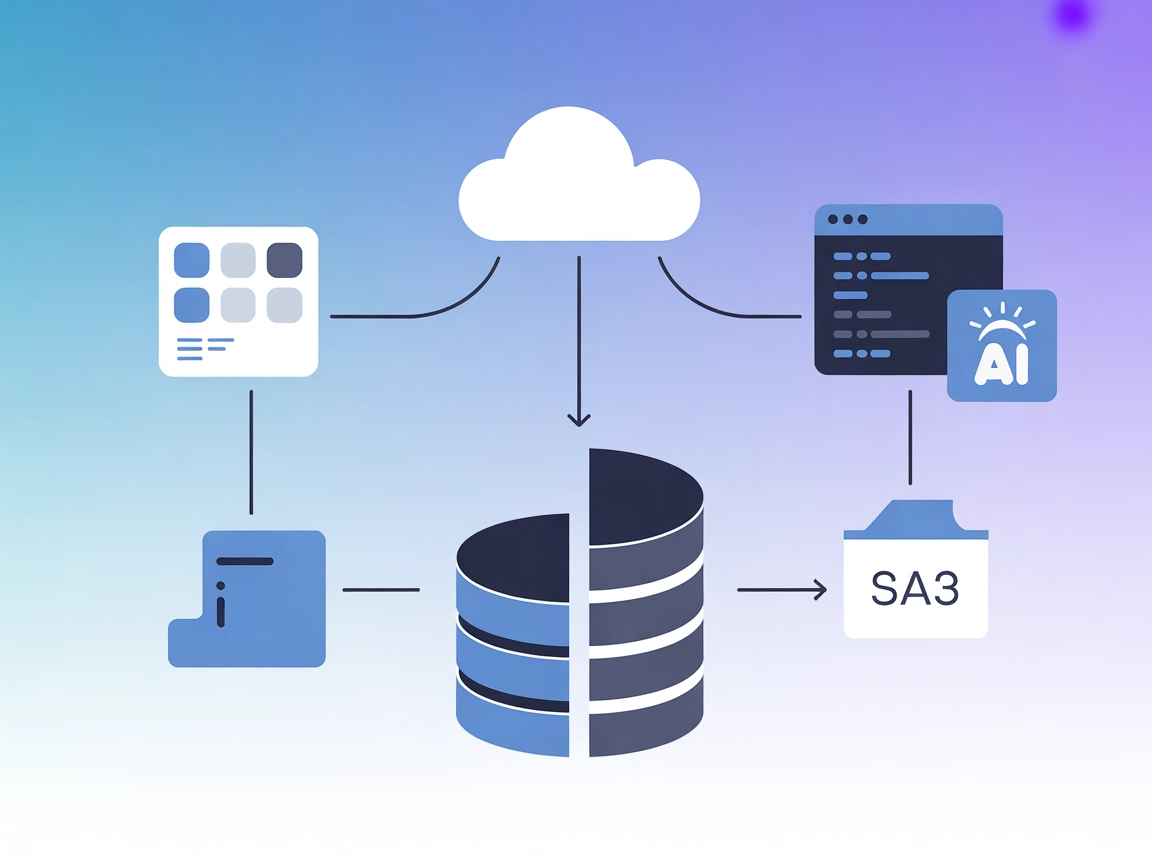
MotherDuck MCP Server conecta agentes de IA e IDEs con DuckDB y MotherDuck para análisis SQL sin servidor y flujos de trabajo de datos híbridos en FlowHunt.
FlowHunt proporciona una capa de seguridad adicional entre tus sistemas internos y las herramientas de IA, dándote control granular sobre qué herramientas son accesibles desde tus servidores MCP. Los servidores MCP alojados en nuestra infraestructura pueden integrarse perfectamente con el chatbot de FlowHunt, así como con plataformas de IA populares como ChatGPT, Claude y varios editores de IA.
El Servidor MotherDuck MCP es una implementación del Protocolo de Contexto de Modelo (MCP) que conecta asistentes de IA e IDEs con bases de datos DuckDB y MotherDuck. Permite a los usuarios realizar potentes análisis SQL proporcionando una interfaz estandarizada para consultar tanto archivos DuckDB locales como bases de datos MotherDuck en la nube. El servidor soporta ejecución híbrida, permitiendo acceso fluido a datos tanto de almacenamiento local como en la nube, incluyendo Amazon S3 a través de las integraciones de MotherDuck. Al exponer la interacción con bases de datos como una herramienta para sistemas de IA, facilita a desarrolladores y agentes de IA realizar consultas, gestionar datos y optimizar flujos de trabajo de datos sin configuración manual ni gestión de servidores. Este enfoque sin servidor acelera el análisis, el intercambio de datos y el desarrollo de pipelines de datos directamente desde entornos potenciados por IA.
Comienza tu prueba gratuita hoy y ve resultados en días.
query (string, requerido): La sentencia SQL a ejecutar.Obtén los últimos consejos, tendencias y ofertas gratis.
Asegúrate de tener Node.js y Windsurf instalados.
Abre tu archivo de configuración de Windsurf (comúnmente windsurf.config.json).
Agrega el Servidor MotherDuck MCP a la sección mcpServers:
{
"mcpServers": {
"motherduck": {
"command": "uvx",
"args": ["mcp-server-motherduck", "--transport", "stream", "--db-path", "md:"]
}
}
}
Guarda la configuración y reinicia Windsurf.
Verifica en Windsurf que el Servidor MotherDuck MCP esté corriendo y accesible.
Utiliza variables de entorno para proporcionar credenciales sensibles como tu token de MotherDuck:
{
"mcpServers": {
"motherduck": {
"command": "uvx",
"args": ["mcp-server-motherduck", "--transport", "stream", "--db-path", "md:"],
"env": {
"motherduck_token": "${MOTHERDUCK_TOKEN}"
}
}
}
}
Instala Claude y asegúrate de tener Node.js.
Localiza el archivo de configuración de Claude (típicamente claude.config.json).
Agrega lo siguiente a tu sección mcpServers:
{
"mcpServers": {
"motherduck": {
"command": "uvx",
"args": ["mcp-server-motherduck", "--transport", "stream", "--db-path", "md:"]
}
}
}
Reinicia Claude y confirma que el servidor aparezca en la interfaz.
Usa variables de entorno como se muestra arriba para proteger las claves API.
Asegúrate de tener Cursor instalado y actualizado.
Abre la configuración de Cursor (cursor.config.json).
Inserta lo siguiente bajo mcpServers:
{
"mcpServers": {
"motherduck": {
"command": "uvx",
"args": ["mcp-server-motherduck", "--transport", "stream", "--db-path", "md:"]
}
}
}
Guarda y reinicia Cursor.
Configura los tokens sensibles mediante variables de entorno.
Instala Cline y las dependencias necesarias.
Edita cline.config.json para incluir:
{
"mcpServers": {
"motherduck": {
"command": "uvx",
"args": ["mcp-server-motherduck", "--transport", "stream", "--db-path", "md:"]
}
}
}
Guarda la configuración y reinicia Cline.
Asegúrate de que motherduck_token esté configurado como variable de entorno para seguridad.
Usar MCP en FlowHunt
Para integrar servidores MCP en tu flujo de trabajo FlowHunt, comienza añadiendo el componente MCP a tu flujo y conectándolo a tu agente de IA:

Haz clic en el componente MCP para abrir el panel de configuración. En la sección de configuración MCP del sistema, inserta los detalles de tu servidor MCP usando este formato JSON:
{
"motherduck": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Una vez configurado, el agente de IA podrá usar este MCP como herramienta con acceso a todas sus funciones y capacidades. Recuerda cambiar "motherduck" por el nombre real de tu servidor MCP y reemplazar la URL por la de tu propio servidor MCP.
| Sección | Disponibilidad | Detalles/Notas |
|---|---|---|
| Resumen | ✅ | Encontrado en README.md |
| Lista de Prompts | ✅ | duckdb-motherduck-initial-prompt |
| Lista de Recursos | ✅ | Dos recursos (artículo de blog, video de YouTube) listados en README.md |
| Lista de Herramientas | ✅ | Herramienta query |
| Seguridad de Claves API | ✅ | Usa motherduck_token como variable de entorno (README.md) |
| Soporte de Muestreo (menos importante evaluar) | ⛔ | No mencionado |
Entre estas dos tablas, el Servidor MotherDuck MCP está bien documentado con prompts claros, soporte de herramientas, recursos y prácticas de seguridad, pero carece de mención explícita sobre Roots y soporte de muestreo. En general, es una implementación sólida y práctica para análisis de bases de datos con una interfaz MCP.
| ¿Tiene LICENSE? | ✅ (MIT) |
|---|---|
| ¿Tiene al menos una herramienta? | ✅ |
| Número de Forks | 23 |
| Número de Estrellas | 205 |
El Servidor MotherDuck MCP es una implementación del Protocolo de Contexto de Modelo (MCP) que conecta asistentes de IA e IDEs con bases de datos DuckDB y MotherDuck. Proporciona una forma estandarizada de ejecutar análisis SQL, gestionar datos y desarrollar pipelines de datos utilizando almacenamiento local y en la nube, todo sin gestión manual de servidores.
MotherDuck MCP Server permite a asistentes de IA y desarrolladores realizar análisis SQL, construir pipelines de datos y acceder a fuentes de datos híbridas locales/en la nube. Soporta casos como exploración de datos sin servidor, integración con almacenamiento en la nube (por ejemplo, Amazon S3) y análisis rápido sin configuración de infraestructura.
Debes usar variables de entorno para proporcionar de forma segura tus tokens de MotherDuck. Configura el `motherduck_token` en tu configuración como variable de entorno (por ejemplo, `${MOTHERDUCK_TOKEN}`) en vez de escribir las credenciales directamente.
¡Sí! FlowHunt soporta servidores MCP. Simplemente añade el componente MCP a tu flujo, configúralo con los detalles de tu servidor MotherDuck MCP y tu agente de IA podrá interactuar directamente con las bases de datos DuckDB y MotherDuck.
La herramienta principal expuesta es `query`, que permite ejecutar consultas SQL en bases de datos DuckDB o MotherDuck desde tu agente de IA o IDE.
Consulta el [artículo del blog de MotherDuck](https://motherduck.com/blog/faster-data-pipelines-with-mcp-duckdb-ai/) y el [video de YouTube](https://www.youtube.com/watch?v=yG1mv8ZRxcU) para profundizar en MCP, DuckDB y flujos de trabajo de datos potenciados por IA.
Acelera el análisis de datos y optimiza tus flujos de trabajo integrando el Servidor MotherDuck MCP con FlowHunt. Experimenta SQL híbrido y sin servidor al alcance de tu mano.
Integra FlowHunt con el servidor DuckDB MCP de MotherDuck para habilitar análisis SQL seguros, escalables y sin servidor para tus asistentes de IA e IDEs. Conec...
El Servidor MCP de DataHub conecta los agentes de IA de FlowHunt con la plataforma de metadatos DataHub, permitiendo descubrimiento avanzado de datos, análisis ...

El Servidor MCP de MongoDB permite una integración fluida entre asistentes de IA y bases de datos MongoDB, permitiendo la gestión directa de bases de datos, aut...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.