Deep Agent
Découvrez comment construire et configurer des Deep Agents dans FlowHunt — des agents autonomes et multi-étapes capables de raisonnement complexe, d'utilisation...
8 min de lecture
Agents
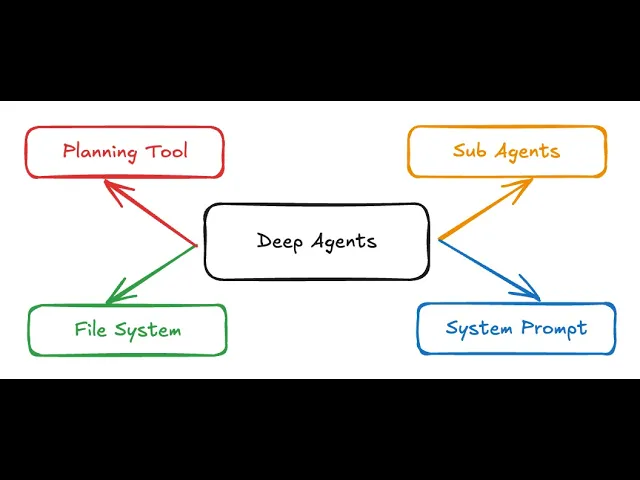
Découvrez les quatre caractéristiques clés qui définissent les deep agents : outils de planification, sous-agents, systèmes de fichiers et prompts système détaillés. Apprenez comment des agents IA modernes comme Claude Code et Manus accomplissent des tâches complexes et longues.
Le paysage de l’intelligence artificielle a connu une transformation remarquable avec l’apparition de systèmes d’agents sophistiqués capables de traiter des tâches complexes et multi-étapes, qui auraient été impossibles il y a encore quelques mois. Des outils comme Claude Code ont captivé la communauté des développeurs non seulement pour leurs compétences en programmation, mais aussi pour leur étonnante polyvalence à rédiger des livres, générer des rapports et relever divers défis intellectuels. Cette capacité découle d’une innovation architecturale fondamentale : le concept de deep agents — des systèmes IA conçus pour planifier en profondeur, exécuter méthodiquement et s’attaquer à des problèmes complexes tout en préservant la cohérence sur de longues périodes.
Les deep agents représentent une évolution majeure dans la façon dont nous concevons les systèmes IA pour atteindre des objectifs ambitieux. Contrairement aux modèles de langage à appel unique ou aux agents séquentiels simples, les deep agents sont spécifiquement architecturés pour traiter des tâches nécessitant un raisonnement soutenu, un raffinement itératif et la capacité d’explorer simultanément plusieurs domaines problématiques. L’émergence de systèmes comme Manus (un agent généraliste), Deep Research d’OpenAI et Claude Code montre que ce modèle devient central dans la construction de systèmes IA performants.
L’intuition fondamentale derrière les deep agents est d’une simplicité trompeuse : la même boucle d’appel d’outils qui fait fonctionner les agents de base peut être considérablement renforcée par quatre ajouts stratégiques. Ces améliorations ne nécessitent pas d’inventer de nouveaux algorithmes ni des approches radicalement différentes du raisonnement IA. Elles reposent sur une ingénierie minutieuse des outils à disposition des agents, la structure de leurs processus de planification et les instructions détaillées fournies via les prompts système. Cette approche s’avère très efficace car elle s’appuie sur les forces naturelles des grands modèles de langage, plutôt que d’aller à leur encontre.
Commencez votre essai gratuit aujourd'hui et voyez les résultats en quelques jours.
Les implications pratiques de l’architecture des deep agents vont bien au-delà de l’intérêt académique. Les organisations font face à des défis de plus en plus complexes nécessitant une automatisation intelligente et soutenue : mener des études de marché approfondies, générer une documentation technique détaillée, construire des systèmes logiciels complexes ou gérer des workflows multi-étapes s’étalant sur plusieurs heures ou jours. Les approches d’automatisation traditionnelles peinent à relever ces défis, faute de flexibilité et de capacité de raisonnement qu’offrent les deep agents.
Pour les développeurs et organisations qui envisagent l’automatisation par l’IA, comprendre l’architecture des deep agents offre plusieurs avantages déterminants :
Les deep agents sont définis par quatre caractéristiques essentielles qui agissent ensemble pour permettre l’exécution de tâches sophistiquées. Comprendre chaque pilier permet de saisir pourquoi ces systèmes réussissent là où les approches plus simples échouent.
Le premier composant clé de l’architecture deep agent est l’outil de planification. Cela peut sembler anodin, mais cela répond à un défi fondamental : les modèles de langage, malgré leurs performances impressionnantes, peinent à maintenir la cohérence lors de l’exécution de tâches longues ou nécessitant un focus soutenu sur un objectif global.
Manus, par exemple, intègre un module de planification dédié dans son prompt système, qui demande explicitement à l’agent de générer et suivre un plan de tâches. Le prompt décrit comment la planification sera fournie sous forme d’événements dans un flux, et surtout, il indique à l’agent d’exécuter tout selon ce plan. Claude Code implémente un concept similaire via son outil d’écriture de to-do, qui crée et gère des listes de tâches structurées.
Ce qui distingue ces outils de planification, c’est leur simplicité. L’outil to-do de Claude Code est essentiellement un « no-op » : il ne persiste pas de données dans une base ou ne maintient pas d’état au sens traditionnel. Il fonctionne en demandant au modèle de générer une liste de tâches, laquelle apparaît dans la fenêtre de contexte du modèle sous forme de message. Lorsqu’il faut actualiser le plan, l’agent génère simplement une nouvelle liste. Cette approche est très efficace car elle utilise la fenêtre de contexte du modèle comme une mémoire de travail.
L’outil de planification résout un problème critique : sans planification explicite, les agents perdent facilement de vue leur objectif global en exécutant des étapes individuelles. L’outil de planification permet à l’agent de rester ancré à son but principal, assurant une exécution cohérente sur le long terme.
Le second pilier de l’architecture deep agent est l’utilisation de sous-agents — des agents spécialisés auxquels l’orchestrateur principal peut déléguer des tâches tout en maintenant une séparation claire des préoccupations. La recherche d’Anthropic illustre clairement ce modèle : un agent principal peut coordonner plusieurs sous-agents spécialisés pour différentes fonctions, comme la vérification de citations ou la collecte d’informations en parallèle.
Les sous-agents offrent plusieurs avantages distincts qui, combinés, rendent possible l’exécution de tâches plus sophistiquées :
Préservation et isolation du contexte : Chaque sous-agent opère dans son propre contexte isolé. Lorsqu’un sous-agent explore un domaine complexe — en menant une recherche approfondie, en multipliant les appels d’outils ou en générant de nombreux résultats intermédiaires — rien de cela ne pollue la fenêtre de contexte du principal. Inversement, le travail antérieur de l’agent principal ne contraint pas la réflexion du sous-agent. Cette isolation permet aux sous-agents de se concentrer pleinement sur leur domaine sans interférences cognitives.
Expertise spécialisée : Les sous-agents peuvent bénéficier de prompts système spécialisés et d’outils personnalisés qui les orientent vers certains types de problèmes. Un sous-agent peut être optimisé pour la recherche, un autre pour la génération de code ou l’analyse technique. Cette spécialisation permet à chaque sous-agent d’apporter une expertise pointue, souvent avec de meilleurs résultats qu’un agent généraliste.
Réutilisabilité et modularité : Un sous-agent conçu pour une tâche peut être réutilisé dans plusieurs agents principaux ou workflows différents. Cette modularité réduit l’effort de développement et crée des briques combinables de façon innovante.
Permissions fines : Les sous-agents peuvent disposer de niveaux d’autorisations et d’accès aux outils différents. L’un peut avoir le droit d’écrire des fichiers ou d’exécuter du code, un autre ne peut qu’accéder en lecture à certaines ressources. Ce modèle granulaire améliore la sécurité et la qualité des résultats en empêchant des actions inappropriées.
La combinaison de la préservation du contexte, de l’expertise spécialisée et de la délégation ciblée permet aux deep agents de traiter des problèmes qui submergeraient un agent monolithique. En fragmentant les tâches complexes en sous-tâches spécialisées confiées à des agents ciblés, le système obtient à la fois de meilleurs résultats et une utilisation plus efficace de la capacité de raisonnement du modèle.
Le troisième pilier répond à une contrainte fondamentale des modèles de langage : leur fenêtre de contexte, bien que grande, reste limitée. À mesure que les agents exécutent des tâches et génèrent des résultats intermédiaires, observations et raisonnements, la quantité de contexte croît. Si tout ce contexte est sans cesse réinjecté dans le LLM, les performances se dégradent, le modèle peinant à garder le focus au milieu du bruit.
Les systèmes de fichiers résolvent élégamment ce problème. Plutôt que de conserver toutes les observations et résultats intermédiaires dans le contexte actif, les agents peuvent écrire les informations importantes dans des fichiers. L’agent peut alors référencer ces fichiers au besoin — lire des documents spécifiques, mettre à jour des fichiers ou en créer de nouveaux — sans tout garder en contexte actif en permanence.
L’approche de Manus illustre bien ce principe. Au lieu d’intégrer de grandes observations directement dans le contexte du LLM, le système utilise de courtes observations qui référencent des fichiers : « Voir document X » ou « Consulter fichier Y ». L’agent lit délibérément ces fichiers quand c’est pertinent, mais ils ne consomment pas d’espace dans la fenêtre de contexte s’ils ne sont pas nécessaires à l’instant.
| Stratégie de gestion du contexte | Approche | Bénéfice | Inconvénient |
|---|---|---|---|
| Tout en contexte | Garder toutes les observations dans le contexte du LLM | Accès immédiat à toutes les infos | Fenêtre de contexte saturée ; baisse de performance |
| Références fichiers | Stocker les observations en fichiers, référencer par nom | Usage efficace du contexte ; tâches volumineuses | Lecture de fichiers délibérée ; latence ajoutée |
| Approche hybride | Contexte actif + archivage fichiers | Équilibre efficacité/réactivité | Gestion fine du contexte nécessaire |
| Mises à jour en flux | Mise à jour continue des fichiers, lecture sélective | Tâches très longues supportées | Implémentation complexe ; cohérence à gérer |
Les modèles d’Anthropic sont particulièrement adaptés à cette approche car ils sont fine-tunés pour bien utiliser les outils d’édition de fichiers. Les modèles savent écrire, lire et gérer le contexte fichier. Ce fine-tuning est crucial : le modèle adopte naturellement l’usage des fichiers pour la gestion du contexte, au lieu de le traiter comme un ajout secondaire.
Le quatrième et dernier pilier est souvent négligé alors qu’il est crucial : des prompts système détaillés et exhaustifs. Il existe une idée reçue selon laquelle, parce que les modèles modernes sont très performants, un prompt bref suffirait et le modèle devinerait le reste. C’est totalement faux.
Les prompts système utilisés par les meilleurs deep agents ne sont pas de simples instructions — ce sont de véritables documents, souvent longs de centaines ou milliers de lignes. Le prompt de Deep Research d’Anthropic, open source, en est un parfait exemple. Il fournit des indications détaillées sur :
Cette exhaustivité est indispensable : l’agent doit comprendre non seulement quoi faire, mais comment le faire efficacement. Le prompt système apprend à l’agent à utiliser les outils de planification pour garder la cohérence, à déléguer aux sous-agents, à gérer le contexte par fichiers et à raisonner de façon systématique sur des problèmes complexes.
La leçon à retenir : le prompt reste absolument déterminant, même avec des modèles très avancés. La différence entre un agent moyen et un agent d’exception se joue souvent sur la qualité et la richesse du prompt système. Les meilleurs deep agents en production reposent sur des prompts qui représentent un véritable travail d’ingénierie.
Recevez gratuitement les derniers conseils, tendances et offres.
Pour les organisations qui conçoivent ou déploient des deep agents, la gestion des outils de planification, des sous-agents, des systèmes de fichiers et des prompts détaillés est un défi d’envergure. C’est là que des plateformes comme FlowHunt prennent tout leur sens. FlowHunt offre des outils intégrés pour orchestrer des workflows IA complexes, gérer les interactions entre agents et automatiser le déploiement de systèmes d’agents sophistiqués.
L’approche de FlowHunt s’aligne naturellement sur l’architecture deep agent. La plateforme permet aux équipes de :
En fournissant ces fonctionnalités dans une plateforme intégrée, FlowHunt réduit la charge d’ingénierie pour bâtir des deep agents, permettant aux équipes de se concentrer sur la logique métier plutôt que sur l’infrastructure.
Pour les développeurs souhaitant créer des deep agents sans partir de zéro, le package Python open source deep agents offre une structure précieuse. Ce package intègre des implémentations des quatre piliers :
Le package réduit considérablement le code nécessaire à la création d’un deep agent fonctionnel par rapport à un développement from scratch. Les développeurs fournissent les instructions et outils métier, le package gère la complexité architecturale.
L’architecture deep agent bouleverse la façon dont les organisations abordent l’automatisation et l’intégration de l’IA. Quelques scénarios concrets :
Recherche et analyse : Un deep agent peut conduire une étude de marché complète en planifiant une investigation en plusieurs étapes, en déléguant des tâches de recherche à des sous-agents spécialisés, en gérant le corpus de résultats dans des fichiers et en synthétisant le tout dans des rapports cohérents. Cela serait quasi impossible pour un agent simple.
Développement logiciel : Claude Code montre comment les deep agents peuvent gérer des projets de codage conséquents. L’agent planifie l’architecture globale, crée des sous-agents pour chaque composant, gère efficacement les fichiers de code et maintient la cohérence sur des milliers de lignes et de nombreux fichiers.
Génération de contenu : Les deep agents peuvent écrire des livres, produire des rapports détaillés et créer une documentation exhaustive en gardant le focus sur la structure globale tout en déléguant des sections à des sous-agents et en gérant le contenu dans des fichiers.
Automatisation des workflows : Les organisations peuvent utiliser les deep agents pour automatiser des processus métier complexes et multi-étapes nécessitant raisonnement, adaptation et coordination entre multiples systèmes.
Les deep agents représentent une évolution fondamentale de la conception des systèmes IA pour les tâches complexes. En combinant outils de planification, sous-agents, gestion de fichiers et prompts système détaillés, on crée des agents capables d’un raisonnement soutenu et d’une exécution sur la durée. Il ne s’agit pas de révolutions algorithmiques, mais d’une ingénierie réfléchie qui exploite les forces des modèles de langage tout en compensant leurs limites.
L’émergence de Claude Code, Manus et Deep Research d’OpenAI montre que ce schéma architectural devient le standard pour les applications IA avancées. Pour les organisations et développeurs qui construisent la prochaine génération d’automatisation IA, comprendre l’architecture deep agent est essentiel. Que l’on parte de zéro ou que l’on utilise des plateformes comme FlowHunt ou des packages open source, les principes restent : planifier avec soin, déléguer intelligemment, gérer efficacement le contexte et guider le comportement par des prompts exhaustifs.
À mesure que les capacités de l’IA progressent, les deep agents deviendront probablement la norme pour toute tâche nécessitant raisonnement soutenu et exécution complexe. Les organisations qui maîtrisent cette architecture seront les mieux placées pour exploiter tout le potentiel de l’IA.
Découvrez comment FlowHunt automatise tous vos workflows IA et SEO : de la recherche et la génération de contenu à la publication et l'analyse — le tout au même endroit.
Arshia est ingénieure en workflows d'IA chez FlowHunt. Avec une formation en informatique et une passion pour l’IA, elle se spécialise dans la création de workflows efficaces intégrant des outils d'IA aux tâches quotidiennes, afin d’accroître la productivité et la créativité.

Créez, déployez et gérez des agents IA sophistiqués grâce à la plateforme intégrée de FlowHunt pour l’orchestration d’agents et l’automatisation des workflows.
Découvrez comment construire et configurer des Deep Agents dans FlowHunt — des agents autonomes et multi-étapes capables de raisonnement complexe, d'utilisation...

Découvrez comment les agents IA utilisent la planification pour surmonter les limites de la fenêtre de contexte et améliorer l’exécution des tâches. Explorez l’...

Découvrez comment Deep Agent CLI révolutionne les workflows de développement avec des systèmes de mémoire persistante, permettant aux agents IA d'apprendre aux ...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.