
Serveur MCP OpenCV
Le serveur MCP OpenCV relie les puissants outils de traitement d’images et de vidéos d’OpenCV aux assistants IA et aux plateformes de développement via le Model...
5 min de lecture
OpenCV
MCP Server
+4
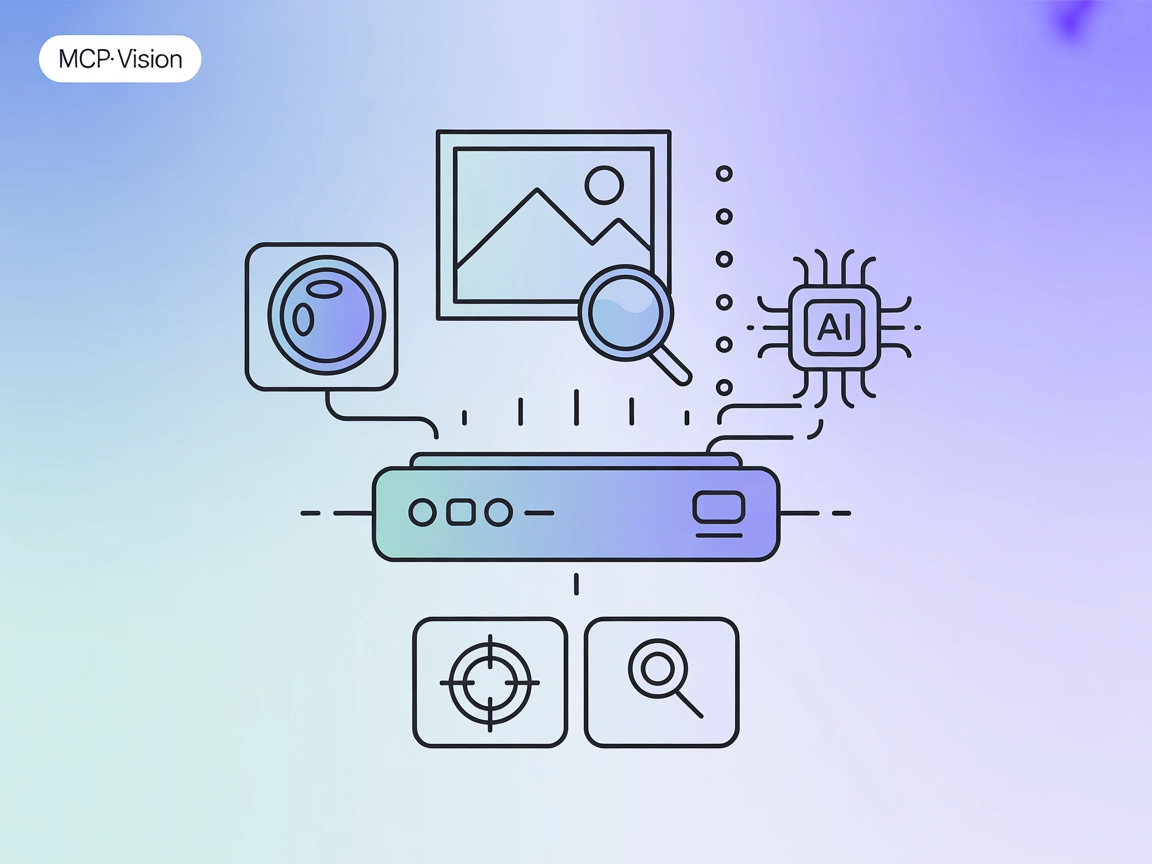
Ajoutez la vision par ordinateur à vos workflows IA avec mcp-vision : détection d’objets et analyse d’images alimentées par HuggingFace sous forme de serveur MCP pour FlowHunt et des assistants multimodaux.
FlowHunt fournit une couche de sécurité supplémentaire entre vos systèmes internes et les outils d'IA, vous donnant un contrôle granulaire sur les outils accessibles depuis vos serveurs MCP. Les serveurs MCP hébergés dans notre infrastructure peuvent être intégrés de manière transparente avec le chatbot de FlowHunt ainsi qu'avec les plateformes d'IA populaires comme ChatGPT, Claude et divers éditeurs d'IA.
Le serveur MCP “mcp-vision” est un serveur Model Context Protocol (MCP) qui expose les modèles de vision par ordinateur HuggingFace—comme la détection d’objets zero-shot—en tant qu’outils pour enrichir les capacités visuelles des grands modèles de langage ou des modèles vision-langage. En connectant des assistants IA à de puissants modèles de vision, mcp-vision permet la détection d’objets et l’analyse d’images directement au sein des workflows de développement. Cela autorise les LLMs et autres clients IA à interroger, traiter et analyser des images de façon programmatique, simplifiant ainsi l’automatisation, la standardisation et l’extension des interactions basées sur la vision dans les applications. Le serveur fonctionne aussi bien sur GPU que sur CPU et est conçu pour une intégration aisée avec les plateformes IA populaires.
Aucun modèle de prompt spécifique n’est mentionné dans la documentation ou les fichiers du dépôt.
Commencez votre essai gratuit aujourd'hui et voyez les résultats en quelques jours.
Aucune ressource MCP explicite n’est documentée ou listée dans le dépôt.
locate_objects
Détecte et localise les objets dans une image à l’aide de l’un des pipelines de détection d’objets zero-shot disponibles via HuggingFace. Les entrées incluent le chemin de l’image, une liste de labels candidats, et éventuellement le nom du modèle. Retourne une liste d’objets détectés au format standard.
zoom_to_object
Zoome sur un objet précis dans une image en recadrant l’image sur la boîte englobante de l’objet avec le meilleur score de détection. Les entrées incluent le chemin de l’image, un label à chercher, et éventuellement le nom du modèle. Retourne une image recadrée ou None.
Recevez gratuitement les derniers conseils, tendances et offres.
Aucune instruction d’installation pour Windsurf n’est fournie dans le dépôt.
git clone git@github.com:groundlight/mcp-vision.git
cd mcp-vision
make build-docker
claude_desktop_config.json et ajoutez ce qui suit sous mcpServers :"mcpServers": {
"mcp-vision": {
"command": "docker",
"args": ["run", "-i", "--rm", "--runtime=nvidia", "--gpus", "all", "mcp-vision"],
"env": {}
}
}
"mcpServers": {
"mcp-vision": {
"command": "docker",
"args": ["run", "-i", "--rm", "mcp-vision"],
"env": {}
}
}
"mcpServers": {
"mcp-vision": {
"command": "docker",
"args": ["run", "-i", "--rm", "--runtime=nvidia", "--gpus", "all", "groundlight/mcp-vision:latest"],
"env": {}
}
}
Aucune instruction d’installation pour Cursor n’est fournie dans le dépôt.
Aucune instruction d’installation pour Cline n’est fournie dans le dépôt.
Utiliser MCP dans FlowHunt
Pour intégrer les serveurs MCP à votre workflow FlowHunt, commencez par ajouter le composant MCP à votre flow et connectez-le à votre agent IA :

Cliquez sur le composant MCP pour ouvrir le panneau de configuration. Dans la section de configuration MCP système, indiquez les détails de votre serveur MCP avec ce format JSON :
{
"mcp-vision": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Une fois configuré, l’agent IA pourra utiliser ce MCP comme outil, avec accès à toutes ses fonctions et capacités. N’oubliez pas de remplacer “mcp-vision” par le vrai nom de votre serveur MCP et l’URL par celle de votre serveur MCP.
| Section | Disponibilité | Détails/Remarques |
|---|---|---|
| Vue d’ensemble | ✅ | Modèles de vision HuggingFace comme outils pour LLMs via MCP |
| Liste des prompts | ⛔ | Aucun modèle de prompt documenté |
| Liste des ressources | ⛔ | Aucune ressource explicite listée |
| Liste des outils | ✅ | locate_objects, zoom_to_object |
| Sécurisation des clés API | ⛔ | Pas d’instructions sur les clés API |
| Support du sampling (moins important en éval.) | ⛔ | Non mentionné |
Dans l’ensemble, mcp-vision propose une intégration directe et utile avec les modèles de vision HuggingFace mais manque de documentation sur les ressources, modèles de prompt, ou fonctionnalités avancées MCP comme roots ou sampling. Son installation est bien documentée pour Claude Desktop mais pas pour les autres plateformes.
mcp-vision est un serveur MCP ciblé et pratique pour ajouter de l’intelligence visuelle aux workflows IA, surtout dans les environnements compatibles Docker. Sa force principale réside dans ses outils clairs et son installation directe pour Claude Desktop, mais il gagnerait à enrichir sa documentation, notamment sur les ressources, modèles de prompts, et le support d’autres plateformes ou fonctions MCP avancées.
| Dispose d’une LICENCE | ✅ MIT |
|---|---|
| Au moins un outil | ✅ |
| Nombre de Forks | 0 |
| Nombre de Stars | 23 |
mcp-vision est un serveur open source Model Context Protocol qui expose les modèles de vision par ordinateur HuggingFace comme outils pour assistants IA et LLMs, permettant la détection d’objets, le recadrage d’images, et plus encore dans vos workflows IA.
mcp-vision propose des outils comme locate_objects (pour la détection d’objets zero-shot dans les images) et zoom_to_object (pour recadrer une image sur un objet détecté), accessibles via l’interface MCP.
Utilisez mcp-vision pour la détection automatisée d’objets, l’automatisation de workflows basés sur la vision, l’exploration interactive d’images, et pour doter les agents IA de raisonnement et d’analyse visuelle.
Ajoutez le composant MCP à votre flux FlowHunt et renseignez les détails du serveur mcp-vision dans le panneau de configuration, au format JSON fourni. Vérifiez que votre serveur MCP tourne et est accessible depuis FlowHunt.
Aucune clé API ni identification spéciale n’est requise pour exécuter mcp-vision selon la documentation actuelle. Il suffit de configurer votre environnement Docker et de rendre le serveur accessible.
Boostez vos agents IA avec la détection d’objets et l’analyse d’images grâce à mcp-vision. Branchez-le dans vos flux FlowHunt pour un raisonnement multimodal transparent.
Le serveur MCP OpenCV relie les puissants outils de traitement d’images et de vidéos d’OpenCV aux assistants IA et aux plateformes de développement via le Model...
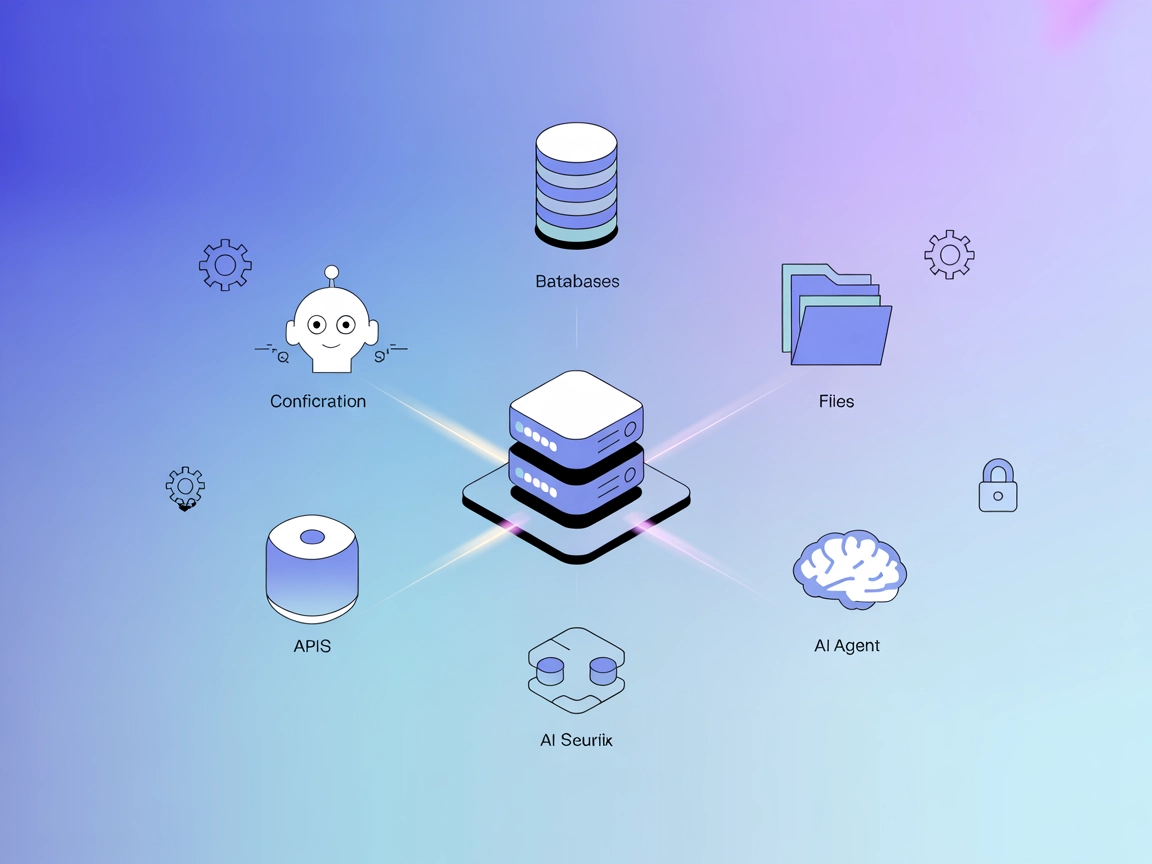
Le serveur ModelContextProtocol (MCP) agit comme un pont entre les agents IA et les sources de données externes, API et services, permettant aux utilisateurs de...
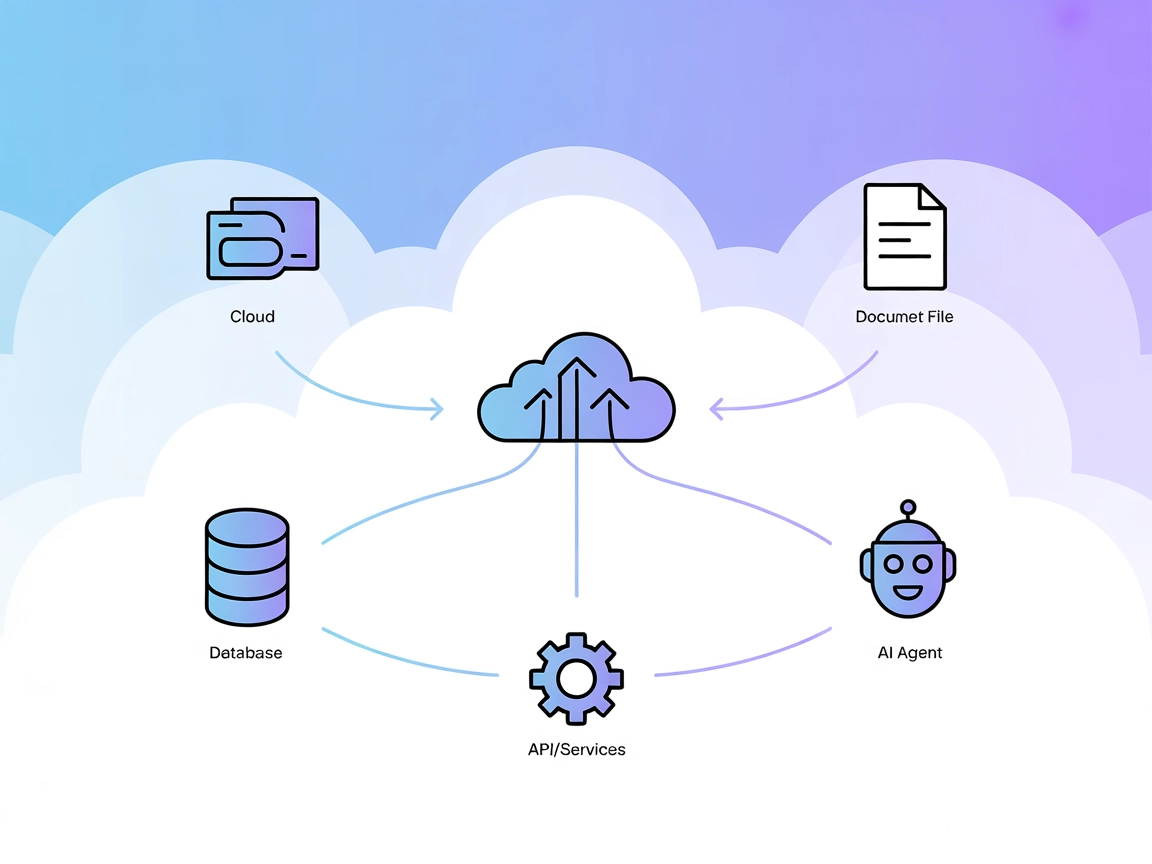
Le serveur Model Context Protocol (MCP) fait le lien entre les assistants IA et des sources de données externes, des API et des services, permettant une intégra...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.