
MLflow
MLflow is an open-source platform designed to streamline and manage the machine learning (ML) lifecycle. It provides tools for experiment tracking, code packagi...
6 min read
MLflow
Machine Learning
+3
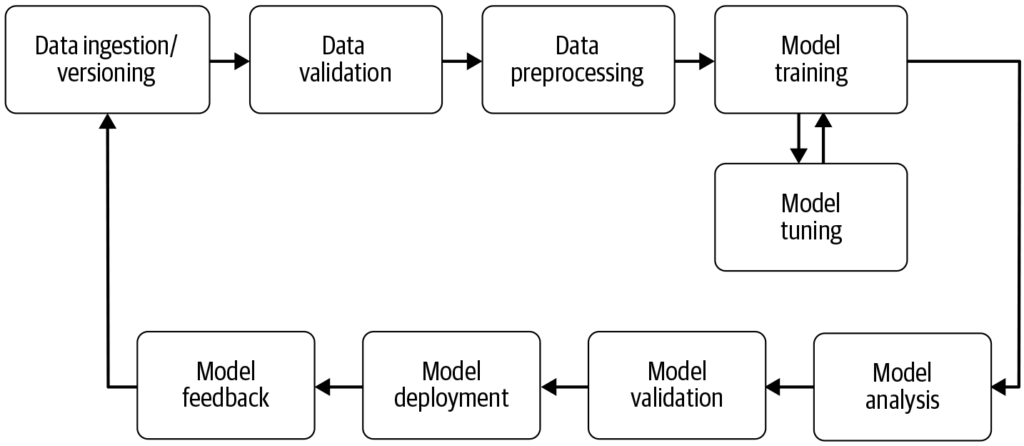
A machine learning pipeline is an automated workflow that streamlines and standardizes the development, training, evaluation, and deployment of machine learning models, transforming raw data into actionable insights efficiently and at scale.
A machine learning pipeline is an automated workflow streamlining the development, training, evaluation, and deployment of models. It enhances efficiency, reproducibility, and scalability, facilitating tasks from data collection to model deployment and maintenance.
A machine learning pipeline is an automated workflow that encompasses a series of steps involved in the development, training, evaluation, and deployment of machine learning models. It is designed to streamline and standardize the processes required to transform raw data into actionable insights through machine learning algorithms. The pipeline approach allows for efficient handling of data, model training, and deployment, making it easier to manage and scale machine learning operations.
Source: Building Machine Learning
Data Collection: The initial stage where data is gathered from various sources such as databases, APIs, or files. Data collection is a methodical practice aimed at acquiring meaningful information to build a consistent and complete dataset for a specific business purpose. This raw data is essential for building machine learning models but often requires preprocessing to be useful. As highlighted by AltexSoft, data collection involves the systematic accumulation of information to support analytics and decision-making. This process is crucial as it lays the foundation for all subsequent steps in the pipeline and is often continuous to ensure models are trained on relevant and up-to-date data.
Data Preprocessing: Raw data is cleaned and transformed into a suitable format for model training. Common preprocessing steps include handling missing values, encoding categorical variables, scaling numerical features, and splitting the data into training and testing sets. This stage ensures that the data is in the correct format and free from any inconsistencies that could affect model performance.
Feature Engineering: Creating new features or selecting relevant features from the data to improve the model’s predictive power. This step may require domain-specific knowledge and creativity. Feature engineering is a creative process that transforms raw data into meaningful features that represent the underlying problem better and increases the performance of machine learning models.
Model Selection: The appropriate machine learning algorithm(s) are chosen based on the problem type (e.g., classification, regression), data characteristics, and performance requirements. Hyperparameter tuning may also be considered in this stage. Selecting the right model is critical as it influences the accuracy and efficiency of the predictions.
Model Training: The selected model(s) are trained using the training dataset. This involves learning the underlying patterns and relationships within the data. Pre-trained models may also be used instead of training a new model from scratch. Training is a vital step where the model learns from the data to make informed predictions.
Model Evaluation: After training, the model’s performance is assessed using a separate testing dataset or through cross-validation. Evaluation metrics depend on the specific problem but may include accuracy, precision, recall, F1-score, mean squared error, among others. This step is crucial to ensure the model will perform well on unseen data.
Model Deployment: Once a satisfactory model is developed and evaluated, it can be deployed into a production environment to make predictions on new, unseen data. Deployment may involve creating APIs and integrating with other systems. Deployment is the final stage of the pipeline where the model is made accessible for real-world use.
Monitoring and Maintenance: Post-deployment, it is crucial to continuously monitor the model’s performance and retrain it as needed to adapt to changing data patterns, ensuring the model remains accurate and reliable in real-world settings. This ongoing process ensures that the model remains relevant and accurate over time.
Natural Language Processing bridges human-computer interaction. Discover its key aspects, workings, and applications today!") (NLP): NLP tasks often involve multiple repeatable steps such as data ingestion, text cleaning, tokenization, and sentiment analysis. Pipelines help modularize these steps, allowing for easy modifications and updates without affecting other components.
Predictive Maintenance: In industries like manufacturing, pipelines can be used to predict equipment failures by analyzing sensor data, thus enabling proactive maintenance and reducing downtime.
Finance: Pipelines can automate the processing of financial data to detect fraud, assess credit risks, or predict stock prices, enhancing decision-making processes.
Healthcare: In healthcare, pipelines can process medical images or patient records to assist in diagnostics or predict patient outcomes, improving treatment strategies.
Machine learning pipelines are integral to AI and automation](https://www.flowhunt.io “Build AI tools and chatbots with FlowHunt’s no-code platform. Explore templates, components, and seamless automation. Book a demo today!”) by providing a structured framework to automate machine learning tasks. In the realm of AI automation , pipelines ensure that models are trained and deployed efficiently, enabling AI systems like [chatbots to learn and adapt to new data without manual intervention. This automation is crucial for scaling AI applications and ensuring they deliver consistent and reliable performance across various domains. By leveraging pipelines, organizations can enhance their AI capabilities and ensure that their machine learning models remain relevant and effective in changing environments.
Research on Machine Learning Pipeline
“Deep Pipeline Embeddings for AutoML” by Sebastian Pineda Arango and Josif Grabocka (2023) focuses on the challenges of optimizing machine learning pipelines in Automated Machine Learning (AutoML). This paper introduces a novel neural architecture designed to capture deep interactions between pipeline components. The authors propose embedding pipelines into latent representations via a unique per-component encoder mechanism. These embeddings are utilized within a Bayesian Optimization framework to search for optimal pipelines. The paper emphasizes the use of meta-learning to fine-tune the pipeline embedding network’s parameters, demonstrating state-of-the-art results in pipeline optimization across multiple datasets. Read more .
“AVATAR — Machine Learning Pipeline Evaluation Using Surrogate Model” by Tien-Dung Nguyen et al. (2020) addresses the time-consuming evaluation of machine learning pipelines during AutoML processes. The study critiques traditional methods like Bayesian and genetic-based optimizations for their inefficiency. To counter this, the authors present AVATAR, a surrogate model that efficiently evaluates pipeline validity without execution. This approach significantly accelerates the composition and optimization of complex pipelines by filtering out invalid ones early in the process. Read more .
“Data Pricing in Machine Learning Pipelines” by Zicun Cong et al. (2021) explores the crucial role of data in machine learning pipelines and the necessity of data pricing to facilitate collaboration among multiple stakeholders. The paper surveys the latest developments in data pricing within the context of machine learning, focusing on its importance across various stages of the pipeline. It provides insights into pricing strategies for training data collection, collaborative model training, and the delivery of machine learning services, highlighting the formation of a dynamic ecosystem. Read more .
A machine learning pipeline is an automated sequence of steps—from data collection and preprocessing to model training, evaluation, and deployment—that streamlines and standardizes the process of building and maintaining machine learning models.
Key components include data collection, data preprocessing, feature engineering, model selection, model training, model evaluation, model deployment, and ongoing monitoring and maintenance.
Machine learning pipelines provide modularization, efficiency, reproducibility, scalability, improved collaboration, and easier deployment of models into production environments.
Use cases include natural language processing (NLP), predictive maintenance in manufacturing, financial risk assessment and fraud detection, and healthcare diagnostics.
Challenges include ensuring data quality, managing pipeline complexity, integrating with existing systems, and controlling costs related to computational resources and infrastructure.
Schedule a demo to discover how FlowHunt can help you automate and scale your machine learning workflows with ease.
MLflow is an open-source platform designed to streamline and manage the machine learning (ML) lifecycle. It provides tools for experiment tracking, code packagi...

Kubeflow is an open-source machine learning (ML) platform on Kubernetes, simplifying the deployment, management, and scaling of ML workflows. It offers a suite ...
Model Chaining is a machine learning technique where multiple models are linked sequentially, with each model’s output serving as the next model’s input. This a...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.