
OpenCV MCP Server
L'OpenCV MCP Server collega le potenti funzionalità di elaborazione immagini e video di OpenCV con assistenti AI e piattaforme di sviluppo tramite il Model Cont...
4 min di lettura
OpenCV
MCP Server
+4
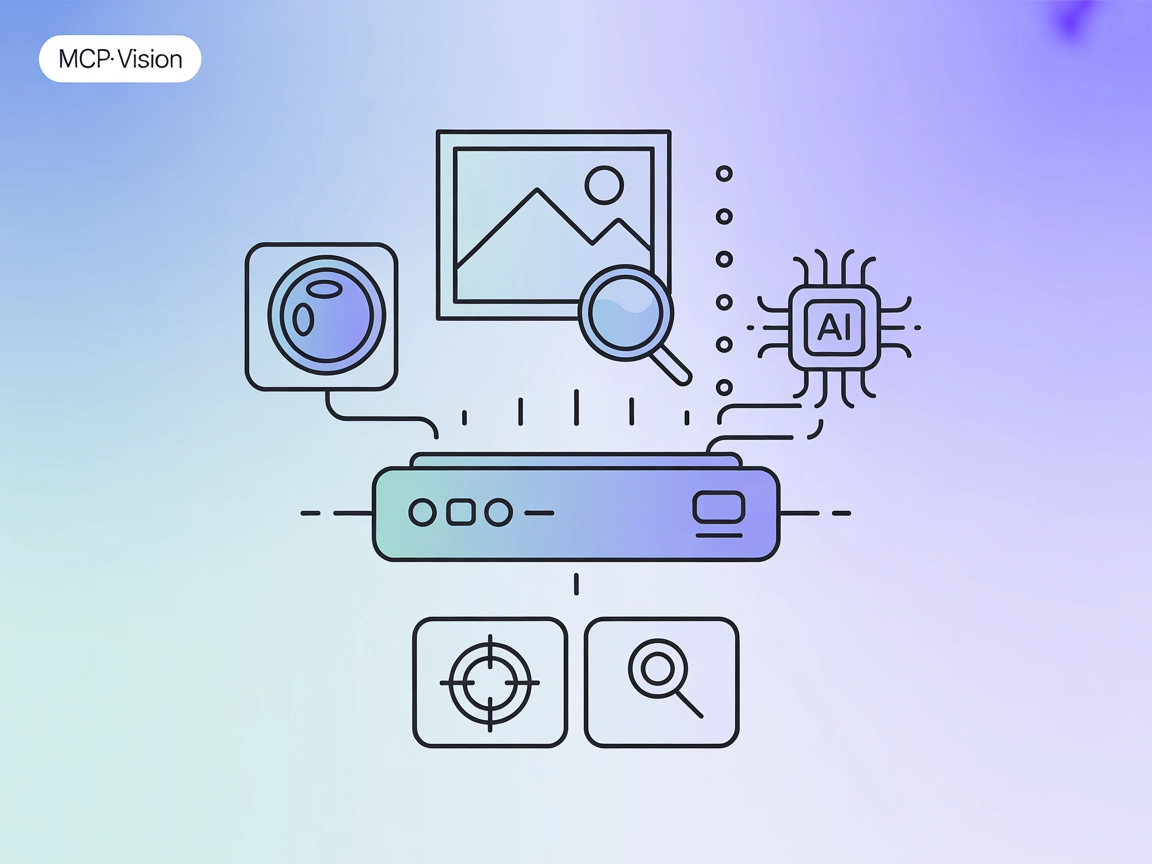
Aggiungi la visione artificiale ai tuoi workflow AI con mcp-vision: rilevamento oggetti e analisi immagini alimentati da HuggingFace come server MCP per FlowHunt e assistenti multimodali.
FlowHunt fornisce un livello di sicurezza aggiuntivo tra i tuoi sistemi interni e gli strumenti AI, dandoti controllo granulare su quali strumenti sono accessibili dai tuoi server MCP. I server MCP ospitati nella nostra infrastruttura possono essere integrati perfettamente con il chatbot di FlowHunt così come con le piattaforme AI popolari come ChatGPT, Claude e vari editor AI.
Il server MCP “mcp-vision” è un server Model Context Protocol (MCP) che espone i modelli di visione artificiale di HuggingFace—come il rilevamento di oggetti zero-shot—come strumenti per potenziare le capacità visive di large language model o modelli vision-language. Collegando assistenti AI a potenti modelli di visione artificiale, mcp-vision consente attività come il rilevamento oggetti e l’analisi delle immagini direttamente nei workflow di sviluppo. Questo permette a LLM e altri client AI di interrogare, elaborare e analizzare immagini in modo programmato, facilitando l’automatizzazione, la standardizzazione e l’estensione delle interazioni visive nelle applicazioni. Il server è adatto sia ad ambienti GPU che CPU ed è progettato per una facile integrazione con le principali piattaforme AI.
Nessun template di prompt specifico è menzionato nella documentazione o nei file del repository.
Inizia oggi la tua prova gratuita e vedi i risultati in pochi giorni.
Nessuna risorsa MCP esplicita è documentata o elencata nel repository.
locate_objects
Rileva e individua oggetti in un’immagine utilizzando una delle pipeline di rilevamento oggetti zero-shot disponibili tramite HuggingFace. Gli input includono il percorso dell’immagine, una lista di etichette candidate e un nome modello opzionale. Restituisce una lista di oggetti rilevati in formato standard.
zoom_to_object
Esegue lo zoom su uno specifico oggetto in un’immagine ritagliando l’immagine sulla bounding box dell’oggetto con il punteggio di rilevamento più alto. Gli input includono il percorso dell’immagine, un’etichetta da cercare e un nome modello opzionale. Restituisce un’immagine ritagliata o None.
Ricevi gratuitamente gli ultimi consigli, tendenze e offerte.
Nessuna istruzione di configurazione per Windsurf è fornita nel repository.
git clone git@github.com:groundlight/mcp-vision.git
cd mcp-vision
make build-docker
claude_desktop_config.json e aggiungi quanto segue sotto mcpServers:"mcpServers": {
"mcp-vision": {
"command": "docker",
"args": ["run", "-i", "--rm", "--runtime=nvidia", "--gpus", "all", "mcp-vision"],
"env": {}
}
}
"mcpServers": {
"mcp-vision": {
"command": "docker",
"args": ["run", "-i", "--rm", "mcp-vision"],
"env": {}
}
}
"mcpServers": {
"mcp-vision": {
"command": "docker",
"args": ["run", "-i", "--rm", "--runtime=nvidia", "--gpus", "all", "groundlight/mcp-vision:latest"],
"env": {}
}
}
Nessuna istruzione di configurazione per Cursor è fornita nel repository.
Nessuna istruzione di configurazione per Cline è fornita nel repository.
Uso di MCP in FlowHunt
Per integrare i server MCP nel tuo workflow FlowHunt, inizia aggiungendo il componente MCP al tuo flusso e collegandolo al tuo agente AI:

Fai clic sul componente MCP per aprire il pannello di configurazione. Nella sezione di configurazione MCP di sistema, inserisci i dettagli del tuo server MCP utilizzando questo formato JSON:
{
"mcp-vision": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Una volta configurato, l’agente AI potrà utilizzare questo MCP come strumento con accesso a tutte le sue funzioni e capacità. Ricorda di cambiare “mcp-vision” con il vero nome del tuo server MCP e di sostituire la URL con la URL del tuo server MCP.
| Sezione | Disponibilità | Dettagli/Note |
|---|---|---|
| Panoramica | ✅ | Modelli di visione HuggingFace come strumenti per LLM tramite MCP |
| Elenco dei Prompt | ⛔ | Nessun template di prompt documentato |
| Elenco delle Risorse | ⛔ | Nessuna risorsa esplicita elencata |
| Elenco degli Strumenti | ✅ | locate_objects, zoom_to_object |
| Protezione delle API Key | ⛔ | Nessuna istruzione sulle API key |
| Supporto Sampling (meno importante in valutazione) | ⛔ | Non menzionato |
Nel complesso, mcp-vision offre un’integrazione utile e diretta con i modelli di visione HuggingFace ma manca di documentazione su risorse, template di prompt o funzionalità MCP avanzate come roots o sampling. La configurazione è ben documentata per Claude Desktop ma non per altre piattaforme.
mcp-vision è un server MCP focalizzato e pratico per aggiungere intelligenza visiva ai workflow AI, specialmente in ambienti che supportano Docker. I suoi principali punti di forza sono gli strumenti chiari e la configurazione lineare per Claude Desktop, ma trarrebbe beneficio da una documentazione più ricca, in particolare su risorse, template di prompt e supporto per altre piattaforme e funzionalità MCP avanzate.
| Ha una LICENSE | ✅ MIT |
|---|---|
| Ha almeno uno strumento | ✅ |
| Numero di Fork | 0 |
| Numero di Stelle | 23 |
mcp-vision è un server Model Context Protocol open-source che espone i modelli di visione artificiale di HuggingFace come strumenti per assistenti AI e LLM, abilitando funzioni come rilevamento oggetti, ritaglio immagini e altro ancora nei tuoi workflow AI.
mcp-vision offre strumenti come locate_objects (per il rilevamento di oggetti zero-shot in immagini) e zoom_to_object (per ritagliare immagini sugli oggetti rilevati), accessibili tramite l’interfaccia MCP.
Usa mcp-vision per il rilevamento automatico di oggetti, automazione di workflow basati sulla visione, esplorazione interattiva delle immagini e per aumentare gli agenti AI con capacità di ragionamento e analisi visiva.
Aggiungi il componente MCP al tuo flusso FlowHunt e inserisci i dettagli del server mcp-vision nel pannello di configurazione utilizzando il formato JSON fornito. Assicurati che il tuo server MCP sia in esecuzione e raggiungibile da FlowHunt.
Secondo la documentazione attuale non è richiesta nessuna API key o credenziale speciale per eseguire mcp-vision. Basta che il tuo ambiente Docker sia configurato e il server sia accessibile.
Potenzia i tuoi agenti AI con il rilevamento oggetti e l’analisi delle immagini usando mcp-vision. Inseriscilo nei tuoi flussi FlowHunt per un ragionamento multimodale senza interruzioni.
L'OpenCV MCP Server collega le potenti funzionalità di elaborazione immagini e video di OpenCV con assistenti AI e piattaforme di sviluppo tramite il Model Cont...
Il Server ModelContextProtocol (MCP) funge da ponte tra agenti AI e fonti dati esterne, API e servizi, consentendo agli utenti FlowHunt di costruire assistenti ...
Il server MCP interactive-mcp consente flussi di lavoro AI con l'intervento umano, collegando agenti AI con utenti e sistemi esterni. Supporta sviluppo cross-pl...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.