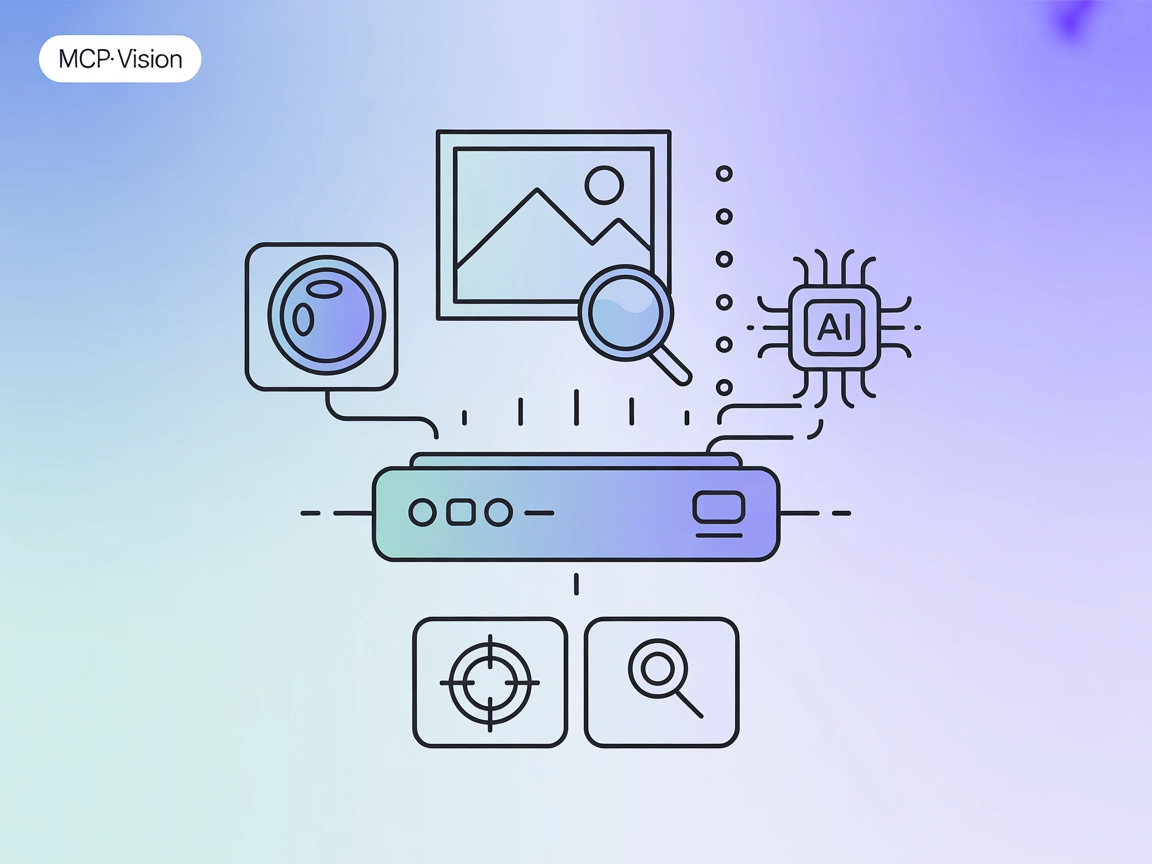

OpenCV MCPサーバー
OpenCV MCPサーバーは、OpenCVの強力な画像・動画処理ツールをAIアシスタントや開発者プラットフォームとModel Context Protocol(MCP)経由で連携します。画像操作、物体検出、動画解析などの高度なコンピュータビジョンワークフローを、お気に入りの開発環境内で直接実現できます。...
1 分で読める
OpenCV
MCP Server
+4
FlowHuntは、お客様の内部システムとAIツールの間に追加のセキュリティレイヤーを提供し、MCPサーバーからアクセス可能なツールをきめ細かく制御できます。私たちのインフラストラクチャーでホストされているMCPサーバーは、FlowHuntのチャットボットや、ChatGPT、Claude、さまざまなAIエディターなどの人気のAIプラットフォームとシームレスに統合できます。
「mcp-vision」MCP サーバーは、Model Context Protocol(MCP)サーバーであり、HuggingFace のコンピュータビジョンモデル(ゼロショット物体検出など)を、LLM やビジョンランゲージモデルの視覚機能を強化するツールとして公開します。AI アシスタントと強力なコンピュータビジョンモデルを接続することで、mcp-vision は物体検出や画像解析などを開発ワークフローの中で直接実行可能にします。これにより、LLM や他の AI クライアントが画像をプログラム的に問い合わせ、処理し、解析できるようになり、アプリケーションにおける視覚的なやり取りの自動化・標準化・拡張が容易になります。本サーバーは GPU・CPU 環境の両方に対応し、主要な AI プラットフォームとの統合も簡単に設計されています。
ドキュメントやリポジトリには特定のプロンプトテンプレートは記載されていません。
リポジトリには明示的な MCP リソースは記載またはリストされていません。
locate_objects
HuggingFace が提供するゼロショット物体検出パイプラインを利用し、画像内の物体を検出・特定します。入力には画像パス、候補ラベルリスト、オプションでモデル名を指定可能。標準フォーマットで検出物体リストを返します。
zoom_to_object
画像内の特定の物体について、検出スコアが最も高い物体のバウンディングボックスに画像をクロップしズームします。入力は画像パス、検索するラベル、オプションでモデル名。クロップ済み画像または None を返します。
最新のヒント、トレンド、お得な情報を無料で入手。
リポジトリに Windsurf 用セットアップ手順はありません。
git clone git@github.com:groundlight/mcp-vision.git
cd mcp-vision
make build-docker
claude_desktop_config.json を開き、以下を mcpServers に追加します。"mcpServers": {
"mcp-vision": {
"command": "docker",
"args": ["run", "-i", "--rm", "--runtime=nvidia", "--gpus", "all", "mcp-vision"],
"env": {}
}
}
"mcpServers": {
"mcp-vision": {
"command": "docker",
"args": ["run", "-i", "--rm", "mcp-vision"],
"env": {}
}
}
"mcpServers": {
"mcp-vision": {
"command": "docker",
"args": ["run", "-i", "--rm", "--runtime=nvidia", "--gpus", "all", "groundlight/mcp-vision:latest"],
"env": {}
}
}
リポジトリに Cursor 用セットアップ手順はありません。
リポジトリに Cline 用セットアップ手順はありません。
FlowHunt で MCP を利用する
FlowHunt のワークフローに MCP サーバーを組み込むには、まず MCP コンポーネントをフローに追加し、AI エージェントと接続します。

MCP コンポーネントをクリックして構成パネルを開き、システム MCP 設定欄で以下のような JSON 形式で MCP サーバー情報を入力してください:
{
"mcp-vision": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
設定後、AI エージェントはこの MCP のすべての機能・能力をツールとして利用できます。なお、“mcp-vision” はご自身の MCP サーバー名に、URL もご自身の MCP サーバーのものに置き換えてください。
| セクション | 対応状況 | 詳細・備考 |
|---|---|---|
| 概要 | ✅ | HuggingFace のコンピュータビジョンモデルを MCP 経由で LLM ツール化 |
| プロンプト一覧 | ⛔ | プロンプトテンプレートは未記載 |
| リソース一覧 | ⛔ | 明示的なリソースは未記載 |
| ツール一覧 | ✅ | locate_objects, zoom_to_object |
| API キーセキュリティ | ⛔ | API キー手順なし |
| サンプリングサポート(評価には重要ではない) | ⛔ | 記載なし |
全体として、mcp-vision は HuggingFace ビジョンモデルとの直接連携を提供しますが、リソースやプロンプトテンプレート、roots やサンプリング等の高度な MCP 機能に関するドキュメントは不足しています。Claude Desktop でのセットアップは詳細ですが、他プラットフォーム向け情報はありません。
mcp-vision は、特に Docker 対応環境で AI ワークフローに視覚知能を追加するための実用的で特化した MCP サーバーです。明確なツール提供と Claude Desktop 向けのシンプルなセットアップが強みですが、リソース・プロンプトテンプレート・他プラットフォーム対応・高度な MCP 機能に関するさらなるドキュメントが望まれます。
| ライセンスあり | ✅ MIT |
|---|---|
| ツールが少なくとも 1 つ | ✅ |
| フォーク数 | 0 |
| スター数 | 23 |
mcp-vision はオープンソースの Model Context Protocol サーバーで、HuggingFace のコンピュータビジョンモデルを AI アシスタントや LLM のツールとして提供し、AI ワークフローで物体検出や画像クロッピングなどを可能にします。
mcp-vision には locate_objects(画像内のゼロショット物体検出)や zoom_to_object(検出された物体への画像クロッピング)などのツールがあり、MCP インターフェース経由で利用できます。
mcp-vision は自動物体検出、ビジョンベースのワークフロー自動化、対話的な画像探索、AI エージェントの視覚推論・解析能力の強化などに利用できます。
FlowHunt のフローに MCP コンポーネントを追加し、構成パネルで提供された JSON フォーマットを使って mcp-vision サーバー情報を入力します。MCP サーバーが稼働中で FlowHunt からアクセス可能であることを確認してください。
現在のドキュメントによれば、mcp-vision の実行に API キーや特別な認証情報は必要ありません。Docker 環境の設定とサーバーへのアクセスができれば十分です。
OpenCV MCPサーバーは、OpenCVの強力な画像・動画処理ツールをAIアシスタントや開発者プラットフォームとModel Context Protocol(MCP)経由で連携します。画像操作、物体検出、動画解析などの高度なコンピュータビジョンワークフローを、お気に入りの開発環境内で直接実現できます。...

BlenderMCPはBlenderとClaudeなどのAIアシスタントを橋渡しし、Model Context Protocol(MCP)を通して自動化されたAI駆動の3Dモデリング、シーン作成、アセット管理を実現します。リアルタイムかつプロンプトベースの自動化と双方向AI通信で、Blenderのワークフローを強化しま...
画像生成 MCP サーバーは、Replicate Flux モデルを利用して、AI アシスタントやアプリケーションがオンデマンドでカスタム画像を生成できるようにし、自動化された創造的かつスケーラブルなビジュアルコンテンツ生成ワークフローを実現します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.