
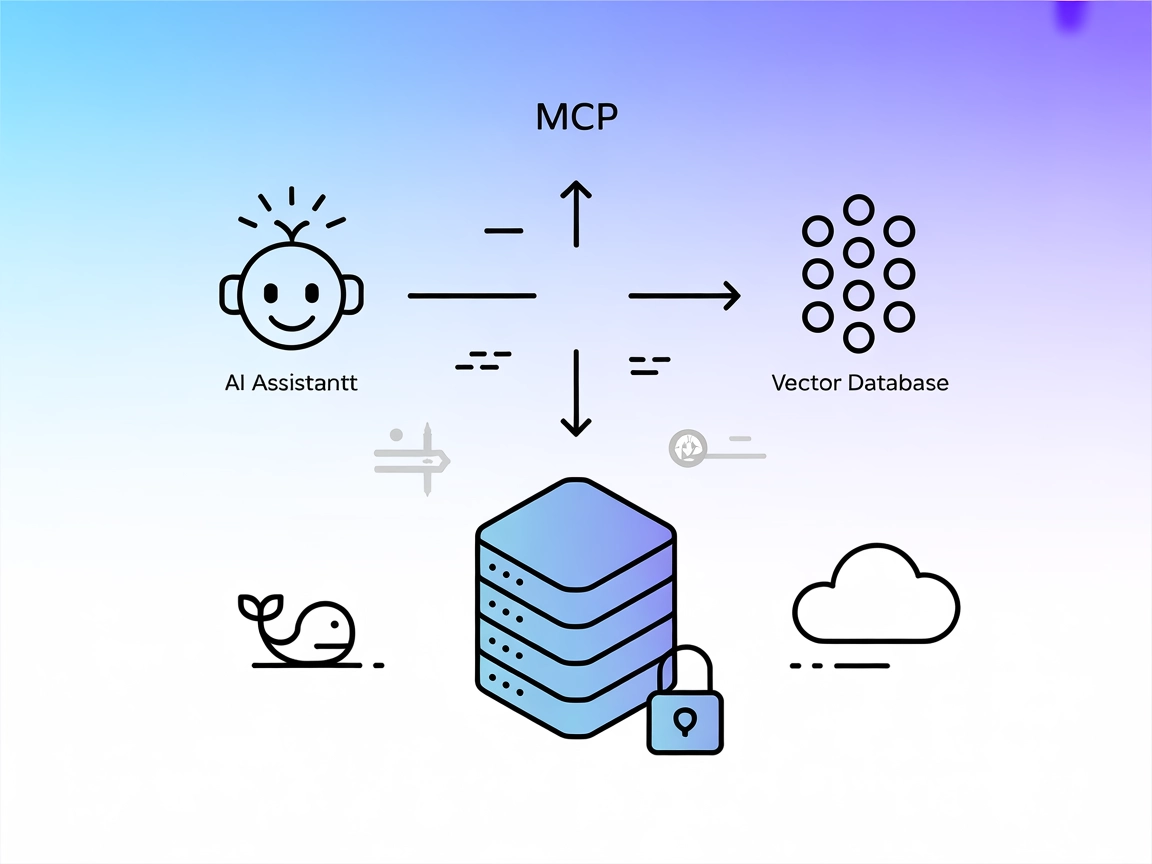
Pinecone Assistant MCP Server
The Pinecone Assistant MCP Server bridges AI assistants and Pinecone's vector database, enabling semantic search, multi-result retrieval, and secure knowledge-b...
4 min read
AI
MCP Server
+5
FlowHunt provides an additional security layer between your internal systems and AI tools, giving you granular control over which tools are accessible from your MCP servers. MCP servers hosted in our infrastructure can be seamlessly integrated with FlowHunt's chatbot as well as popular AI platforms like ChatGPT, Claude, and various AI editors.
The Pinecone MCP (Model Context Protocol) Server is a specialized tool that connects AI assistants with Pinecone vector databases, enabling seamless reading and writing of data for enhanced development workflows. By serving as an intermediary, the Pinecone MCP Server allows AI clients to execute tasks such as semantic search, document retrieval, and database management within a Pinecone index. It supports operations like querying for similar records, managing documents, and upserting new embeddings. This capability is particularly valuable for applications involving Retrieval-Augmented Generation (RAG), as it streamlines the integration of contextual data into AI workflows and automates complex data interactions.
No explicit prompt templates are mentioned in the repository.
Start your free trial today and see results within days.
Get latest tips, trends, and deals for free.
{
"mcpServers": {
"pinecone-mcp": {
"command": "mcp-pinecone",
"args": []
}
}
}
Securing API keys with environment variables:
{
"mcpServers": {
"pinecone-mcp": {
"command": "mcp-pinecone",
"env": {
"PINECONE_API_KEY": "your_api_key"
},
"inputs": {
"index_name": "your_index"
}
}
}
}
pip install mcp-pinecone).{
"mcpServers": {
"pinecone-mcp": {
"command": "mcp-pinecone",
"args": []
}
}
}
{
"mcpServers": {
"pinecone-mcp": {
"command": "mcp-pinecone",
"args": []
}
}
}
{
"mcpServers": {
"pinecone-mcp": {
"command": "mcp-pinecone",
"args": []
}
}
}
Note: Always secure API keys and sensitive values with environment variables as shown above.
Using MCP in FlowHunt
To integrate MCP servers into your FlowHunt workflow, start by adding the MCP component to your flow and connecting it to your AI agent:

Click on the MCP component to open the configuration panel. In the system MCP configuration section, insert your MCP server details using this JSON format:
{
"pinecone-mcp": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Once configured, the AI agent is now able to use this MCP as a tool with access to all its functions and capabilities. Remember to change “pinecone-mcp” to whatever the actual name of your MCP server is and replace the URL with your own MCP server URL.
| Section | Availability | Details/Notes |
|---|---|---|
| Overview | ✅ | Describes Pinecone MCP’s vector DB integration |
| List of Prompts | ⛔ | No explicit prompt templates found |
| List of Resources | ✅ | Pinecone index, documents, records, stats |
| List of Tools | ✅ | semantic-search, read-document, list-documents, pinecone-stats, process-document |
| Securing API Keys | ✅ | Example provided with env variables in configuration |
| Sampling Support (less important in evaluation) | ⛔ | No mention or evidence found |
The Pinecone MCP Server is well-documented, exposes clear resources and tools, and includes solid instructions for integration and API key security. However, it lacks explicit prompt templates and documentation on sampling or roots support. Overall, it is a practical and valuable server for RAG and Pinecone workflows, though it could be improved with more workflow examples and advanced features.
Rating: 8/10
| Has a LICENSE | ✅ (MIT) |
|---|---|
| Has at least one tool | ✅ |
| Number of Forks | 25 |
| Number of Stars | 124 |
The Pinecone MCP Server connects AI assistants with Pinecone vector databases, enabling semantic search, document management, and embedding workflows within AI applications like FlowHunt.
It exposes tools for semantic search, reading and listing documents, retrieving index statistics, and processing documents into embeddings for upserting into the Pinecone index.
The server allows AI agents to retrieve relevant context from Pinecone, enabling LLMs to generate responses grounded in external knowledge sources.
Store your Pinecone API key and index name as environment variables in your configuration file, as shown in the integration instructions, to keep your credentials safe.
Common use cases include semantic search over large document collections, RAG pipelines, automated document chunking and embedding, and monitoring Pinecone index statistics.
Enable semantic search and Retrieval-Augmented Generation in FlowHunt by connecting your AI agents with Pinecone vector databases.
The Pinecone Assistant MCP Server bridges AI assistants and Pinecone's vector database, enabling semantic search, multi-result retrieval, and secure knowledge-b...
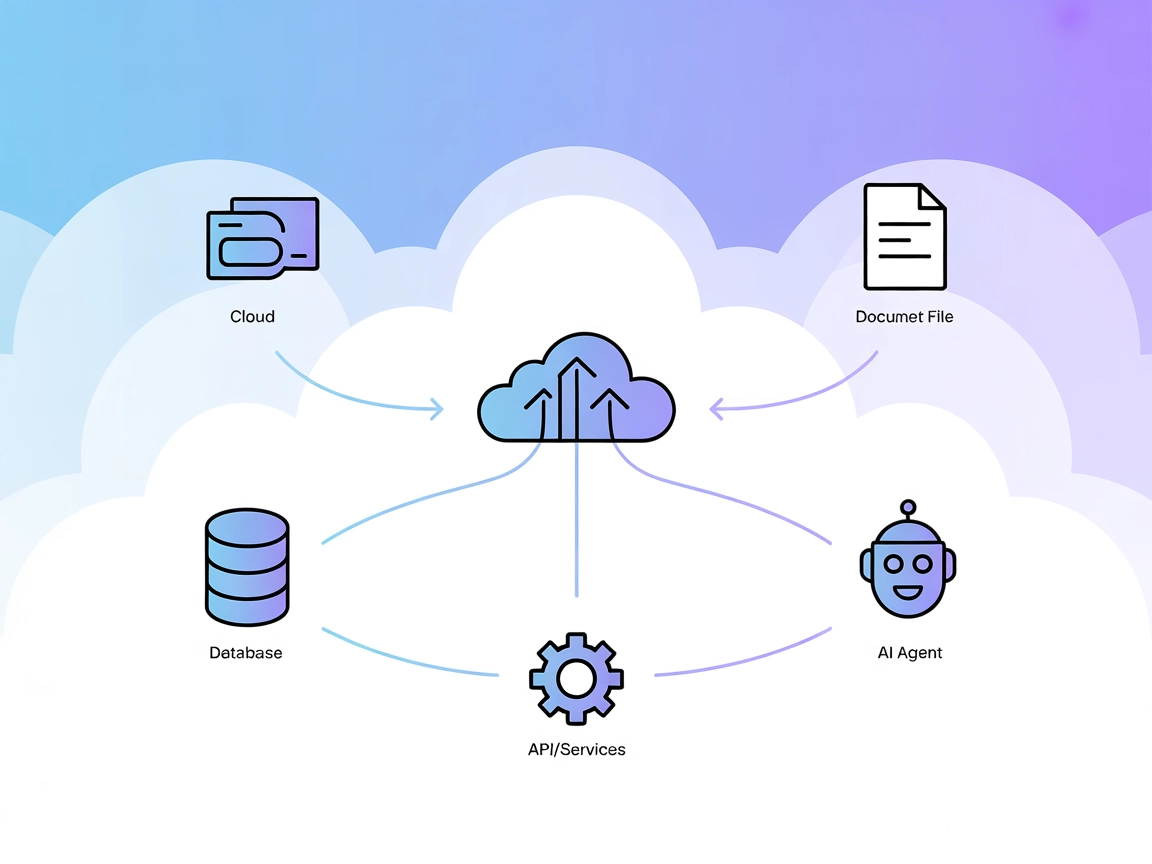
The Model Context Protocol (MCP) Server bridges AI assistants with external data sources, APIs, and services, enabling streamlined integration of complex workfl...
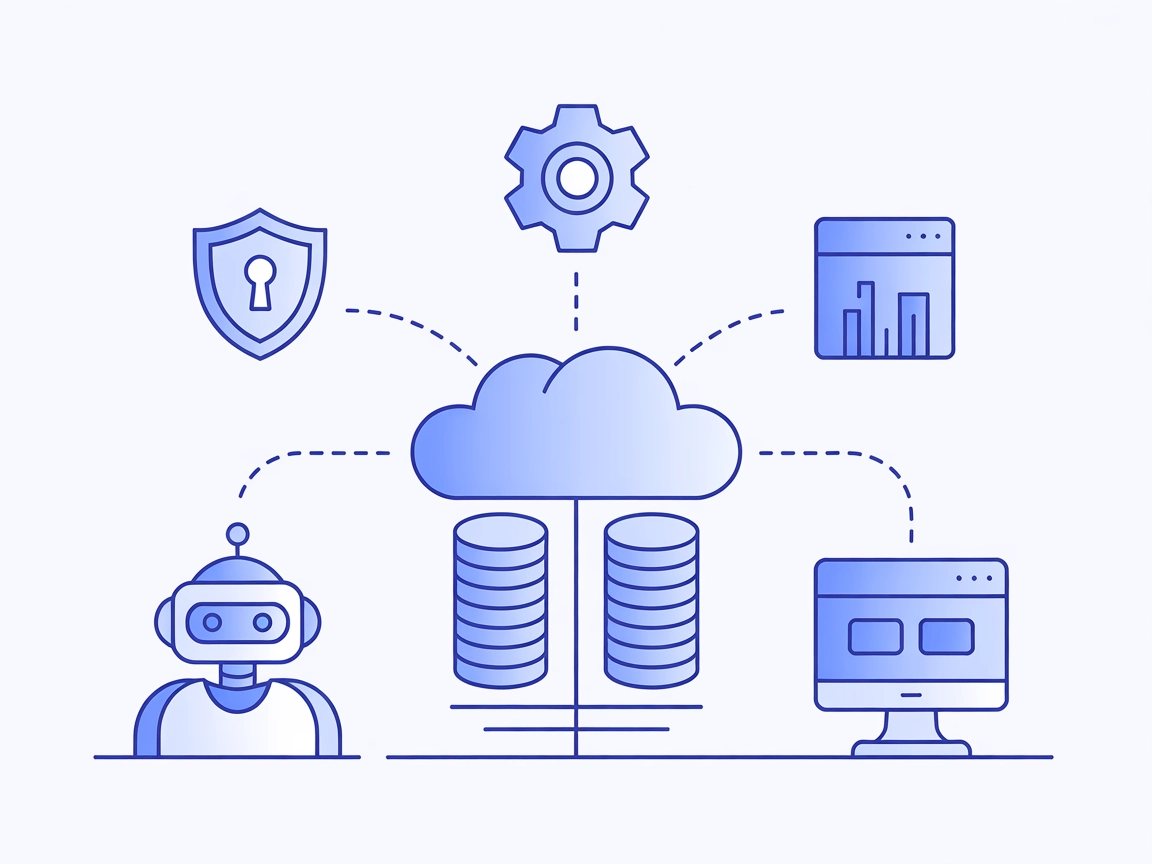
The kintone MCP Server enables seamless integration between AI assistants and the kintone platform, allowing AI tools to query, update, and interact with kinton...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.