“AI schrijft het meeste van onze code” klinkt als een startup-slogan. Kan het echt voor een bedrijfstoepassing — live klanten, live facturering, een monorepo waar een slechte merge geld kost? Bij QualityUnit is dat het geval. Hier is het tien-maanden spoor van bewijs en de regels die het werkend maken.
TL;DR: In tien maanden groeide agentgeschreven werk van de eerste experimentele PR’s naar 133 van 144 samengevoegde ontwikkelings-PR’s in mei (92%) — geverifieerd door een driedubbele forensische audit van alle 1.409 samengevoegde PR’s, tot commit-trailers en een handmatige inspectie van elke ongemarkeerde PR van 2026. Het gebeurde niet door “de AI code te laten schrijven”: het gebeurde door regels toe te voegen — een risiconiveau-harness-config, een gefaseerde agentpijplijn met begrensd beoordelingsloops, beschermde paden en een mens die elke merge controleert. De regels zijn het product. En met een contextengine die de agenten voedt, kost hetzelfde werk nu ongeveer 30% minder per taak (gemeten hier ).
Wat het daadwerkelijk kost
Geen hulpmiddel. Een pijplijn, een beleidsbestand en een poort — beheerd door harnext .
De pijplijn: gefaseerde agenten, één mens
De harness is harnext — QualityUnit’s open-source, provider-agnostische codeeringsagent-harness. In onze productie-monorepo voert elk probleem dat de pijplijn binnenkomt dezelfde reeks CI-geactiveerde agentstadia uit, waarbij de voortgang wordt bijgehouden via labels die een mens in één oogopslag kan lezen:

Twee details zijn belangrijker dan het aantal stadia. Het loop is begrensd: gebreken die in de beoordeling worden gevonden, gaan terug naar het implementatiestadium een beperkt aantal keren — agenten convergeren of escaleren naar een mens, ze thrash niet. Niets begint blind: voordat een regel wordt geschreven, moet de implementatieagent de conventies van het project laden en een bevestigingsblok uitzenden dat beoordelaars kunnen controleren.
Het beleidsbestand
Het andere deel is een machine-leesbaar beleid: elk pad in de repo ingedeeld in risiconiveaus, elk niveau met afdwingbare poorten. CI leest het; merge-beleid leest het; agenten worden erover ingelicht. Het is geen advies:

Beschermde paden — migraties, betalingen, verificatie — zijn bestanden die geen agent mag aanraken. Architectuurgrenzen worden afgedwongen, niet gesuggereerd. Verwijder deze regels en een codeeringsagent is een zeer snelle generator van aannemelijke aansprakelijkheden.
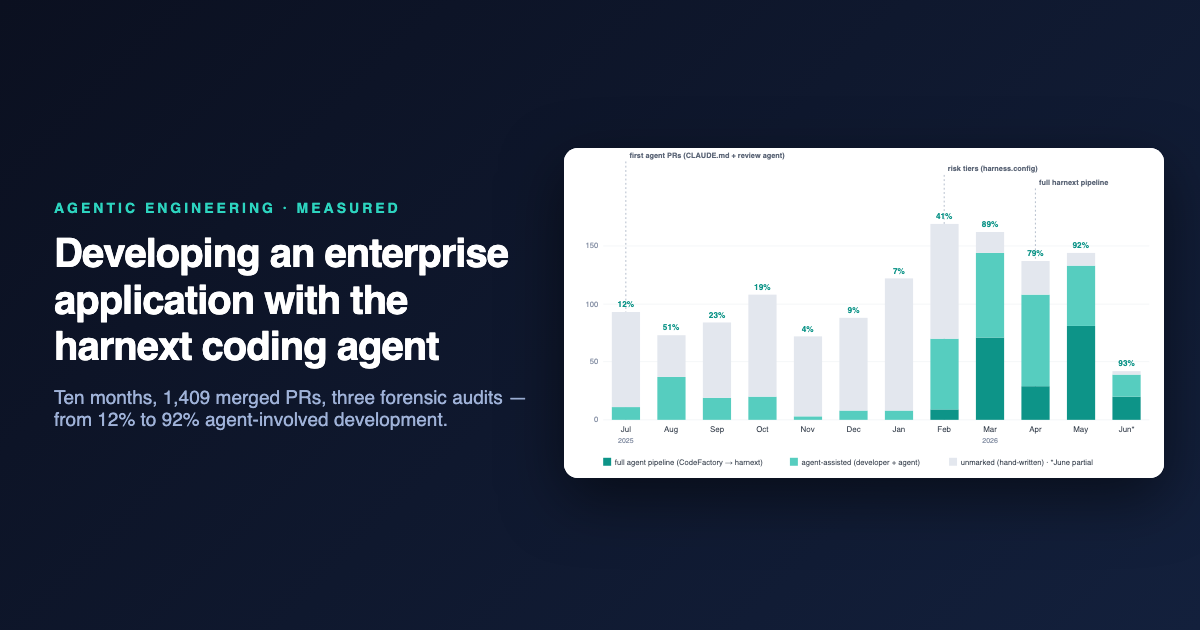
Tien maanden, één grafiek
Het adoptiespoor, gemeten vanuit de repository zelf.

De grafiek telt voor elke maand hoeveel samengevoegde ontwikkelings-PR’s enig hard agentsignaal dragen — de voettekst van de codeeringsagent, de labels van de pijplijn, de harness-tierconventie, commit co-auteur-trailers, agent-commit-e-mails of de eigen account van de pijplijn als auteur. Dependency-bot-PR’s (ongeveer 8% van alle merges) zijn volledig uit de grafiek uitgesloten — ze zijn noch menselijk noch codeeringsagent-werk. We controleerden de signalen op drie onafhankelijke manieren: PR-metadata voor alle 1.409 merges, commit-niveau-trailers over 5.000+ commits en een handmatige forensische doorgang over elke ongemarkeerde PR van 2026. Drie aflezingen zijn belangrijk:
Enthousiasme vervaagt; infrastructuur blijft staan. Het 2025-tijdperk was ad-hoc, persoonlijke adoptie — en het oscilleerde precies zoals persoonlijke gewoonten doen: 44% één maand, nauwelijks 4% in november toen de zwaarste gebruikers pauzeerden. De harness veranderde de vorm van de curve: binnen een maand na aankomst van de risiconiveaus sprong het gemeten aandeel naar 89%; met de volledige pijplijn bereikte het 92% en bleef daar. Elke laag van regels verhoogde de adoptie meer dan het enthousiasme van enig individu ooit deed. De twee tinten vertellen hetzelfde verhaal binnen het agentaandeel: de lichtband is ontwikkelaars die direct met de agent samenwerken; de donkere band — werk dat de volledige pijplijn van probleem tot beoordeelde PR uitvoerde — verschijnt alleen wanneer de harness aankomt, en in mei draagt het het merendeel van het agentwerk.
We inspecteerden de rest, PR voor PR. Voor april–juni 2026 ontleden de PR’s zonder enig merkteken zich in: dependency-bot-automatisering, agentwerk waarvan alleen de attributie in commit-trailers overbleef, en een residu van waarschijnlijk handgeschreven wijzigingen — ongeveer 11% van niet-automatisering merges. De eerlijke zin is dus: ~89% van echte ontwikkelings-merges in het laatste kwartaal tonen verifieerbare agentbetrokkenheid — en zelfs dat is een ondergrens, aangezien AI-hulp op editorniveau geen spoor achterlaat. We stuurden ook skeptische auditors op de drie zwakste maanden, PR voor PR: november’s aantal steeg van 1 naar 3 bewezen (plus 3 vermoede op stijl), januari’s daalde van 10 naar 8 na het vangen van twee valse positieven, en december werd exact bevestigd — met één wending: per codegrootte, december’s acht gemarkeerde PR’s leverden 39% van die maand’s ingevoegde regels. De agent schreef al de grote functies; het aantal kon het gewoon niet zien. Adoptie is ook niet uniform: sommige ontwikkelaars voeren bijna 100% agentgestuurde werk uit, een paar schrijven nog steeds vooral handmatig — de pijplijn draagt toch een groeiend aandeel.
Kwaliteit ging niet achteruit. Hetzelfde venster verzond Tier-3-wijzigingen — LLM-providerintegratie, betaling-aangrenzend werk, een i18n-uitbreiding — onder poorten die in de periode strenger werden, niet losser. En toen we de consistentie van agentbeoordelingen direct maten, bereikten 21 van 22 onafhankelijke beoordelingagenten dezelfde conclusie op dezelfde PR.
Dus wie is de auteur?
De beste articulatie van waar dit de mens achterlaat, komt uit een engineeringthesis die harness-gestuurde ontwikkeling op een luchtvaartgraadproject bestudeerde:
Op het moment dat een wijziging de menselijke auteur bereikte, waren de routinekwaliteitsproblemen opgelost — de beoordeling van de auteur concentreerde zich op architectuur- en domeinniveaubeslissingen. De merge was de beslissing van de auteur. Het auteurschap van de samengevoegde code berust bij de menselijke auteur, ongeacht welke actor de eerste schets produceerde.
— Štefan Moravík, Design and Implementation of a Drone Mission Planning Module for Airport Lighting Inspection (thesis, 2026)
Dat is ook de deal in productie: agenten doen het conceptwerk en het routinekwaliteitswerk; de mens doet architectuur, domeinbeslissing en bezit de merge.
