
Snowflake MCP Server
Snowflake MCP Server muliggjør sømløs AI-drevet interaksjon med Snowflake-databaser ved å eksponere avanserte verktøy og ressurser via Model Context Protocol (M...
4 min lesing
AI
Database
+5
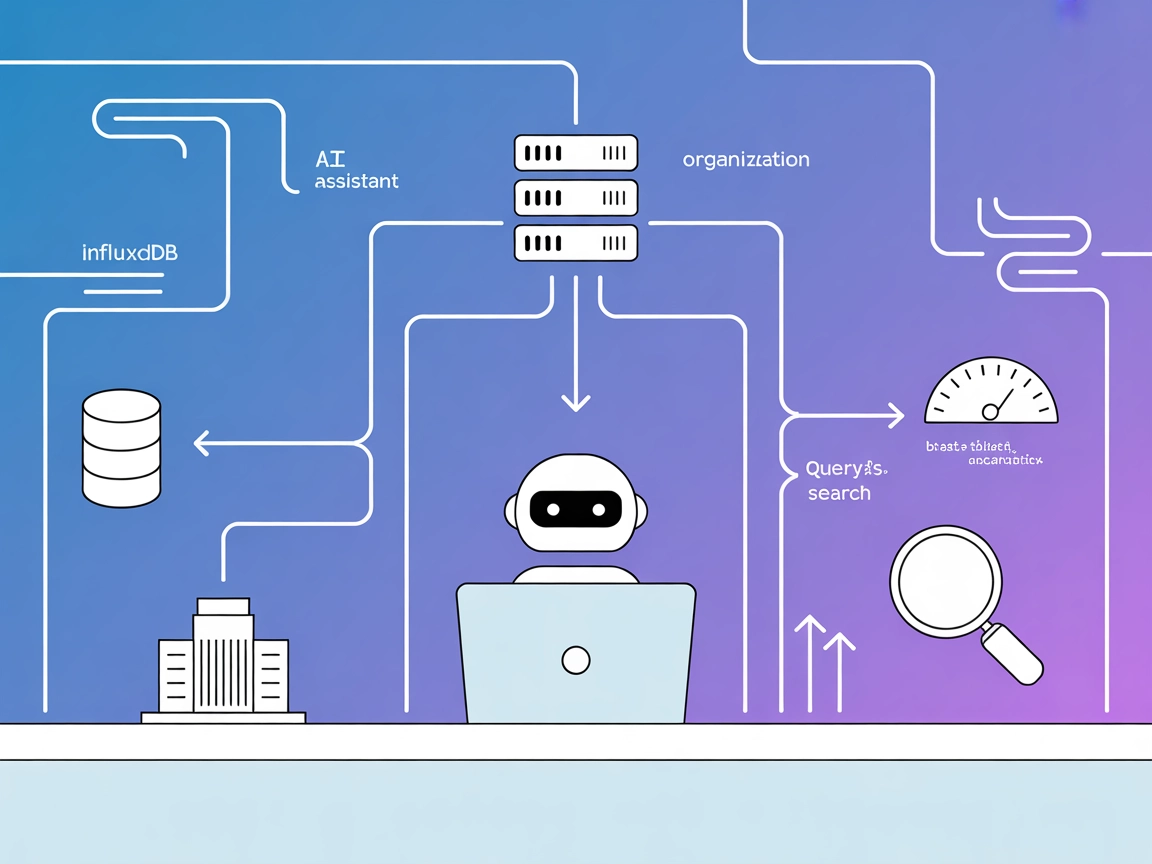
Koble FlowHunt-flowene dine til InfluxDB for sanntidsanalyse av tidsseriedata, automatisert datainntak og databaseadministrasjon—og dra nytte av AI for smartere, automatiserte innsikter.
FlowHunt gir et ekstra sikkerhetslag mellom dine interne systemer og AI-verktøy, og gir deg granulær kontroll over hvilke verktøy som er tilgjengelige fra dine MCP-servere. MCP-servere som er hostet i vår infrastruktur kan sømløst integreres med FlowHunts chatbot samt populære AI-plattformer som ChatGPT, Claude og forskjellige AI-editorer.
InfluxDB MCP-serveren er en Model Context Protocol (MCP)-server utviklet for å gi sømløs tilgang til en InfluxDB-instans via InfluxDB OSS API v2. Den fungerer som et mellomledd som kobler AI-assistenter til tidsseriedata lagret i InfluxDB, og muliggjør forbedrede arbeidsflyter for utviklere og AI-systemer. Gjennom sitt standardiserte grensesnitt eksponerer serveren både ressurser (som organisasjoner, bøtter og målinger) og verktøy (som spørring og skriving av data), slik at AI-klienter kan utføre oppgaver som å kjøre databasespørringer, administrere databøtter eller integrere tidsserieanalyse i sine applikasjoner. Denne robuste integrasjonen sikrer at utviklere kan automatisere datahåndtering, effektivisere utviklingsprosesser og gjøre applikasjonene sine smartere ved å bruke sanntids- og historiske data fra InfluxDB.
Start din gratis prøveperiode i dag og se resultater i løpet av få dager.
influxdb://orgs): Viser alle organisasjoner i InfluxDB-instansen.influxdb://buckets): Viser alle bøtter med tilhørende metadata.influxdb://bucket/{bucketName}/measurements): Viser alle målinger i en spesifisert bøtte.influxdb://query/{orgName}/{fluxQuery}): Kjører en Flux-spørring og returnerer resultatene som en ressurs.Få de siste tipsene, trendene og tilbudene gratis.
Sørg for at Node.js er installert på maskinen din.
Åpne Windsurf-konfigurasjonsfilen (f.eks. windsurf.json eller tilsvarende).
Legg til InfluxDB MCP-serveren i mcpServers-objektet:
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
]
}
}
}
Lagre filen og start Windsurf på nytt.
Verifiser ved å sjekke at InfluxDB MCP-serveren vises i MCP-serverlisten.
Sikre API-nøkler
Sett sensitive verdier som miljøvariabler. Eksempel:
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
],
"env": {
"INFLUXDB_TOKEN": "${INFLUXDB_TOKEN_ENV}"
}
}
}
}
Installer Node.js om det ikke allerede er installert.
Finn Claudes konfigurasjonsfil.
Legg til InfluxDB MCP-serveren i mcpServers:
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
]
}
}
}
Lagre endringer og start Claude på nytt.
Bekreft oppsettet via Claudes grensesnitt.
Sikre API-nøkler
(Se Windsurf-eksempelet over.)
Sørg for at Node.js er til stede.
Åpne Cursors innstillinger eller konfigurasjonsfil.
Legg til InfluxDB MCP-serveren slik:
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
]
}
}
}
Lagre og start Cursor på nytt.
Sjekk MCP-servertilkoblingen.
Sikre API-nøkler
(Se Windsurf-eksempelet over.)
Sørg for at Node.js er installert.
Rediger Clines konfigurasjonsfil.
Sett inn følgende under mcpServers:
{
"mcpServers": {
"influxdb-mcp": {
"command": "npx",
"args": [
"@idoru/influxdb-mcp-server@latest",
"serve"
]
}
}
}
Lagre filen og start Cline på nytt.
Bekreft at serveren er aktiv i Cline.
Sikre API-nøkler
(Se Windsurf-eksempelet over.)
Bruk av MCP i FlowHunt
For å integrere MCP-servere i FlowHunt-arbeidsflyten din, legg til MCP-komponenten i flyten og koble den til AI-agenten din:

Klikk på MCP-komponenten for å åpne konfigurasjonspanelet. I systemets MCP-konfigurasjonsseksjon legger du inn MCP-serverdetaljene dine med dette JSON-formatet:
{
"influxdb-mcp": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Når dette er konfigurert, kan AI-agenten nå bruke MCP-serveren som et verktøy med tilgang til alle dens funksjoner og muligheter. Husk å endre “influxdb-mcp” til det faktiske navnet på MCP-serveren din og bytte ut URL-en med din egen MCP-server-URL.
| Seksjon | Tilgjengelig | Detaljer/Notater |
|---|---|---|
| Oversikt | ✅ | Gitt i README.md |
| Liste over promptmaler | ✅ | flux-query-examples, line-protocol-guide |
| Liste over ressurser | ✅ | orgs, buckets, bucket measurements, Flux query |
| Liste over verktøy | ✅ | write-data, query-data, create-bucket, create-org |
| Sikring av API-nøkler | ✅ | Eksempel på miljøvariabel i konfigurasjonsseksjonen |
| Sampling-støtte (mindre viktig ved evaluering) | ⛔ | Ikke nevnt i dokumentasjonen |
Basert på ovenstående er denne MCP-serveren godt dokumentert for sine kjernefunksjoner innen InfluxDB-integrasjon. Den eksponerer tydelig ressurser og verktøy, inkluderer promptmaler og gir god veiledning for oppsett. Avanserte MCP-funksjoner som roots og sampling er imidlertid ikke dokumentert, noe som begrenser utvidbarheten for enkelte arbeidsflyter.
Dette er en robust, praktisk MCP-server for InfluxDB med tydelig nytte for tidsseriedata og automatiseringsoppgaver. Den scorer høyt for praktisk bruk for utviklere, selv om den mangler dokumentasjon på avanserte MCP-funksjoner.
| Har en LISENS | ✅ (MIT) |
|---|---|
| Har minst ett verktøy | ✅ |
| Antall forks | 6 |
| Antall stjerner | 13 |
Den kobler FlowHunt (eller andre AI-assistenter) til en InfluxDB-database, slik at du kan lese, skrive og administrere tidsseriedata via et standardisert MCP-grensesnitt—og muliggjør analyse, automatisering og forbedrede arbeidsflyter.
Den eksponerer organisasjoner, bøtter, bøttemålinger og støtter direkte Flux-spørringer. Verktøy inkluderer å skrive data (line protocol), lese data, opprette bøtter og opprette organisasjoner.
Bruk 'write-data'-verktøyet for automatisert innskriving i line protocol, eller 'query-data'-verktøyet for avanserte Flux-spørringer—alt tilgjengelig via FlowHunt-flows.
Ja, du bør bruke miljøvariabler for å lagre API-nøkler eller hemmeligheter, slik at legitimasjon aldri hardkodes i konfigurasjonsfiler.
AI-drevet tidsserieanalyse, automatiserte IoT-telemetrilinjer, databaseadministrasjon for organisasjoner/bøtter, og dynamisk datautforskning—alt inne i FlowHunt.
Røtter og sampling er ikke dokumentert for denne serveren per nå, men alle kjernefunksjoner for InfluxDB-integrasjon støttes robust.
Automatiser arbeidsflyter for tidsseriedata og gi AI-agentene dine direkte tilgang til InfluxDB ved å bruke InfluxDB MCP-serveren i FlowHunt.
Snowflake MCP Server muliggjør sømløs AI-drevet interaksjon med Snowflake-databaser ved å eksponere avanserte verktøy og ressurser via Model Context Protocol (M...

GibsonAI MCP Server kobler AI-assistenter til dine GibsonAI-prosjekter og databaser, og muliggjør administrasjon av skjemaer, spørringer, utrullinger og mer med...
Apache IoTDB MCP Server muliggjør sømløs integrasjon av IoTDB tidsseriedatabase i AI-arbeidsflyter, slik at AI-assistenter og utviklerverktøy kan utføre SQL-spø...