“AI pisze większość naszego kodu” brzmi jak slogan startupowy. Czy to może być realne dla aplikacji enterprise — żywi klienci, żywe rozliczenia, monorepo, gdzie złe scalenie kosztuje pieniądze? W QualityUnit tak jest. Oto dziesięciomiesięczny ślad dowodów i reguły, które to sprawiają.
TL;DR: W ciągu dziesięciu miesięcy praca autorstwa agenta przeszła od pierwszych eksperymentalnych PR-ów do 133 z 144 pull requestów rozwojowych scalonych w maju (92%) — zweryfikowane trzystronnym audytem kryminalistycznym wszystkich 1409 scalonych PR-ów, aż do przyczepek commit i ręcznej inspekcji każdego nieoznaczonego PR-u z 2026 roku. Nie stało się to przez “pozwolenie AI kodować”: stało się to przez dodanie reguł — konfiguracji uprząży poziomu ryzyka, potokowej linii wyspecjalizowanych agentów z ograniczonymi pętlami przeglądu, chronionymi ścieżkami i człowiekiem podejmującym każde scalenie. Reguły to produkt. A dzięki silnikowi kontekstowemu zasilającemu agentów, ta sama praca kosztuje teraz ~30% mniej na zadanie (mierzone tutaj ).
Co to faktycznie wymaga
Nie narzędzie. Potok, plik polityki i bramka — uruchamiane przez harnext .
Potok: agenci etapowi, jeden człowiek
Uprząż to harnext — open-source’owa, niezależna od dostawcy uprząż agenta kodowania firmy QualityUnit. W naszym produkcyjnym monorepo, każdy problem, który wchodzi do potoku, przebiega tę samą sekwencję etapów agenta wyzwalanego przez CI, jego postęp śledzony poprzez etykiety, które człowiek może przeczytać na pierwszy rzut oka:

Dwa szczegóły są ważniejsze niż liczba etapów. Pętla jest ograniczona: wady znalezione w przeglądzie wracają do etapu implementacji ograniczoną liczbę razy — agenci zbiegają się lub eskalują do człowieka, nie kłócą się. Nic nie zaczyna się ślepo: przed napisaniem linii, implementujący agent musi załadować konwencje projektu i wyemitować blok potwierdzenia, który recenzenci mogą sprawdzić.
Plik polityki
Druga połowa to czytelna dla maszyn polityka: każda ścieżka w repo sklasyfikowana na poziomy ryzyka, każdy poziom z egzekwowalnymi bramkami. CI ją czyta; polityka scalenia ją czyta; agenci są informowani o niej. To nie rada:

Chronione ścieżki — migracje, płatności, auth — to pliki, których żaden agent nie może dotykać. Granice architektoniczne są wymuszane, nie sugerowane. Weź te reguły i agent kodowania to bardzo szybki generator wiarygodnie wyglądających zobowiązań.
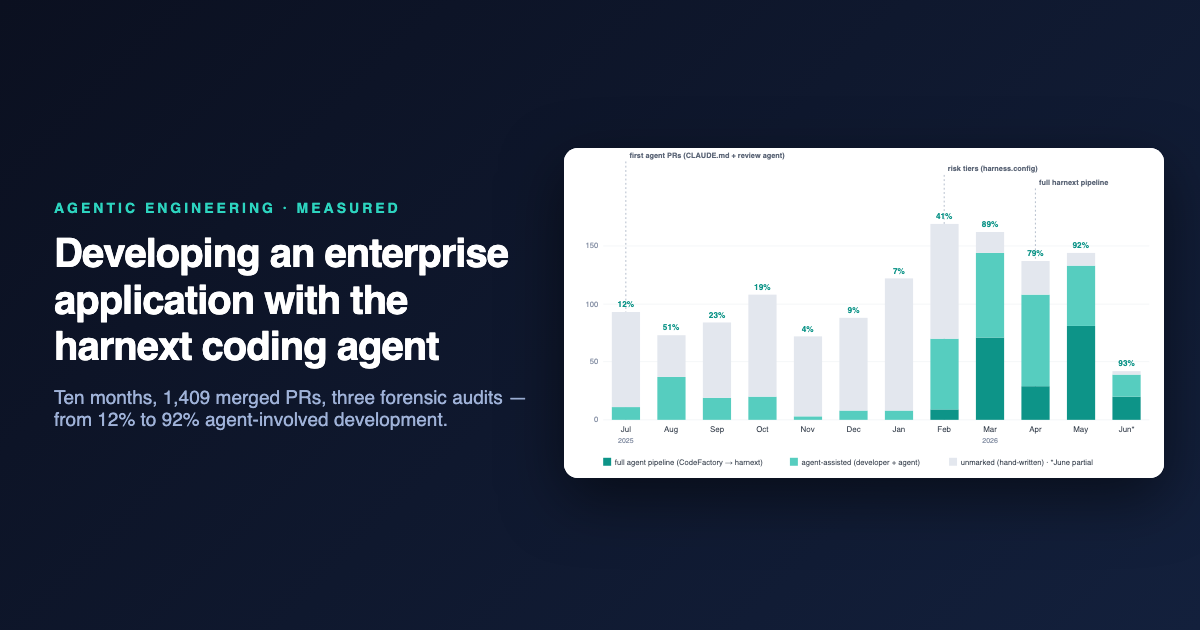
Dziesięć miesięcy, jeden wykres
Ślad adopcji, mierzony z samego repozytorium.

Wykres liczy, dla każdego miesiąca, ile scalonych pull requestów rozwojowych nosi jakikolwiek twardy sygnał agenta — stopkę agenta kodowania, etykiety potoku, konwencję poziomu uprząży, przyczepki współautora commit, wiadomości e-mail agenta, lub własne konto potoku jako autor. PR-y dependency-bota (około 8% wszystkich scaleń) są całkowicie wykluczone z wykresu — to ani praca człowieka, ani agenta kodowania. Sygnały audytowaliśmy trzema niezależnymi sposobami: metadane PR dla wszystkich 1409 scaleń, przyczepki na poziomie commit w 5000+ commitach, i ręczna kryminalistyczna przesiewka każdego nieoznaczonego PR-u z 2026 roku. Trzy odczyty są ważne:
Entuzjazm zanika; infrastruktura pozostaje. Era 2025 była ad-hoc, osobistą adopcją — i oscylowała dokładnie jak osobiste nawyki: 44% jeden miesiąc, ledwie 4% w listopadzie, gdy najciężsi użytkownicy się zatrzymali. Uprząż zmieniła kształt krzywej: w ciągu miesiąca od przybycia poziomów ryzyka, zmierzona część wzrosła do 89%; z pełnym potokiem osiągnęła 92% i tam pozostała. Każda warstwa reguł zwiększyła adopcję bardziej niż entuzjazm jakiegokolwiek indywiduum. Dwa odcienie opowiadają tę samą historię wewnątrz udziału agenta: jasny pas to developerzy parujący z agentem ręcznie; ciemny pas — praca, która ran pełny potok od problemu do przejrzanego PR — pojawia się tylko gdy uprząż ląduje, i do maja nosi większość pracy agenta.
Przeanalizowaliśmy resztę, PR po PR. W przypadku kwietnia–czerwca 2026, PR-y bez jakiegokolwiek markera rozkładają się na: automatyzacja dependency-bota, pracę agenta, której jedynym przypisaniem przetrwało w przyczepkach commit, i pozostałość prawdopodobnie napisanych ręcznie zmian — około 11% nieautomatyzacyjnych scaleń. Więc uczciwe zdanie to: ~89% rzeczywistych scaleń rozwojowych w ostatnim kwartale wykazuje weryfikowalne zaangażowanie agenta — i nawet to jest dolną granicą, ponieważ pomoc AI na poziomie edytora nie pozostawia śladu. Wysłaliśmy również skeptycznych audytorów w trzech najsłabszych miesiącach, PR po PR: liczba listopada wzrosła z 1 do 3 udowodnionych (plus 3 podejrzane w stylu), liczba stycznia spadła z 10 do 8 po złapaniu dwóch fałszywych pozytywów, a grudzień został potwierdzony dokładnie — z jednym zwrotem: według objętości kodu, osiem zaznaczonych PR-ów grudnia dostarczyło 39% wstawionych linii tego miesiąca. Agent już pisał duże funkcje; liczba po prostu nie mogła tego zobaczyć. Adopcja też nie jest jednolita: niektórzy developerzy działają blisko 100% wspomaganego agentem, kilka wciąż głównie pisze ręcznie — potok niesie rosnący udział w każdym razie.
Jakość się nie pogorszyła. To samo okno dostarczyło zmiany Tier-3 — integrację dostawcy LLM, pracę przylegającą do płatności, rozszerzenie i18n — w ramach bramek, które stały się bardziej rygorystyczne w tym okresie, nie luźniejsze. A gdy zmierzyliśmy spójność przeglądu agenta bezpośrednio, 21 z 22 niezależnych agentów przeglądu osiągnęło ten sam werdykt na tym samym PR.
Więc kto jest autorem?
Najlepsze sformułowanie tego, gdzie to zostawia człowieka, pochodzi z pracy inżynierskiej, która badała rozwój napędzany uprzążą w projekcie klasy lotniczej:
Do czasu, gdy zmiana dotarła do autora człowieka, rutynowe problemy jakości zostały rozwiązane — przegląd autora koncentrował się na decyzjach architektonicznych i domenowych. Scalenie było decyzją autora. Autorstwem scalonego kodu jest autor człowieka, niezależnie od tego, który aktor wyprodukował pierwotny szkic.
— Štefan Moravík, Design and Implementation of a Drone Mission Planning Module for Airport Lighting Inspection (thesis, 2026)
To jest umowa w produkcji: agenci zajmują się szkicowaniem i rutynową pracą jakości; człowiek zajmuje się architekturą, osądem domenowym i jest właścicielem scalenia.
