Transformers
Transformers são uma arquitetura revolucionária de redes neurais que transformou a inteligência artificial, especialmente no processamento de linguagem natural....
8 min de leitura
AI
Transformers
+4
Descubra o BERT (Bidirectional Encoder Representations from Transformers), uma estrutura de aprendizado de máquina de código aberto desenvolvida pelo Google para processamento de linguagem natural. Saiba como a arquitetura Transformer bidirecional do BERT revolucionou a compreensão de linguagem da IA, suas aplicações em PLN, chatbots, automação e os principais avanços em pesquisas.
BERT, que significa Bidirectional Encoder Representations from Transformers, é uma estrutura de aprendizado de máquina de código aberto para processamento de linguagem natural (PLN). Desenvolvido por pesquisadores do Google IA Language e lançado em 2018, o BERT avançou significativamente o PLN ao permitir que as máquinas compreendam a linguagem de forma mais semelhante aos humanos.
Em sua essência, o BERT ajuda computadores a interpretar o significado de linguagem ambígua ou dependente de contexto em textos, considerando as palavras ao redor em uma frase — tanto antes quanto depois da palavra-alvo. Essa abordagem bidirecional permite que o BERT capte toda a nuance da linguagem, tornando-o altamente eficaz para uma ampla variedade de tarefas de PLN.
Antes do BERT, a maioria dos modelos de linguagem processava textos de maneira unidirecional (da esquerda para a direita ou da direita para a esquerda), o que limitava sua capacidade de capturar o contexto.
Modelos anteriores como Word2Vec e GloVe geravam embeddings de palavras sem contexto, atribuindo um único vetor para cada palavra, independentemente do contexto. Essa abordagem tinha dificuldades com palavras polissêmicas (ex.: “banco” como instituição financeira vs. margem de rio).
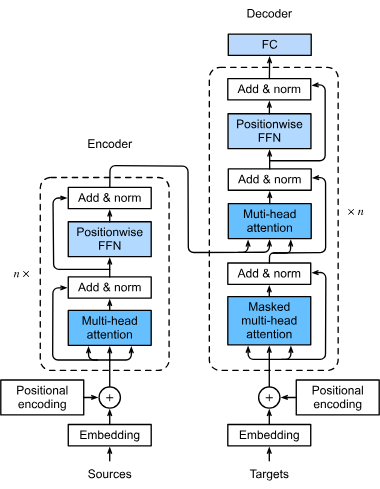
Em 2017, a arquitetura Transformer foi apresentada no artigo “Attention Is All You Need”. Transformers são modelos de aprendizado profundo que usam autoatenção, permitindo pesar dinamicamente a importância de cada parte da entrada.
Transformers revolucionaram o PLN ao processar todas as palavras de uma frase simultaneamente, possibilitando treinamentos em larga escala.
Pesquisadores do Google desenvolveram o BERT com base na arquitetura Transformer, apresentado no artigo de 2018 “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. A inovação do BERT foi aplicar o treinamento bidirecional, considerando tanto o contexto à esquerda quanto à direita.
O BERT foi pré-treinado em toda a Wikipédia em inglês (2,5 bilhões de palavras) e BookCorpus (800 milhões de palavras), proporcionando uma compreensão profunda de padrões, sintaxe e semântica.
Comece seu teste gratuito hoje e veja resultados em dias.
O BERT é uma pilha de codificadores da arquitetura Transformer (utiliza apenas o codificador, não o decodificador). Ele consiste em múltiplas camadas (12 ou 24 blocos Transformer), cada uma com autoatenção e redes neurais feed-forward.
O BERT utiliza tokenização WordPiece, quebrando palavras em subunidades para lidar com palavras raras/fora do vocabulário.
Cada token de entrada é representado pela soma de três embeddings:
Esses elementos ajudam o BERT a compreender tanto a estrutura quanto a semântica.
A autoatenção permite que o BERT pese a importância de cada token em relação aos demais na sequência, capturando dependências independentemente da distância.
Por exemplo, em “O banco aumentou suas taxas de juros”, a autoatenção ajuda o BERT a relacionar “banco” com “taxas de juros”, entendendo “banco” como instituição financeira.
O treinamento bidirecional do BERT permite capturar o contexto de ambas as direções. Isso é alcançado por meio de dois objetivos de treinamento:
No MLM, o BERT seleciona aleatoriamente 15% dos tokens para possível substituição:
[MASK]Essa estratégia incentiva uma compreensão mais profunda da linguagem.
Exemplo:
[MASK] jumps over the lazy [MASK].”O NSP ajuda o BERT a compreender relações entre frases.
Exemplos:
Após o pré-treinamento, o BERT é ajustado para tarefas específicas de PLN adicionando camadas de saída. O ajuste fino requer menos dados e poder computacional do que treinar do zero.
Receba gratuitamente as últimas dicas, tendências e ofertas.
O BERT impulsiona diversas tarefas de PLN, frequentemente alcançando resultados de ponta.
O BERT pode classificar sentimentos (ex.: avaliações positivas/negativas) com sutileza.
O BERT entende perguntas e fornece respostas a partir do contexto.
O NER identifica e classifica entidades-chave (nomes, organizações, datas).
Embora não tenha sido projetado para tradução, a profunda compreensão de linguagem do BERT auxilia na tradução quando combinado a outros modelos.
O BERT pode gerar resumos concisos ao identificar conceitos-chave.
O BERT prevê palavras ou sequências mascaradas, auxiliando na geração de texto.
Em 2019, o Google começou a utilizar o BERT para aprimorar algoritmos de busca, compreendendo contexto e intenção das consultas.
Exemplo:
O BERT impulsiona chatbots, melhorando a compreensão do input do usuário.
Modelos especializados como o BioBERT processam textos biomédicos.
Profissionais jurídicos utilizam o BERT para analisar e resumir textos jurídicos.
Diversas adaptações do BERT existem para eficiência ou domínios específicos:
A compreensão contextual do BERT impulsiona inúmeras aplicações de IA:
O BERT melhorou muito a qualidade de chatbots e automação de IA.
Exemplos:
O BERT possibilita automação de IA para processar grandes volumes de texto sem intervenção humana.
Casos de Uso:
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Autores: Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
Apresenta a arquitetura do BERT e sua eficácia em múltiplos benchmarks, permitindo o condicionamento conjunto do contexto à esquerda e à direita.
Leia mais
Multi-Task Bidirectional Transformer Representations for Irony Detection
Autores: Chiyu Zhang, Muhammad Abdul-Mageed
Aplica o BERT à detecção de ironia, aproveitando o aprendizado multitarefa e o pré-treinamento para adaptação de domínio. Alcança 82,4 de macro F1 score.
Leia mais
Sketch-BERT: Learning Sketch Bidirectional Encoder Representation from Transformers by Self-supervised Learning of Sketch Gestalt
Autores: Hangyu Lin, Yanwei Fu, Yu-Gang Jiang, Xiangyang Xue
Introduz o Sketch-BERT para reconhecimento e recuperação de esboços, aplicando aprendizado autossupervisionado e redes de embedding inovadoras.
Leia mais
Transferring BERT Capabilities from High-Resource to Low-Resource Languages Using Vocabulary Matching
Autor: Piotr Rybak
Propõe o alinhamento de vocabulário para adaptar o BERT a idiomas com poucos recursos, democratizando a tecnologia de PLN.
Leia mais
Chatbots inteligentes e ferramentas de IA em um só lugar. Conecte blocos intuitivos para transformar suas ideias em Fluxos automatizados.
Transformers são uma arquitetura revolucionária de redes neurais que transformou a inteligência artificial, especialmente no processamento de linguagem natural....

Descubra o que é o chatbot de IA GPT, como funciona e por que o ChatGPT é a principal solução de IA generativa. Conheça a arquitetura Transformer, métodos de tr...
Descubra qual empresa desenvolveu o chatbot Bard AI. Saiba mais sobre o Gemini LLM do Google, seus recursos, capacidades e como ele se compara ao ChatGPT em 202...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.