Expansion de la requête
Reformule l'entrée de l'utilisateur en plusieurs requêtes alternatives pour améliorer la recherche sémantique dans la base de connaissances à l'aide d'un prompt...
Recherchez et récupérez facilement des informations dans des documents de base de connaissances privés grâce à la recherche sémantique alimentée par l’IA. Le flux élargit les requêtes des utilisateurs, recherche dans de multiples sources de connaissances et présente les résultats pertinents dans une interface de chat conviviale.
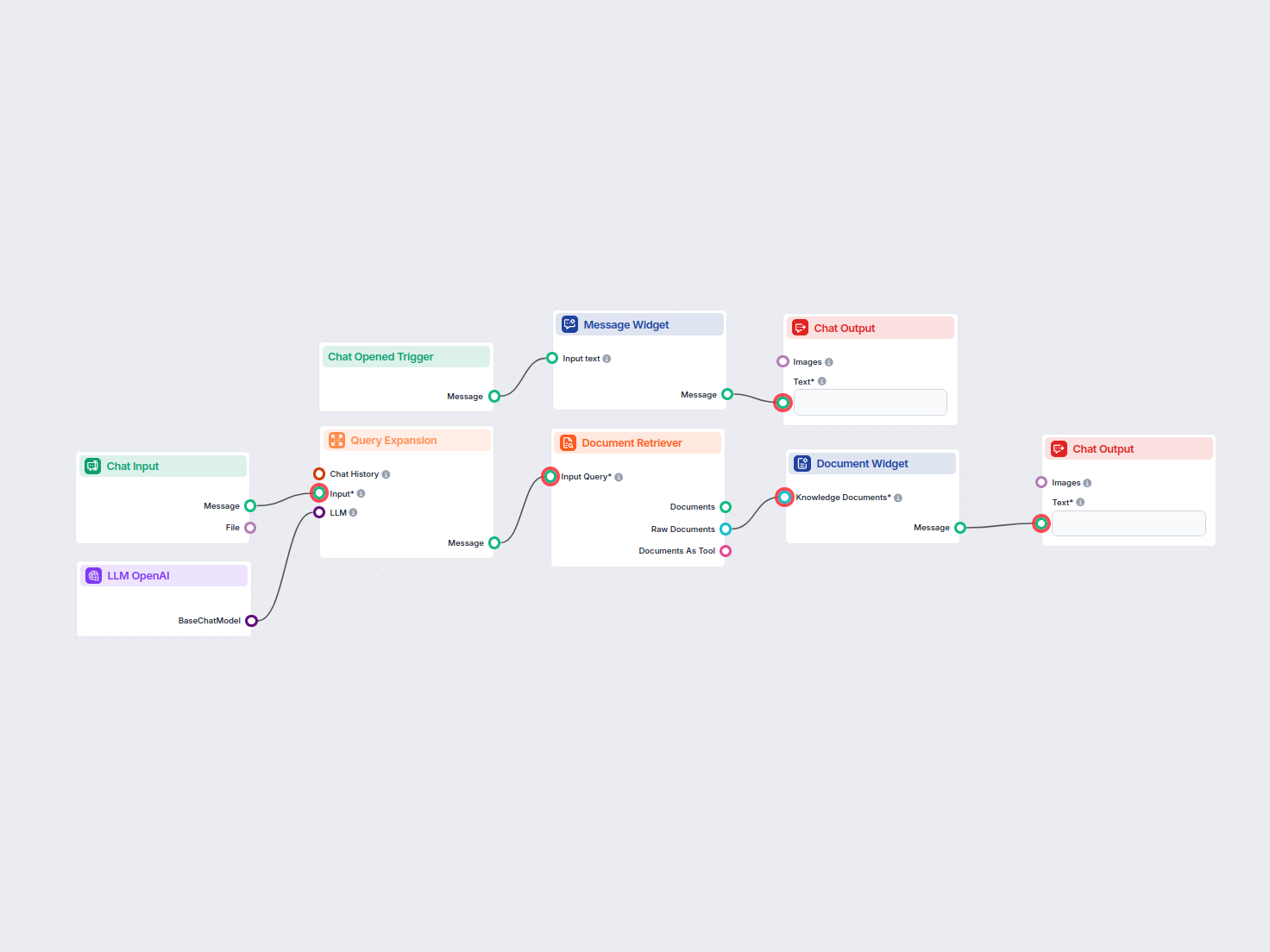

Flux
Reformule l'entrée de l'utilisateur en plusieurs requêtes alternatives pour améliorer la recherche sémantique dans la base de connaissances à l'aide d'un prompt...
Voici une liste complète de tous les composants utilisés dans ce flux pour atteindre sa fonctionnalité. Les composants sont les éléments de base de chaque Flux IA. Ils vous permettent de créer des interactions complexes et d'automatiser des tâches en connectant diverses fonctionnalités. Chaque composant sert un objectif spécifique, comme la gestion des entrées utilisateur, le traitement de données ou l'intégration avec des services externes.
Le composant Entrée de Chat dans FlowHunt initie les interactions utilisateur en capturant les messages depuis le Playground. Il sert de point de départ pour les flux, permettant au workflow de traiter aussi bien des entrées textuelles que des fichiers.
Découvrez le composant Chat Output dans FlowHunt — finalisez les réponses du chatbot avec des sorties flexibles et multiples. Essentiel pour une finalisation fluide des flux et la création de chatbots IA avancés et interactifs.
Le composant Widget de Message affiche des messages personnalisés dans votre workflow. Idéal pour accueillir les utilisateurs, fournir des instructions ou afficher toute information importante, il prend en charge la mise en forme Markdown et peut être configuré pour n'apparaître qu'une seule fois par session.
Le composant Déclencheur d’ouverture de chat détecte le début d’une session de chat, permettant aux workflows de réagir instantanément dès qu’un utilisateur ouvre le chat. Il initie les flux avec le premier message, ce qui le rend essentiel pour créer des chatbots interactifs et réactifs.
L'expansion de requête dans FlowHunt améliore la compréhension du chatbot en trouvant des synonymes, en corrigeant les fautes d'orthographe et en assurant des réponses cohérentes et précises aux requêtes des utilisateurs.
Le Récupérateur de Documents de FlowHunt améliore la précision de l’IA en connectant les modèles génératifs à vos propres documents et URL à jour, garantissant ainsi des réponses fiables et pertinentes grâce à la génération augmentée par récupération (RAG).
Présentez des documents pertinents directement dans les réponses de votre chatbot grâce au Widget de Source de Connaissance. Ce composant affiche des documents sélectionnés sous forme de widgets visuellement distincts, facilitant ainsi l'accès et la consultation des informations de référence pendant une conversation.
FlowHunt prend en charge des dizaines de modèles de génération de texte, y compris ceux d’OpenAI. Voici comment utiliser ChatGPT dans vos outils IA et chatbots.
Description du flux
Ce flux, intitulé « Recherche sémantique », permet aux utilisateurs de rechercher des informations au sein de leur base de connaissances privée en s’appuyant sur des modèles de langage avancés et des techniques de recherche sémantique. Il est conçu pour explorer tous les domaines programmés, documents et sections Q&R, automatisant la récupération des informations les plus pertinentes en réponse aux requêtes des utilisateurs.
Lorsqu’un utilisateur ouvre l’interface de chat, le flux déclenche un message d’accueil :
👋 Bienvenue dans l’outil de recherche de la base de connaissances privée !
Je suis là pour vous aider à explorer les documents de votre base de connaissances privée 📚. J’examinerai tous les domaines programmés, documents privés et sections Q&R pour trouver l’information dont vous avez besoin.
Saisissez simplement votre requête et commençons à chercher les réponses ! ✨🔍
Ce message convivial oriente l’utilisateur et l’invite à saisir sa requête de recherche.
Saisie de l’utilisateur :
L’utilisateur soumet une requête via le champ de saisie du chat.
Expansion de la requête :
gpt-4o-mini), ce composant génère jusqu’à trois reformulations ou requêtes sémantiquement proches.| Composant | Rôle |
|---|---|
| Saisie de chat | Collecte la question de recherche de l’utilisateur |
| OpenAI LLM (gpt-4o-mini) | Génère des formulations alternatives de la requête |
| Expansion de la requête | Produit jusqu’à 3 variantes de requête pour la recherche |
<H1> pour maximiser la pertinence contextuelle.| Étape | Composant | Type de sortie |
|---|---|---|
| Récupérer les documents | Document Retriever | Documents bruts |
| Formater les résultats | Widget de document | Message |
| Afficher à l’utilisateur | Sortie de chat | Message de chat |
flowchart LR
A[Chat Opened] --> B[Welcome Message]
B --> C[User Query Input]
C --> D[Query Expansion\n(OpenAI LLM)]
D --> E[Document Retriever]
E --> F[Document Widget]
F --> G[Chat Output]
Cas d’utilisation typiques :
En associant recherche sémantique et expansion de requête via LLM, ce flux garantit un accès efficace à la connaissance pertinente, favorisant la productivité et la découverte d’informations.
Nous aidons les entreprises comme la vôtre à développer des chatbots intelligents, des serveurs MCP, des outils d'IA ou d'autres types d'automatisation par IA pour remplacer l'humain dans les tâches répétitives de votre organisation.
Ce flux de travail automatise la recherche de mots-clés en générant un tableau détaillé de mots-clés associés à votre expression cible, incluant des métriques S...
Découvrez de quoi les gens parlent en ligne autour du mot-clé de votre choix. Ce flux de travail alimenté par l'IA recherche les sujets tendance ou connexes iss...
Organise automatiquement votre liste de mots-clés en groupes thématiques à l'aide de l'IA, produisant un tableau structuré et facile à analyser pour une stratég...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.