
Intégration MotherDuck MCP
Intégrez FlowHunt avec le serveur DuckDB MCP de MotherDuck pour permettre des analyses SQL sécurisées, évolutives et serverless à vos assistants IA et IDE. Conn...
5 min de lecture
AI
MotherDuck
+6
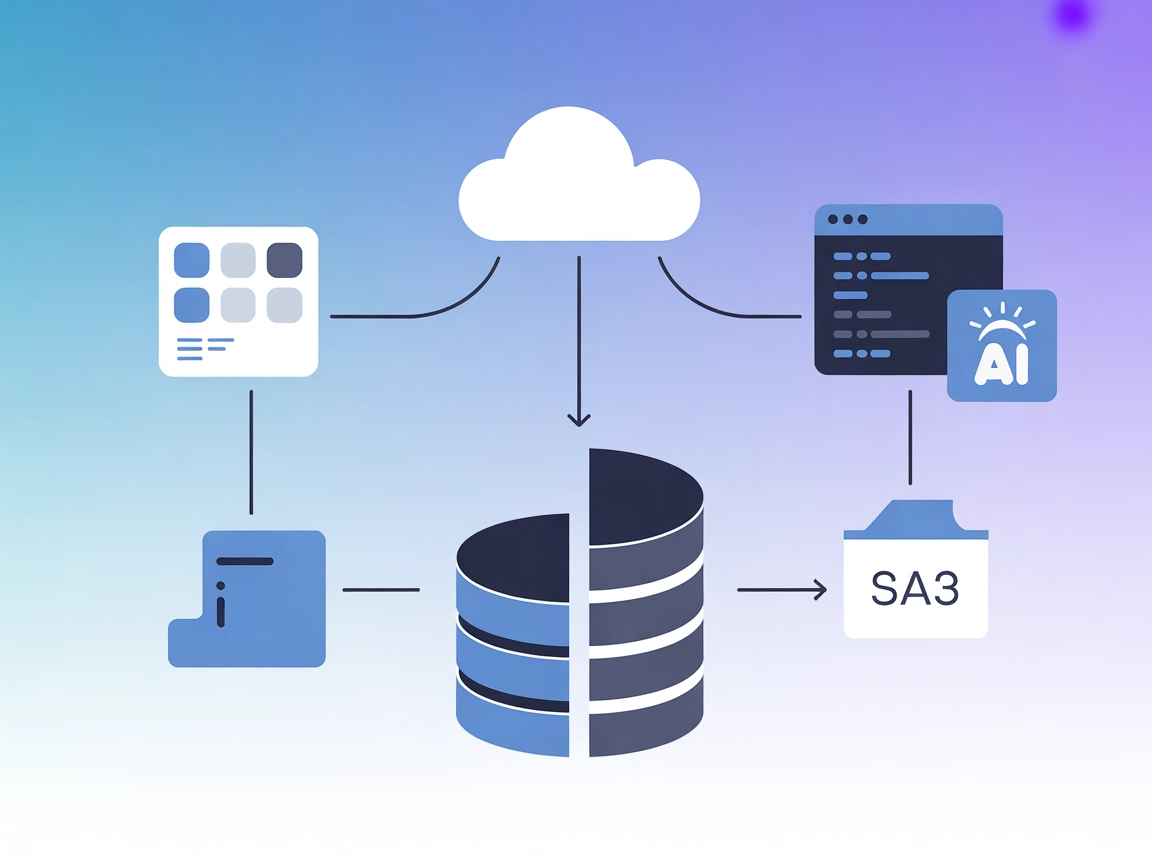
Le serveur MCP MotherDuck connecte les agents IA et les IDE à DuckDB et MotherDuck pour des analyses SQL serverless et des flux hybrides de données fluides dans FlowHunt.
FlowHunt fournit une couche de sécurité supplémentaire entre vos systèmes internes et les outils d'IA, vous donnant un contrôle granulaire sur les outils accessibles depuis vos serveurs MCP. Les serveurs MCP hébergés dans notre infrastructure peuvent être intégrés de manière transparente avec le chatbot de FlowHunt ainsi qu'avec les plateformes d'IA populaires comme ChatGPT, Claude et divers éditeurs d'IA.
Le serveur MCP MotherDuck est une implémentation du Model Context Protocol (MCP) qui fait le lien entre les assistants IA, les IDE et les bases DuckDB et MotherDuck. Il permet aux utilisateurs de réaliser des analyses SQL puissantes via une interface standardisée pour interroger à la fois des fichiers DuckDB locaux et des bases cloud MotherDuck. Le serveur prend en charge l’exécution hybride, permettant un accès fluide aux données locales et cloud, y compris Amazon S3 via les intégrations de MotherDuck. En exposant l’interaction base de données comme outil aux systèmes IA, il simplifie la vie des développeurs et agents IA pour effectuer des requêtes, gérer les données et rationaliser les workflows sans configuration manuelle ni gestion serveur. Cette approche serverless accélère l’analytique, le partage et le développement de pipelines de données directement depuis des environnements pilotés par l’IA.
Commencez votre essai gratuit aujourd'hui et voyez les résultats en quelques jours.
query (string, requis) : L’instruction SQL à exécuter.Recevez gratuitement les derniers conseils, tendances et offres.
Assurez-vous d’avoir Node.js et Windsurf installés.
Ouvrez votre fichier de configuration Windsurf (windsurf.config.json).
Ajoutez le serveur MCP MotherDuck à la section mcpServers :
{
"mcpServers": {
"motherduck": {
"command": "uvx",
"args": ["mcp-server-motherduck", "--transport", "stream", "--db-path", "md:"]
}
}
}
Enregistrez la configuration et redémarrez Windsurf.
Vérifiez dans Windsurf que le serveur MCP MotherDuck tourne et est accessible.
Utilisez des variables d’environnement pour fournir des informations sensibles comme votre token MotherDuck :
{
"mcpServers": {
"motherduck": {
"command": "uvx",
"args": ["mcp-server-motherduck", "--transport", "stream", "--db-path", "md:"],
"env": {
"motherduck_token": "${MOTHERDUCK_TOKEN}"
}
}
}
}
Installez Claude et assurez-vous que Node.js est en place.
Localisez le fichier de configuration Claude (claude.config.json).
Ajoutez ceci dans vos mcpServers :
{
"mcpServers": {
"motherduck": {
"command": "uvx",
"args": ["mcp-server-motherduck", "--transport", "stream", "--db-path", "md:"]
}
}
}
Redémarrez Claude et vérifiez que le serveur apparaît dans l’interface.
Utilisez les variables d’environnement comme ci-dessus pour sécuriser les clés API.
Assurez-vous que Cursor est installé et à jour.
Ouvrez les paramètres de Cursor (cursor.config.json).
Insérez ce qui suit dans mcpServers :
{
"mcpServers": {
"motherduck": {
"command": "uvx",
"args": ["mcp-server-motherduck", "--transport", "stream", "--db-path", "md:"]
}
}
}
Enregistrez et redémarrez Cursor.
Définissez les tokens sensibles via des variables d’environnement.
Installez Cline et les dépendances requises.
Modifiez cline.config.json pour inclure :
{
"mcpServers": {
"motherduck": {
"command": "uvx",
"args": ["mcp-server-motherduck", "--transport", "stream", "--db-path", "md:"]
}
}
}
Enregistrez la config et redémarrez Cline.
Assurez-vous que motherduck_token est défini comme variable d’environnement pour la sécurité.
Utilisation du MCP dans FlowHunt
Pour intégrer les serveurs MCP à votre workflow FlowHunt, commencez par ajouter le composant MCP à votre flow et connectez-le à votre agent IA :

Cliquez sur le composant MCP pour ouvrir le panneau de configuration. Dans la section configuration système MCP, renseignez les détails de votre serveur MCP avec ce format JSON :
{
"motherduck": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Une fois configuré, l’agent IA pourra utiliser ce MCP comme outil avec accès à toutes ses fonctions et capacités. Pensez à remplacer "motherduck" par le nom réel de votre MCP et l’URL par celle de votre propre serveur MCP.
| Section | Disponibilité | Détails/Notes |
|---|---|---|
| Vue d’ensemble | ✅ | Présent dans le README.md |
| Liste des prompts | ✅ | duckdb-motherduck-initial-prompt |
| Liste des ressources | ✅ | Deux ressources (article de blog, vidéo YouTube) listées dans le README.md |
| Liste des outils | ✅ | Outil query |
| Sécurisation des clés API | ✅ | Utilise motherduck_token comme variable d’environnement (README.md) |
| Support du sampling (moins important) | ⛔ | Non mentionné |
Entre ces deux tableaux, le serveur MCP MotherDuck est bien documenté avec des prompts clairs, le support d’outils, des ressources et de bonnes pratiques de sécurité, mais il manque la mention explicite de Roots et du support du sampling. Globalement, c’est une implémentation solide et pratique pour l’analytique base de données via une interface MCP.
| Dispose d’une LICENSE | ✅ (MIT) |
|---|---|
| Dispose d’au moins un outil | ✅ |
| Nombre de Forks | 23 |
| Nombre d’étoiles | 205 |
Le serveur MCP MotherDuck est une implémentation du Model Context Protocol (MCP) qui connecte les assistants IA et les IDE aux bases de données DuckDB et MotherDuck. Il fournit un moyen standardisé d'effectuer des analyses SQL, de gérer les données et de développer des pipelines de données avec des stockages locaux et cloud – le tout sans gestion manuelle du serveur.
Le serveur MCP MotherDuck permet aux assistants IA et aux développeurs de réaliser des analyses SQL, de construire des pipelines de données et d'accéder à des sources de données hybrides locales/cloud. Il prend en charge des cas d'usage comme l'exploration serverless, l'intégration avec le stockage cloud (par ex. Amazon S3) et l'analytique rapide sans configuration d'infrastructure.
Vous devez utiliser des variables d'environnement pour fournir vos tokens MotherDuck en toute sécurité. Définissez `motherduck_token` dans votre configuration comme variable d'environnement (par exemple `${MOTHERDUCK_TOKEN}`) plutôt que de coder en dur les identifiants.
Oui ! FlowHunt prend en charge les serveurs MCP. Il suffit d'ajouter le composant MCP à votre flux, de le configurer avec les détails de votre serveur MCP MotherDuck, et votre agent IA pourra interagir directement avec les bases de données DuckDB et MotherDuck.
L'outil principal exposé est `query`, qui permet d'exécuter des requêtes SQL sur les bases DuckDB ou MotherDuck à partir de votre agent IA ou IDE.
Consultez [l'article de blog MotherDuck](https://motherduck.com/blog/faster-data-pipelines-with-mcp-duckdb-ai/) et [la vidéo YouTube](https://www.youtube.com/watch?v=yG1mv8ZRxcU) pour des explications approfondies sur MCP, DuckDB et les workflows de données propulsés par l'IA.
Accélérez l'analyse de données et simplifiez vos workflows en intégrant le serveur MCP MotherDuck à FlowHunt. Expérimentez le SQL hybride et serverless au bout des doigts.
Intégrez FlowHunt avec le serveur DuckDB MCP de MotherDuck pour permettre des analyses SQL sécurisées, évolutives et serverless à vos assistants IA et IDE. Conn...

Le serveur Tinybird MCP connecte les assistants IA à la plateforme d'analyse de données Tinybird, permettant des requêtes fluides, une intégration API et une ge...
Le serveur DataHub MCP fait le lien entre les agents IA FlowHunt et la plateforme de métadonnées DataHub, permettant une découverte avancée des données, l’analy...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.