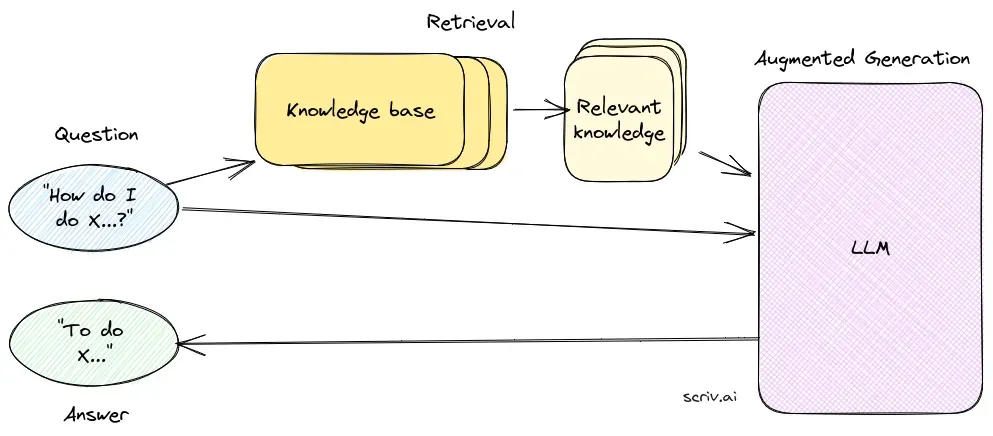
Spørsmål og svar med Retrieval-Augmented Generation (RAG) kombinerer informasjonsinnhenting og naturlig språk-generering for å forbedre store språkmodeller (LLM-er) ved å supplere svarene med relevant, oppdatert data fra eksterne kilder. Denne hybride tilnærmingen forbedrer nøyaktighet, relevans og tilpasningsevne i dynamiske fagfelt.
Spørsmål og svar
Spørsmål og svar med Retrieval-Augmented Generation (RAG) forbedrer språkmodeller ved å integrere sanntids eksterne data for nøyaktige og relevante svar. Det optimaliserer ytelsen i dynamiske fagfelt, og tilbyr forbedret nøyaktighet, dynamisk innhold og økt relevans.
Spørsmål og svar med Retrieval-Augmented Generation (RAG) er en innovativ metode som kombinerer styrkene til informasjonsinnhenting og naturlig språk-generering for å skape menneskelignende tekst fra data, og forbedrer AI, chatboter, rapporter og personaliserte opplevelser. Denne hybride tilnærmingen utvider mulighetene til store språkmodeller (LLM-er) ved å supplere svarene deres med relevant, oppdatert informasjon hentet fra eksterne datakilder. I motsetning til tradisjonelle metoder som kun stoler på forhåndstrente modeller, integrerer RAG dynamisk eksterne data, slik at systemene kan gi mer nøyaktige og kontekstuelt relevante svar, særlig i domener som krever den nyeste informasjonen eller spesialisert kunnskap.
RAG optimerer ytelsen til LLM-er ved å sikre at svarene ikke bare genereres fra et internt datasett, men også informeres av sanntids, autoritative kilder. Denne tilnærmingen er avgjørende for spørsmål-og-svar-oppgaver i dynamiske fagfelt der informasjon stadig utvikles.
Kjernekomponenter i RAG
1. Innhentingskomponent
Innhentingskomponenten har ansvar for å hente relevant informasjon fra store datasett, vanligvis lagret i en vektordatabase. Denne komponenten benytter semantiske søketeknikker for å identifisere og trekke ut tekstsegmenter eller dokumenter som er svært relevante for brukerens forespørsel.
Vektordatabase: En spesialisert database som lagrer vektorreprensentasjoner av dokumenter. Disse embeddingene muliggjør effektivt søk og innhenting ved å matche den semantiske betydningen av brukerens forespørsel med relevante tekstsegmenter.
Semantisk søk: Bruker vektor-embeddings for å finne dokumenter basert på semantiske likheter i stedet for enkle nøkkelord, noe som forbedrer relevansen og nøyaktigheten på innhentet informasjon.
2. Genereringskomponent
Genereringskomponenten, vanligvis en LLM som GPT-3 eller BERT, syntetiserer et svar ved å kombinere brukerens opprinnelige forespørsel med den innhentede konteksten. Denne komponenten er avgjørende for å generere sammenhengende og kontekstuelt riktige svar.
Språkmodeller (LLM-er): Trenede for å generere tekst basert på inngangsprompt, bruker LLM-er i RAG-systemer innhentede dokumenter som kontekst for å forbedre kvaliteten og relevansen på genererte svar.
Arbeidsflyt i et RAG-system
Dokumentforberedelse: Systemet starter med å laste inn et stort korpus av dokumenter, og konverterer dem til et format som egner seg for analyse. Dette innebærer ofte å dele dokumentene opp i mindre, håndterlige biter.
Vektorembedding: Hver dokumentbit konverteres til en vektorreprensentasjon ved hjelp av embeddings generert av språkmodeller. Disse vektorene lagres i en vektordatabase for å muliggjøre effektiv innhenting.
Forespørselsbehandling: Når en brukerforespørsel mottas, konverteres forespørselen til en vektor og det utføres et likhetssøk mot vektordatabasen for å identifisere relevante dokumentbiter.
Kontekstuell svargenerering: De innhentede dokumentbitene kombineres med brukerens forespørsel og mates inn i LLM-en, som genererer et endelig, kontekstuelt beriket svar.
Utdata: Systemet gir et svar som både er nøyaktig og relevant for forespørselen, beriket med kontekstuelt passende informasjon.
Klar til å vokse bedriften din?
Start din gratis prøveperiode i dag og se resultater i løpet av få dager.
Bedre nøyaktighet: Ved å hente relevant kontekst minimerer RAG risikoen for å generere feilaktige eller utdaterte svar, noe som ofte er et problem med frittstående LLM-er.
Dynamisk innhold: RAG-systemer kan integrere den nyeste informasjonen fra oppdaterte kunnskapsbaser, noe som gjør dem ideelle for fagområder som krever oppdatert data.
Økt relevans: Innhentingsprosessen sikrer at genererte svar er skreddersydd til den spesifikke konteksten for forespørselen, noe som gir bedre svartilpasning og relevans.
Bruksområder
Chatboter og virtuelle assistenter: RAG-drevne systemer forbedrer chatboter og virtuelle assistenter ved å gi nøyaktige og kontekstbevisste svar, noe som forbedrer brukeropplevelse og tilfredshet.
Kundesupport: I kundestøtteapplikasjoner kan RAG-systemer hente relevante policydokumenter eller produktinformasjon for å gi presise svar på brukerforespørsler.
Innholdsproduksjon: RAG-modeller kan generere dokumenter og rapporter ved å integrere innhentet informasjon, noe som gjør dem nyttige for automatiserte innholdsgenereringstjenester.
Utdanningsverktøy: I utdanning kan RAG-systemer drive læringsassistenter som gir forklaringer og sammendrag basert på det nyeste utdanningsinnholdet.
Bli med i vårt nyhetsbrev
Få de siste tipsene, trendene og tilbudene gratis.
Teknisk implementering
Implementering av et RAG-system innebærer flere tekniske steg:
Vektorlager og innhenting: Bruk vektordatabaser som Pinecone eller FAISS for å lagre og hente dokument-embeddings effektivt.
Integrering av språkmodeller: Integrer LLM-er som GPT-3 eller egendefinerte modeller ved hjelp av rammeverk som HuggingFace Transformers for å håndtere genereringsaspektet.
Pipeline-konfigurasjon: Sett opp en pipeline som styrer flyten fra dokumentinnhenting til svargenerering, og sikrer en smidig integrasjon av alle komponenter.
Utfordringer og hensyn
Kostnads- og ressursstyring: RAG-systemer kan være ressurskrevende og krever optimalisering for å håndtere beregningskostnader effektivt.
Faktuell nøyaktighet: Det er avgjørende å sikre at den innhentede informasjonen er korrekt og oppdatert for å unngå generering av villedende svar.
Kompleksitet i oppsettet: Den innledende oppsettprosessen for RAG-systemer kan være kompleks og involvere flere komponenter som må integreres og optimaliseres nøye.
Forskning på Spørsmål og svar med Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) er en metode som forbedrer spørsmål-og-svar-systemer ved å kombinere innhentingsmekanismer med generative modeller. Nyere forskning har undersøkt effektiviteten og optimaliseringen av RAG i ulike sammenhenger.
In Defense of RAG in the Era of Long-Context Language Models: Denne artikkelen argumenterer for fortsatt relevans av RAG til tross for fremveksten av langkontekst-språkmodeller, som integrerer lengre tekstsekvenser i prosesseringen. Forfatterne foreslår en Order-Preserve Retrieval-Augmented Generation (OP-RAG) mekanisme som optimaliserer RAGs ytelse ved håndtering av spørsmål og svar med lange kontekster. De viser gjennom eksperimenter at OP-RAG kan oppnå høy svartkvalitet med færre tokens sammenlignet med langkontekst-modeller. Les mer.
CLAPNQ: Cohesive Long-form Answers from Passages in Natural Questions for RAG systems: Denne studien introduserer ClapNQ, et benchmark-datasett utviklet for å evaluere RAG-systemer i generering av sammenhengende, langformede svar. Datasettet fokuserer på svar forankret i bestemte avsnitt, uten hallusinasjoner, og oppmuntrer RAG-modeller til å tilpasse seg konsise og sammenhengende svarformater. Forfatterne gir basislinjeeksperimenter som viser potensielle forbedringsområder for RAG-systemer. Les mer
.
Optimizing Retrieval-Augmented Generation with Elasticsearch for Enhanced Question-Answering Systems: Forskningen integrerer Elasticsearch i RAG-rammeverket for å øke effektiviteten og nøyaktigheten til spørsmål-og-svar-systemer. Ved bruk av Stanford Question Answering Dataset (SQuAD) versjon 2.0 sammenligner studien ulike innhentingsmetoder og fremhever fordelene med ES-RAG-opplegget når det gjelder innhentingseffektivitet og nøyaktighet, og overgår andre metoder med 0,51 prosentpoeng. Artikkelen foreslår videre utforskning av samspillet mellom Elasticsearch og språkmodeller for å forbedre systemenes svar. Les mer.
Vanlige spørsmål
RAG er en metode som kombinerer informasjonsinnhenting og naturlig språk-generering for å gi presise, oppdaterte svar ved å integrere eksterne datakilder i store språkmodeller.
Et RAG-system består av en innhentingskomponent, som henter relevant informasjon fra vektordatabaser ved hjelp av semantisk søk, og en genereringskomponent, vanligvis en LLM, som lager svar ved å bruke både brukerforespørselen og innhentet kontekst.
RAG forbedrer nøyaktigheten ved å hente kontekstuelt relevant informasjon, støtter dynamiske innholdsoppdateringer fra eksterne kunnskapsbaser, og øker relevansen og kvaliteten på genererte svar.
Vanlige bruksområder inkluderer AI-chatboter, kundesupport, automatisert innholdsproduksjon og utdanningsverktøy som krever nøyaktige, kontekstsensitive og oppdaterte svar.
RAG-systemer kan være ressurskrevende, krever nøye integrasjon for optimal ytelse, og må sikre faktuell nøyaktighet i den innhentede informasjonen for å unngå villedende eller utdaterte svar.
Start byggingen av AI-drevne Spørsmål og svar
Oppdag hvordan Retrieval-Augmented Generation kan styrke din chatbot og supportløsninger med sanntids, presise svar.
RAG AI: Den definitive guiden til Retrieval-Augmented Generation og agentiske arbeidsflyter
Oppdag hvordan Retrieval-Augmented Generation (RAG) transformerer bedrifts-AI, fra grunnleggende prinsipper til avanserte agentiske arkitekturer som FlowHunt. L...
Retrieval Augmented Generation (RAG) er et avansert AI-rammeverk som kombinerer tradisjonelle informasjonshentingssystemer med generative store språkmodeller (L...
Henting vs Cache-forsterket generering (CAG vs. RAG)
Oppdag de viktigste forskjellene mellom Retrieval-Augmented Generation (RAG) og Cache-Augmented Generation (CAG) innen AI. Lær hvordan RAG henter sanntidsinform...
5 min lesing
RAG
CAG
+5
Informasjonskapselsamtykke Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.