A Resposta a Perguntas com Geração Aumentada por Recuperação (RAG) combina recuperação de informações e geração de linguagem natural para aprimorar grandes modelos de linguagem (LLMs), suplementando as respostas com dados relevantes e atualizados de fontes externas. Essa abordagem híbrida melhora a precisão, relevância e adaptabilidade em campos dinâmicos.
Resposta a Perguntas
A Resposta a Perguntas com Geração Aumentada por Recuperação (RAG) aprimora modelos de linguagem ao integrar dados externos em tempo real para respostas precisas e relevantes. Ela otimiza o desempenho em campos dinâmicos, oferecendo maior precisão, conteúdo dinâmico e relevância aprimorada.
Resposta a Perguntas com Geração Aumentada por Recuperação (RAG) é um método inovador que combina as forças da recuperação de informações e da geração de linguagem natural, criando texto semelhante ao humano a partir de dados, aprimorando IA, chatbots, relatórios e personalizando experiências. Essa abordagem híbrida amplia as capacidades dos grandes modelos de linguagem (LLMs) ao suplementar suas respostas com informações relevantes e atualizadas recuperadas de fontes de dados externas. Ao contrário dos métodos tradicionais que dependem apenas de modelos pré-treinados, o RAG integra dados externos de forma dinâmica, permitindo que os sistemas forneçam respostas mais precisas e contextualmente relevantes, especialmente em domínios que exigem as informações mais recentes ou conhecimento especializado.
O RAG otimiza o desempenho dos LLMs ao garantir que as respostas não sejam apenas geradas a partir de um conjunto de dados interno, mas também informadas por fontes em tempo real e autoritativas. Essa abordagem é fundamental para tarefas de resposta a perguntas em áreas dinâmicas, onde a informação está em constante evolução.
Componentes Centrais do RAG
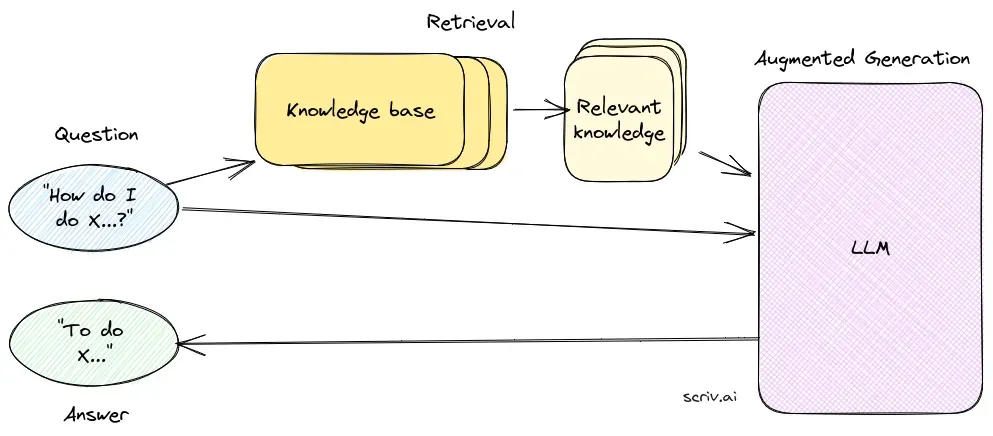
1. Componente de Recuperação
O componente de recuperação é responsável por buscar informações relevantes em grandes conjuntos de dados, normalmente armazenados em um banco de dados vetorial. Esse componente utiliza técnicas de busca semântica para identificar e extrair segmentos de texto ou documentos altamente relevantes para a consulta do usuário.
Banco de Dados Vetorial: Um banco de dados especializado que armazena representações vetoriais de documentos. Esses embeddings facilitam a busca e recuperação eficientes ao combinar o significado semântico da consulta do usuário com segmentos de texto relevantes.
Busca Semântica: Utiliza embeddings vetoriais para encontrar documentos com base em similaridades semânticas, em vez de simples correspondência de palavras-chave, melhorando a relevância e precisão da informação recuperada.
2. Componente de Geração
O componente de geração, geralmente um LLM como GPT-3 ou BERT, sintetiza uma resposta combinando a consulta original do usuário com o contexto recuperado. Esse componente é fundamental para gerar respostas coerentes e contextualmente adequadas.
Modelos de Linguagem (LLMs): Treinados para gerar texto com base em prompts de entrada, os LLMs em sistemas RAG usam os documentos recuperados como contexto para aumentar a qualidade e relevância das respostas geradas.
Fluxo de Trabalho de um Sistema RAG
Preparação de Documentos: O sistema começa carregando um grande corpus de documentos, convertendo-os em um formato adequado para análise. Isso geralmente envolve dividir os documentos em partes menores e gerenciáveis.
Embedding Vetorial: Cada segmento de documento é convertido em uma representação vetorial usando embeddings gerados por modelos de linguagem. Esses vetores são armazenados em um banco de dados vetorial para facilitar a recuperação eficiente.
Processamento da Consulta: Ao receber uma consulta do usuário, o sistema converte a consulta em um vetor e realiza uma busca por similaridade no banco de dados vetorial para identificar segmentos de documentos relevantes.
Geração de Resposta Contextualizada: Os segmentos de documentos recuperados são combinados com a consulta do usuário e enviados ao LLM, que gera uma resposta final enriquecida com contexto.
Saída: O sistema apresenta uma resposta que é precisa e relevante para a consulta, enriquecida com informações contextualmente adequadas.
Pronto para expandir seu negócio?
Comece seu teste gratuito hoje e veja resultados em dias.
Maior Precisão: Ao recuperar contexto relevante, o RAG minimiza o risco de gerar respostas incorretas ou desatualizadas, um problema comum em LLMs isolados.
Conteúdo Dinâmico: Sistemas RAG podem integrar as informações mais recentes de bases de conhecimento atualizadas, tornando-os ideais para domínios que exigem dados atuais.
Relevância Aprimorada: O processo de recuperação garante que as respostas geradas sejam adaptadas ao contexto específico da consulta, melhorando a qualidade e relevância das respostas.
Casos de Uso
Chatbots e Assistentes Virtuais: Sistemas com RAG aprimoram chatbots e assistentes virtuais ao fornecer respostas precisas e com conhecimento de contexto, melhorando a interação e satisfação do usuário.
Suporte ao Cliente: Em aplicações de suporte ao cliente, sistemas RAG podem buscar documentos de políticas ou informações de produtos para fornecer respostas precisas às consultas dos usuários.
Criação de Conteúdo: Modelos RAG podem gerar documentos e relatórios integrando informações recuperadas, sendo úteis para tarefas de geração automatizada de conteúdo.
Ferramentas Educacionais: Na educação, sistemas RAG podem alimentar assistentes de aprendizagem que oferecem explicações e resumos com base nos conteúdos educacionais mais recentes.
Junte-se à nossa newsletter
Receba gratuitamente as últimas dicas, tendências e ofertas.
Implementação Técnica
Implementar um sistema RAG envolve várias etapas técnicas:
Armazenamento e Recuperação Vetorial: Utilize bancos de dados vetoriais como Pinecone ou FAISS para armazenar e recuperar embeddings de documentos de forma eficiente.
Integração com Modelos de Linguagem: Integre LLMs como GPT-3 ou modelos personalizados usando frameworks como HuggingFace Transformers para gerenciar a geração de respostas.
Configuração de Pipeline: Configure um pipeline que gerencie o fluxo desde a recuperação de documentos até a geração de respostas, garantindo a integração fluida de todos os componentes.
Desafios e Considerações
Custo e Gestão de Recursos: Sistemas RAG podem demandar muitos recursos, exigindo otimização para gerenciar os custos computacionais de forma eficaz.
Precisão Factual: Garantir que as informações recuperadas sejam precisas e atualizadas é fundamental para evitar a geração de respostas enganosas.
Complexidade na Implementação: A configuração inicial de sistemas RAG pode ser complexa, envolvendo vários componentes que requerem integração e otimização cuidadosas.
Pesquisa sobre Resposta a Perguntas com Geração Aumentada por Recuperação (RAG)
A Geração Aumentada por Recuperação (RAG) é um método que aprimora sistemas de resposta a perguntas ao combinar mecanismos de recuperação com modelos generativos. Pesquisas recentes têm explorado a eficácia e a otimização do RAG em diversos contextos.
In Defense of RAG in the Era of Long-Context Language Models: Este artigo defende a relevância contínua do RAG, apesar do surgimento de modelos de linguagem de longo contexto, que integram sequências de texto maiores em seu processamento. Os autores propõem um mecanismo Order-Preserve Retrieval-Augmented Generation (OP-RAG) que otimiza o desempenho do RAG em tarefas de resposta a perguntas com contexto longo. Eles demonstram, por meio de experimentos, que o OP-RAG pode alcançar alta qualidade de resposta com menos tokens em comparação com modelos de longo contexto. Leia mais.
CLAPNQ: Cohesive Long-form Answers from Passages in Natural Questions for RAG systems: Este estudo apresenta o ClapNQ, um conjunto de dados de referência desenvolvido para avaliar sistemas RAG na geração de respostas longas e coesas. O conjunto de dados foca em respostas fundamentadas em passagens específicas, sem alucinações, e incentiva os modelos RAG a se adaptarem a formatos de respostas concisas e coesas. Os autores fornecem experimentos de base que revelam áreas potenciais de melhoria em sistemas RAG. Leia mais
.
Optimizing Retrieval-Augmented Generation with Elasticsearch for Enhanced Question-Answering Systems: A pesquisa integra o Elasticsearch ao framework RAG para aumentar a eficiência e precisão dos sistemas de resposta a perguntas. Utilizando o Stanford Question Answering Dataset (SQuAD) versão 2.0, o estudo compara vários métodos de recuperação e destaca as vantagens do esquema ES-RAG em termos de eficiência e precisão, superando outros métodos em 0,51 pontos percentuais. O artigo sugere maior exploração da interação entre o Elasticsearch e modelos de linguagem para aprimorar as respostas do sistema. Leia mais.
Perguntas frequentes
RAG é um método que combina recuperação de informações e geração de linguagem natural para fornecer respostas precisas e atualizadas, integrando fontes de dados externas em grandes modelos de linguagem.
Um sistema RAG consiste em um componente de recuperação, que busca informações relevantes em bancos de dados vetoriais utilizando busca semântica, e um componente de geração, geralmente um LLM, que sintetiza respostas usando tanto a consulta do usuário quanto o contexto recuperado.
RAG melhora a precisão ao recuperar informações contextualmente relevantes, suporta atualizações dinâmicas de conteúdo a partir de bases de conhecimento externas e aumenta a relevância e qualidade das respostas geradas.
Casos de uso comuns incluem chatbots de IA, suporte ao cliente, criação automatizada de conteúdo e ferramentas educacionais que exigem respostas precisas, com conhecimento de contexto e atualizadas.
Sistemas RAG podem exigir muitos recursos, necessitam de integração cuidadosa para desempenho ideal e devem garantir precisão factual nas informações recuperadas para evitar respostas enganosas ou desatualizadas.
Comece a Construir Resposta a Perguntas com IA
Descubra como a Geração Aumentada por Recuperação pode impulsionar seu chatbot e soluções de suporte com respostas precisas e em tempo real.
A Geração Aumentada por Recuperação (RAG) é uma estrutura avançada de IA que combina sistemas tradicionais de recuperação de informações com grandes modelos de ...
RAG IA: O Guia Definitivo para Geração Aumentada por Recuperação e Workflows Agentes
Descubra como a Geração Aumentada por Recuperação (RAG) está transformando a IA empresarial, desde os princípios fundamentais até arquiteturas agenticas avançad...
Descubra o que é um pipeline de recuperação para chatbots, seus componentes, casos de uso e como a Recuperação Aumentada por Geração (RAG) e fontes de dados ext...
7 min de leitura
AI
Chatbots
+4
Consentimento de Cookies Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.