
OpenCV MCP Server
Serwer OpenCV MCP łączy zaawansowane narzędzia do przetwarzania obrazu i wideo OpenCV z asystentami AI oraz platformami deweloperskimi poprzez Model Context Pro...
4 min czytania
OpenCV
MCP Server
+4
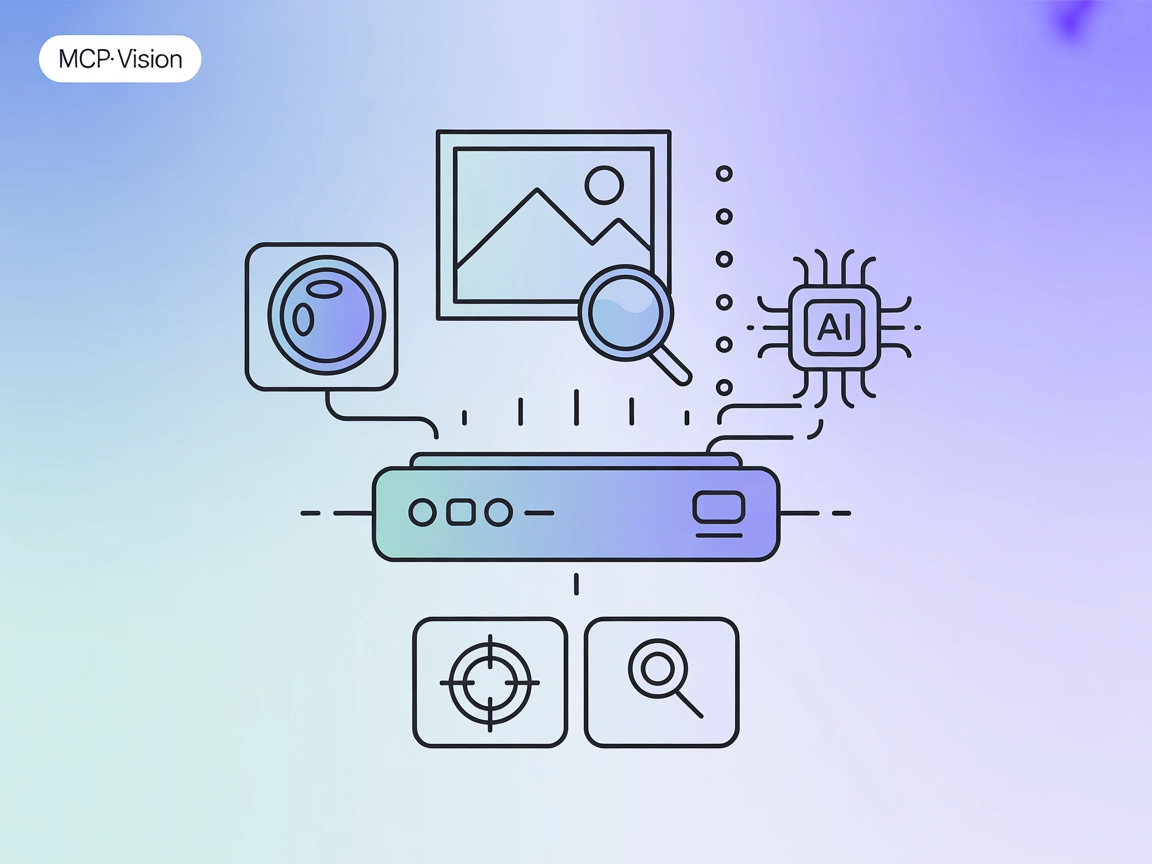
Dodaj komputerowe widzenie do swoich przepływów pracy AI z mcp-vision: wykrywanie obiektów i analiza obrazów zasilane przez HuggingFace jako serwer MCP dla FlowHunt i asystentów multimodalnych.
FlowHunt zapewnia dodatkową warstwę bezpieczeństwa między Twoimi systemami wewnętrznymi a narzędziami AI, dając Ci szczegółową kontrolę nad tym, które narzędzia są dostępne z Twoich serwerów MCP. Serwery MCP hostowane w naszej infrastrukturze można bezproblemowo zintegrować z chatbotem FlowHunt oraz popularnymi platformami AI, takimi jak ChatGPT, Claude i różne edytory AI.
“mcp-vision” MCP Server to serwer Model Context Protocol (MCP), który udostępnia modele komputerowego widzenia HuggingFace—takie jak zero-shot object detection—jako narzędzia rozszerzające możliwości widzenia dużych modeli językowych lub vision-language. Dzięki połączeniu asystentów AI z zaawansowanymi modelami komputerowego widzenia, mcp-vision umożliwia wykonywanie zadań takich jak wykrywanie obiektów i analiza obrazów bezpośrednio w przepływach pracy deweloperskiej. Pozwala to LLM-om i innym klientom AI na programowe zapytania, przetwarzanie i analizę obrazów, co ułatwia automatyzację, standaryzację i rozszerzanie interakcji opartych na wizji w aplikacjach. Serwer działa zarówno w środowiskach GPU, jak i CPU i jest zaprojektowany do łatwej integracji z popularnymi platformami AI.
W dokumentacji ani plikach repozytorium nie wymieniono żadnych szablonów promptów.
Rozpocznij bezpłatny okres próbny już dziś i zobacz rezultaty w ciągu kilku dni.
Brak jawnie udokumentowanych zasobów MCP w repozytorium.
locate_objects
Wykrywaj i lokalizuj obiekty na obrazie, korzystając z jednego z pipeline’ów zero-shot object detection dostępnych przez HuggingFace. Wejścia obejmują ścieżkę do obrazu, listę etykiet kandydatów oraz opcjonalnie nazwę modelu. Zwraca listę wykrytych obiektów w standardowym formacie.
zoom_to_object
Powiększ określony obiekt na obrazie, przycinając obraz do ramki ograniczającej obiektu z najlepszym wynikiem wykrycia. Wejścia obejmują ścieżkę do obrazu, etykietę do znalezienia oraz opcjonalnie nazwę modelu. Zwraca przycięty obraz lub None.
Otrzymuj najnowsze wskazówki, trendy i oferty za darmo.
W repozytorium nie podano instrukcji instalacji dla Windsurf.
git clone git@github.com:groundlight/mcp-vision.git
cd mcp-vision
make build-docker
claude_desktop_config.json i dodaj poniższe pod mcpServers:"mcpServers": {
"mcp-vision": {
"command": "docker",
"args": ["run", "-i", "--rm", "--runtime=nvidia", "--gpus", "all", "mcp-vision"],
"env": {}
}
}
"mcpServers": {
"mcp-vision": {
"command": "docker",
"args": ["run", "-i", "--rm", "mcp-vision"],
"env": {}
}
}
"mcpServers": {
"mcp-vision": {
"command": "docker",
"args": ["run", "-i", "--rm", "--runtime=nvidia", "--gpus", "all", "groundlight/mcp-vision:latest"],
"env": {}
}
}
W repozytorium nie podano instrukcji instalacji dla Cursor.
W repozytorium nie podano instrukcji instalacji dla Cline.
Używanie MCP w FlowHunt
Aby zintegrować serwery MCP ze swoim przepływem pracy FlowHunt, zacznij od dodania komponentu MCP do swojego przepływu i podłączenia go do agenta AI:

Kliknij komponent MCP, aby otworzyć panel konfiguracji. W sekcji systemowej konfiguracji MCP wstaw szczegóły swojego serwera MCP w tym formacie JSON:
{
"mcp-vision": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Po skonfigurowaniu agent AI może już korzystać z tego MCP jako narzędzia, mając dostęp do wszystkich jego funkcji i możliwości. Pamiętaj, aby zmienić “mcp-vision” na faktyczną nazwę swojego serwera MCP i zastąpić URL adresem do własnego serwera MCP.
| Sekcja | Dostępność | Szczegóły/Uwagi |
|---|---|---|
| Przegląd | ✅ | Modele komputerowego widzenia HuggingFace jako narzędzia dla LLM-ów przez MCP |
| Lista promptów | ⛔ | Brak udokumentowanych szablonów promptów |
| Lista zasobów | ⛔ | Brak jawnie wymienionych zasobów |
| Lista narzędzi | ✅ | locate_objects, zoom_to_object |
| Zabezpieczenie kluczy API | ⛔ | Brak instrukcji dotyczących kluczy API |
| Wsparcie dla sampling (mniej istotne w ocenie) | ⛔ | Nie wspomniano |
Ogólnie rzecz biorąc, mcp-vision zapewnia użyteczną, bezpośrednią integrację z modelami wizji HuggingFace, ale brakuje dokumentacji na temat zasobów, szablonów promptów czy zaawansowanych funkcji MCP, takich jak roots czy sampling. Instalacja jest dobrze udokumentowana dla Claude Desktop, ale nie dla innych platform.
mcp-vision to skoncentrowany i praktyczny serwer MCP do dodawania inteligencji wizualnej do przepływów pracy AI, szczególnie w środowiskach obsługujących Dockera. Jego główne zalety to jasna oferta narzędzi i łatwa konfiguracja dla Claude Desktop, ale przydałaby się bogatsza dokumentacja, zwłaszcza w zakresie zasobów, szablonów promptów oraz wsparcia dla dodatkowych platform i zaawansowanych funkcji MCP.
| Ma LICENCJĘ | ✅ MIT |
|---|---|
| Ma co najmniej jedno narzędzie | ✅ |
| Liczba Forków | 0 |
| Liczba Gwiazdek | 23 |
mcp-vision to otwartoźródłowy serwer Model Context Protocol, który udostępnia modele komputerowego widzenia HuggingFace jako narzędzia dla asystentów AI i LLM-ów, umożliwiając wykrywanie obiektów, przycinanie obrazów i inne funkcje w przepływach pracy AI.
mcp-vision oferuje narzędzia takie jak locate_objects (do zero-shot wykrywania obiektów na obrazach) i zoom_to_object (do przycinania obrazów do wykrytych obiektów), dostępne przez interfejs MCP.
Używaj mcp-vision do automatycznego wykrywania obiektów, automatyzacji przepływów pracy opartych na wizji, interaktywnej eksploracji obrazów oraz wzbogacania agentów AI o możliwości wnioskowania i analizy wizualnej.
Dodaj komponent MCP do swojego przepływu FlowHunt i wprowadź szczegóły serwera mcp-vision w panelu konfiguracji, korzystając z podanego formatu JSON. Upewnij się, że Twój serwer MCP działa i jest osiągalny z FlowHunt.
Obecna dokumentacja nie wymaga klucza API ani specjalnych poświadczeń do uruchomienia mcp-vision. Wystarczy skonfigurować środowisko Dockera i zapewnić dostępność serwera.
Wzmocnij swoich agentów AI wykrywaniem obiektów i analizą obrazów przy użyciu mcp-vision. Podłącz go do przepływów FlowHunt, aby uzyskać płynne multimodalne rozumowanie.
Serwer OpenCV MCP łączy zaawansowane narzędzia do przetwarzania obrazu i wideo OpenCV z asystentami AI oraz platformami deweloperskimi poprzez Model Context Pro...
Kubernetes MCP Server łączy asystentów AI z klastrami Kubernetes/OpenShift, umożliwiając programistyczne zarządzanie zasobami, operacje na podach oraz automatyz...

Serwer VMS MCP łączy asystentów AI FlowHunt z rzeczywistymi systemami monitoringu wizyjnego, umożliwiając programistyczne sterowanie CCTV i oprogramowaniem VMS ...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.