
LazyGraphRAG
LazyGraphRAG este o abordare inovatoare a Generării Augmentate prin Regăsire (RAG), optimizând eficiența și reducând costurile în regăsirea datelor bazată pe in...
5 min citire
RAG
AI
+4
LarQL (LQL) este un limbaj de interogare similar cu SQL pentru inspectarea, editarea și auditarea cunoștințelor stocate în greutăți LLM. Interoghează internalele modelului, urmărești căile de inferență, descoperi vecinătăți semantice pentru SEO, auditează percepția mărcii și aplici patch-uri de cunoștințe direcționate fără reciclare.
LarQL — de asemenea menționat ca LQL — este un limbaj de interogare conceput pentru a interacționa direct cu cunoștințele codificate în greutăți modelelor mari de limbă (LLM). Utilizează sintaxă familiară asemănătoare SQL (SELECT, INSERT, UPDATE, DELETE, DESCRIBE) aplicată nu rândurilor într-o bază de date relațională, ci graficului de cunoștințe structurat pe care LLM-urile îl construiesc intern în timpul antrenării.
În timp ce instrumentele tradiționale tratează greutăți model ca o masă binară opacă, LarQL le tratează ca un depozit de cunoștințe interogabil. Un practician poate inspecta ce știe un model despre o entitate specifică, urmărești exact cum modelul ajunge la o inferență dată și aplică patch-uri de cunoștințe direcționate — totul fără reciclare a modelului sau modificarea fișierelor de greutăți de bază.
Un Vindex (index vectorial) este reprezentarea extrasă și interogabilă a cunoștințelor interne ale unui model. Se generează din greutăți model utilizând comanda larql extract-index și se salvează ca fișier independent. Odată extras, un Vindex poate fi navigat și interogat fără a încărca modelul complet — și fără hardware GPU.
Vindex codifică asociațiile învățate de model între entități, relații și straturi, făcând posibil să pui întrebări precum: “Ce crede acest model că este sediul Apple?” sau “Ce concepte asociază acest model cu GDPR lângă stratul 20?”
Operațiile de scriere ale LarQL — INSERT, UPDATE, DELETE — nu modifică fișierele de greutăți ale modelului de bază. În schimb, creează o suprapunere de fișier .patch care este aplicată la momentul inferenței. Aceasta face editarea cunoștințelor:
Începe perioada de probă gratuită astăzi și vezi rezultate în câteva zile.
Pentru a începe să lucrezi cu cunoștințele unui model, extrage un Vindex și deschide REPL-ul interactiv:
larql extract-index path/to/your-model -o company-model.vindex --f16
larql repl
Drapelul --f16 extrage indexul cu precizie în virgulă mobilă de 16 biți. Vindex-ul rezultat pentru un model precum Gemma 3 4B este aproximativ 3 GB.
Aceste comenzi funcționează pe Vindex-ul extras și nu necesită GPU:
Inspectează o entitate specifică:
DESCRIBE "Apple Inc"
Returnează toate cunoștințele pe care modelul le are despre entitate, organizate după strat și trăsătură: industrie, produse, sediu, founded_by, stock_ticker și orice altă relație învățată în timpul antrenării.
Interoghează o relație specifică pe toate entitățile:
SELECT * FROM edges WHERE relation='headquarters' LIMIT 10
Găsește asociații de concepte după distanță:
SELECT * FROM edges WHERE entity='GDPR' NEAREST_TO Layer 20 LIMIT 5
Găsește cele cinci concepte asociate cel mai strâns cu GDPR lângă stratul 20 al reprezentării cunoștințelor modelului.
Listează toate tipurile de relații pe care le-a învățat modelul:
SHOW relations
Returnează lista completă a tipurilor de relații prezente în model. Un model tipic de dimensiuni medii codifică peste 1.000 de tipuri de relații.
Primește cele mai recente sfaturi, tendințe și oferte gratuit.
Rulează inferență cu scoruri de probabilitate:
INFER 'The headquarters of Apple is located in' TOP 5
Returnează cele mai bune 5 completări cu scoruri de încredere (de exemplu: Cupertino 0,71, California 0,14 etc.).
Urmărești inferența strat cu strat:
TRACE 'The CEO of Tesla is' TOP 3
Produce o descompunere strat-cu-strat arătând cum modelul construiește către ieșirea sa — de la detectarea inițială a sintaxei prin identificarea domeniei, recuperarea cunoștințelor până la angajamentul ieșirii. Folosit pentru medicina legală a alucinațiilor atunci când un model produce un răspuns neașteptat sau incorect.
Treci un concept pe straturi:
WALK "climate change" LAYERS 10 TO 28
Arată cum asociațiile modelului pentru un concept evoluează pe straturi — de la co-apariții textuale concrete în straturile timpurii la asociații semantice abstracte în straturile mai adânci.
Operațiile de scriere ale LarQL creează o suprapunere .patch fără a atinge fișierele modelului de bază:
Introduce un fapt nou:
INSERT INTO edges (entity, relation, target, confidence)
VALUES ('Acme Corp', 'CEO', 'Jane Smith', 0.95)
Actualizează un fapt existent:
UPDATE edges
SET target = 'Jane Smith'
WHERE entity = 'Acme Corp' AND relation = 'CEO'
Suprimă un fapt:
DELETE FROM edges
WHERE entity = 'Acme Corp' AND relation = 'former_CEO'
Inspectează patch-uri active:
SHOW patches
Listează toate fișierele de patch active, dimensiunile acestora și numărurile de fapte. Un patch cu 234 de fapte împotriva unui model de bază de 16 GB totaluri aproximativ 2,1 MB.
Un flux de lucru complet de verificare pre-implementare folosind LarQL:
-- 1. Inspectează ce știe modelul despre produsul tău
DESCRIBE "Acme Corp"
-- 2. Găsește asociații incorecte
SELECT * FROM edges WHERE entity='Acme Corp' AND relation='CEO'
-- 3. Verifică fără confuzie de marcă competitivă
SELECT * FROM edges WHERE entity='Acme Corp' NEAREST_TO Layer 20 LIMIT 10
-- 4. Patch orice fapte incorecte înainte de implementare
UPDATE edges SET target='Jane Smith' WHERE entity='Acme Corp' AND relation='CEO'
Acest flux de lucru este baza unui audit model pre-implementare: verifică sistematic că cunoștințele interne ale modelului sunt precise pentru domeniul tău înainte de a le expune utilizatorilor.
Un model de limbă antrenat pe trilioane de documente web a internalizat structura semantică a fiecărui spațiu de subiect pe care l-a întâlnit. În loc să scrapi SERPs sau să cumperi date de cuvinte cheie, poți citi structura direct prin sondarea reprezentărilor interne ale modelului — nu este necesară generarea.
Când depui o interogare cum ar fi "affiliate software" la un LLM, neuroni specifici în straturi feed-forward se declanșează într-un model caracteristic. Aceste activări codifică ceea ce modelul consideră semantic adiacent: concurenți, tehnologii conexe, cazuri de utilizare, site-uri cu recenzii. LarQL face aceste asociații interogabile.
Mapează vecinătatea semantică a oricărui cuvânt cheie:
-- Ce concepte se grupează în jurul termenului tău central în zona de cunoștințe (straturi 12–34)?
WALK "affiliate software" LAYERS 12 TO 34
-- Găsește entitățile cele mai bine asociate la vârful adâncimii cunoștințelor
SELECT * FROM edges WHERE entity='affiliate software' NEAREST_TO Layer 22 LIMIT 20
-- Ce tipuri de relații folosește modelul pentru acest domeniu?
SHOW relations
Ceea ce obții: o listă clasată de termeni semantic adiacenți care reflectă ceea ce modelul (și prin extensie, corpusul web pe care a fost antrenat) consideră vecinătatea naturală a subiectului tău — candidații pentru clustere tematice, cuvinte cheie de integrare și unghiuri de coadă lungă pe care instrumentele convenționale de cuvinte cheie le ratează, deoarece măsoară popularitatea, nu structura semantică.
Scorurile de încredere din NEAREST_TO indică distanța semantică în reprezentarea internă a modelului. Termenii cu scoruri de încredere ridicate sunt profund implicați cu interogarea ta în cunoștințele modelului — sunt ținte naturale de co-apariție pentru strategie de conținut.
Un model antrenat pe date la scară web a învățat care mărci apar în aceleași discuții. Aceasta este mai bogată în semnale decât suprapunerea de legătură inversă sau co-apariție SERP: reflectă credința consolidată a modelului despre care firme operează în același spațiu, construită din milioane de articole, recenzii, pagini de comparație și fire de forum.
-- Ce mărci consideră modelul colocalizate cu a ta?
SELECT * FROM edges WHERE entity='YourBrand' NEAREST_TO Layer 19 LIMIT 15
-- Verifică că aceasta este colocalizare marcă, nu confuzie de categorie
DESCRIBE "YourBrand"
-- Verifică la fel pentru un anumit concurent
SELECT * FROM edges WHERE entity='CompetitorX' NEAREST_TO Layer 19 LIMIT 15
Referință încrucișată cu inferență pentru validare:
-- Produce modelul concurenți în completări directe?
INFER 'The main alternatives to YourBrand are' TOP 8
-- Verificare Monte Carlo: ce mărci apar mai des?
INFER 'Companies similar to YourBrand include' TOP 5
Mărcile care apar în ambele urme FFN la nivel de greutate (NEAREST_TO) și în completări generative (INFER) au cea mai mare încredere. Ele reprezintă peisajul competitiv consolidat al modelului — direct acționabil pentru pagini de comparație “vs”, ghiduri de migrație și pagini de destinație alternative.
Înainte de a implementa un LLM într-un rol orientat către client — sau înainte de a lansa o campanie — merită să înțelegi cum caracterizează modelul marca ta în mod intern. Aceasta diferă de ceea ce modelul spune atunci când este întrebat: reflectă asociațiile latente construite din datele de antrenament, unele dintre care pot contrazice pozicionarea ta intenționată.
-- Caracterizare completă a mărcii tale în cunoștințele modelului
DESCRIBE "YourBrand"
-- În ce categorie te plasează modelul?
SELECT * FROM edges WHERE entity='YourBrand' AND relation='category'
-- Cu ce tehnologii ești asociat?
SELECT * FROM edges WHERE entity='YourBrand' AND relation='integrates_with'
-- Sunt asociații nedorite?
SELECT * FROM edges WHERE entity='YourBrand' NEAREST_TO Layer 20 LIMIT 30
Mers strat-cu-strat pentru a vedea cum evoluează asociațiile:
-- Straturi timpurii: co-apariții superficiale
-- Straturi medii (12–34): asociații factuale
-- Straturi mai târzii: formatare și stil de ieșire
WALK "YourBrand" LAYERS 10 TO 35
Dacă modelul plasează marca ta în categoria greșită, o asociază cu un concurent pe care nu ar trebui, sau reflectă poziționare învechită, aceste decalaje pot fi corectate direct folosind mecanismul de suprapunere a cunoștințelor — corectând reprezentarea internă a modelului fără reciclare.
Atunci când evaluezi un model open-source pentru o implementare specifică domeniei, întrebarea critică nu este performanța benchmark — este: acest model știe destul despre domeniul nostru pentru a fi util, și știe ceva greșit?
LarQL permite o scanare structurată a cunoștințelor înainte de implementare pe întreaga zonă tematică:
-- Pasul 1: Audit cunoștințelor despre produs
DESCRIBE "YourProduct"
DESCRIBE "YourProduct v2"
-- Pasul 2: Verifică cunoștințele de categorie și poziționare
SELECT * FROM edges WHERE entity='YourProduct' AND relation='category'
SELECT * FROM edges WHERE entity='YourProduct' AND relation='primary_use_case'
-- Pasul 3: Găsește decalaje — subiecte fără asociații
SELECT * FROM edges WHERE entity='your_key_topic' NEAREST_TO Layer 20 LIMIT 5
-- Câteva sau fără rezultate = decalaj de cunoștințe
-- Pasul 4: Găsește fapte greșite
SELECT * FROM edges WHERE entity='YourCompany' AND relation='CEO'
SELECT * FROM edges WHERE entity='YourProduct' AND relation='pricing_model'
-- Pasul 5: Patch erori confirmate înainte de go-live
UPDATE edges SET target='Current CEO Name' WHERE entity='YourCompany' AND relation='CEO'
Acest flux de lucru înlocuiește abordarea “implementează și așteaptă reclamații”. Un audit de 4 ore folosind LarQL pe un Vindex poate descoperi decalaje de cunoștințe și erori de fapte care ar fi ajuns la utilizatori reali — și le-ar putea corecta același zi, fără GPU.
Când un LLM implementat produce un răspuns greșit sau dăunător, răspunsul standard este de a actualiza promptul sistem sau de a adăuga gardian. Dar remediez prompturi tratează simptome. LarQL permite diagnostic la nivel de greutate: de ce a crezut modelul asta?
-- Reproduc calea de inferență care a condus la răspuns greșit
TRACE 'The CEO of Acme Corp is' TOP 3
-- Găsește stratul în care s-a recuperat fapt greșit
-- (Numerele straturilor în ieșire TRACE arată unde se cristalizează răspunsul angajat)
-- Verifică ce stochează modelul pentru acea entitate/relație
SELECT * FROM edges WHERE entity='Acme Corp' AND relation='CEO'
-- Verifică fără confuzie polisemantică (același neuron codificând două lucruri)
SELECT * FROM edges WHERE entity='Acme Corp' NEAREST_TO Layer 23 LIMIT 10
-- Aplică corecția direcționată
UPDATE edges SET target='Jane Smith' WHERE entity='Acme Corp' AND relation='CEO'
Ieșirea TRACE arată distribuția de probabilitate peste straturi — de la detectarea inițială a sintaxei, prin recuperarea cunoștințelor în straturile medii, la angajamentul ieșirii. Aceasta este instrumentul principal pentru analiza medico-legală atunci când un incident cauzat de model necesită documentare reglementară sau juridică: demonstrează unde fapt greșit a intrat în calea de inferență și de ce modelul a fost sigur pe el.
| Operație | Timp |
|---|---|
| Căutare KNN a porții per strat | 0,008 ms |
| WALK complet peste 34 straturi | 0,3 ms |
| Inferență completă (cu atenție) | 517 ms |
| Aplicare patch | Instantanee (suprapunere fișier) |
| Dimensiune Vindex — Gemma 3 4B, f16 | ~3 GB |
Navigarea Vindex și interogările SELECT rulează complet pe CPU. INFER și TRACE necesită încărcarea modelului.
LarQL este tehnologia de bază din spatele fiecărei servicii în ciclul de viață al cunoștințelor LLM:
DESCRIBE, SELECT și NEAREST_TO scanează cunoștințele modelului pe întreaga dumneavoastră domeniu înainte de go-liveINSERT, UPDATE, DELETE) aplică corecții direct la greutăți implementate fără reciclareSHOW patches furnizează un înregistrare auditabilă a fiecărui fapt schimbat într-un modelWALK și NEAREST_TO expun harta semantică internă a modelului a oricărui spațiu tematicNEAREST_TO cu validare încrucișată INFER expun credințele de colocalizare ale modelului la nivel de greutateTRACE descompune calea de inferență strat cu strat, identificând exact unde s-a recuperat un răspuns greșit și unde a fost angajatChatboti inteligenți și instrumente IA sub același acoperiș. Conectează blocuri intuitive pentru a transforma ideile tale în fluxuri automatizate.
LazyGraphRAG este o abordare inovatoare a Generării Augmentate prin Regăsire (RAG), optimizând eficiența și reducând costurile în regăsirea datelor bazată pe in...
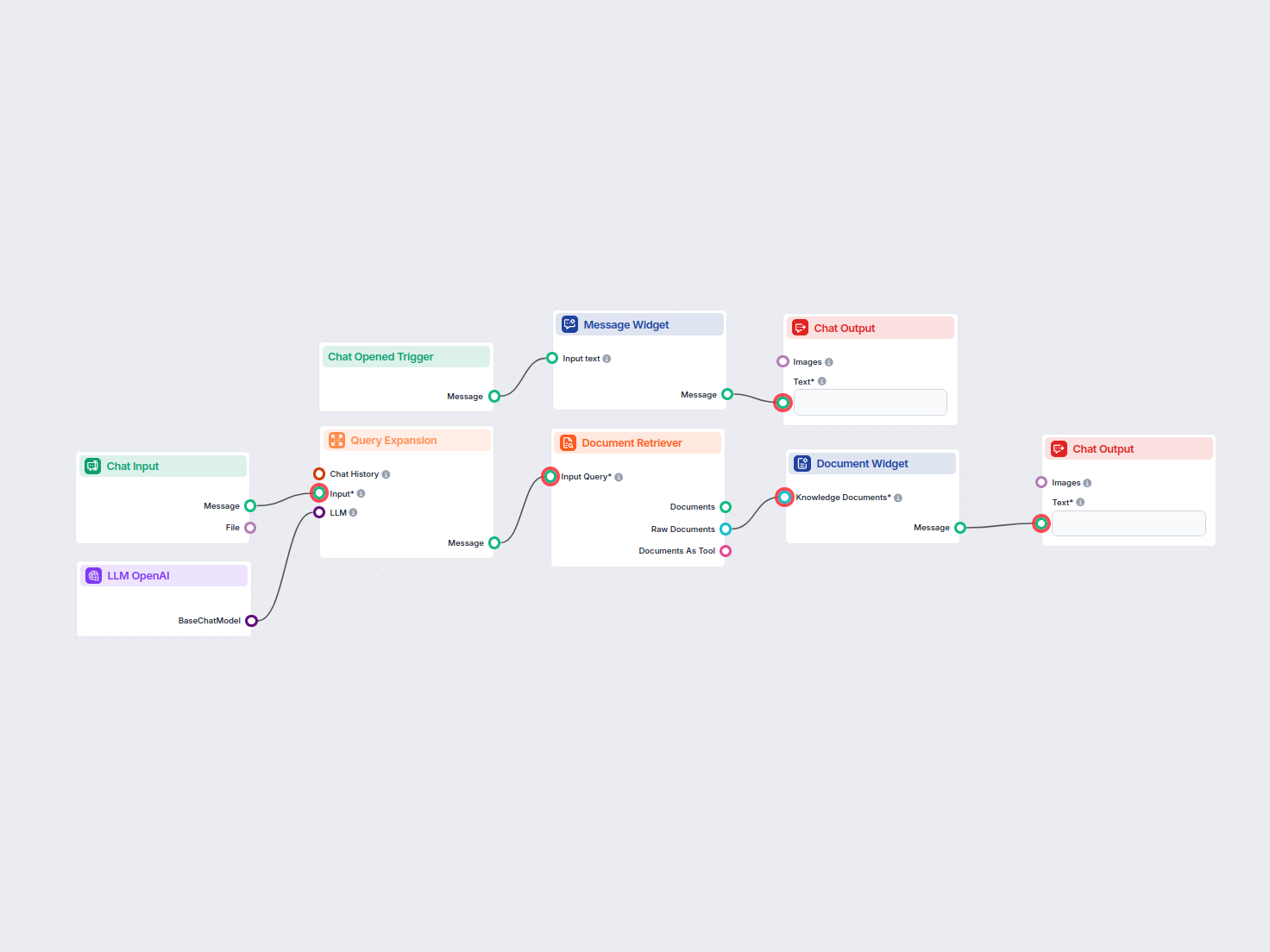
Caută și recuperează cu ușurință informații din documentele bazei de cunoștințe private folosind căutarea semantică alimentată de AI. Fluxul extinde interogăril...

Întrebările și răspunsurile cu Generare Augmentată prin Regăsire (RAG) combină regăsirea informațiilor și generarea de limbaj natural pentru a îmbunătăți modele...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.