
Azure Wiki Search MCP Server
Der Azure Wiki Search MCP Server ermöglicht es KI-Agenten und Entwicklern, programmgesteuert Inhalte aus Azure DevOps Wiki zu durchsuchen und abzurufen. So wird...
4 Min. Lesezeit
MCP Server
Azure
+4

Verbinden Sie Ihren KI-Assistenten mit dem strukturierten Wissen von Wikidata über die Wikidata MCP-Server-Integration von FlowHunt – für nahtlose semantische Suche, Metadatenextraktion und SPARQL-Abfragen.
FlowHunt bietet eine zusätzliche Sicherheitsschicht zwischen Ihren internen Systemen und KI-Tools und gibt Ihnen granulare Kontrolle darüber, welche Tools von Ihren MCP-Servern aus zugänglich sind. In unserer Infrastruktur gehostete MCP-Server können nahtlos mit FlowHunts Chatbot sowie beliebten KI-Plattformen wie ChatGPT, Claude und verschiedenen KI-Editoren integriert werden.
Der Wikidata MCP-Server ist eine Serverimplementierung des Model Context Protocol (MCP), die für die direkte Schnittstelle zur Wikidata-API entwickelt wurde. Er stellt eine Brücke zwischen KI-Assistenten und dem umfangreichen strukturierten Wissen von Wikidata dar, sodass Entwickler und KI-Agenten nahtlos nach Entitäts- und Eigenschaftskennungen suchen, Metadaten (wie Labels und Beschreibungen) extrahieren und SPARQL-Abfragen ausführen können. Durch die Bereitstellung dieser Fähigkeiten als MCP-Tools ermöglicht der Server Aufgaben wie semantische Suche, Wissensextraktion und kontextuelle Anreicherung in Entwicklungsworkflows, in denen externe strukturierte Daten benötigt werden. So können KI-basierte Anwendungen aktuelle Informationen aus Wikidata abrufen, abfragen und logisch verarbeiten.
Im Repository oder in der Dokumentation werden keine Prompt-Vorlagen erwähnt.
Starten Sie heute Ihre kostenlose Testversion und sehen Sie innerhalb weniger Tage Ergebnisse.
Im Repository oder in der Dokumentation sind keine expliziten MCP-Ressourcen beschrieben.
Erhalten Sie die neuesten Tipps, Trends und Angebote kostenlos.
mcpServers-Konfiguration mit einem JSON-Snippet wie unten hinzu."mcpServers": {
"wikidata-mcp": {
"command": "npx",
"args": ["@zzaebok/mcp-wikidata@latest"]
}
}
API-Schlüssel absichern (falls benötigt):
{
"wikidata-mcp": {
"env": {
"WIKIDATA_API_KEY": "your-api-key"
},
"inputs": {
"some_input": "value"
}
}
}
"mcpServers": {
"wikidata-mcp": {
"command": "npx",
"args": ["@zzaebok/mcp-wikidata@latest"]
}
}
API-Schlüssel absichern:
{
"wikidata-mcp": {
"env": {
"WIKIDATA_API_KEY": "your-api-key"
}
}
}
"mcpServers": {
"wikidata-mcp": {
"command": "npx",
"args": ["@zzaebok/mcp-wikidata@latest"]
}
}
API-Schlüssel absichern:
{
"wikidata-mcp": {
"env": {
"WIKIDATA_API_KEY": "your-api-key"
}
}
}
"mcpServers": {
"wikidata-mcp": {
"command": "npx",
"args": ["@zzaebok/mcp-wikidata@latest"]
}
}
API-Schlüssel absichern:
{
"wikidata-mcp": {
"env": {
"WIKIDATA_API_KEY": "your-api-key"
}
}
}
MCP in FlowHunt nutzen
Um MCP-Server in Ihren FlowHunt-Workflow einzubinden, fügen Sie zunächst die MCP-Komponente zu Ihrem Flow hinzu und verbinden Sie sie mit Ihrem KI-Agenten:

Klicken Sie auf die MCP-Komponente, um das Konfigurationspanel zu öffnen. Im Bereich für die System-MCP-Konfiguration tragen Sie Ihre MCP-Serverdetails im folgenden JSON-Format ein:
{
"wikidata-mcp": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Nach der Konfiguration kann der KI-Agent diesen MCP als Tool mit Zugriff auf alle Funktionen und Möglichkeiten nutzen. Denken Sie daran, “wikidata-mcp” ggf. durch den Namen Ihres MCP-Servers zu ersetzen und die URL durch Ihre eigene MCP-Server-URL auszutauschen.
| Abschnitt | Verfügbarkeit | Details/Hinweise |
|---|---|---|
| Übersicht | ✅ | Überblick in README.md verfügbar |
| Liste der Prompts | ⛔ | Keine Prompt-Vorlagen gefunden |
| Liste der Ressourcen | ⛔ | Keine expliziten Ressourcen gelistet |
| Liste der Tools | ✅ | Tools im README.md erläutert |
| API-Key-Absicherung | ⛔ | Kein expliziter API-Key-Zwang gefunden |
| Sampling-Unterstützung (weniger wichtig) | ⛔ | Nicht erwähnt |
Der Wikidata MCP-Server ist eine einfache, aber effektive Implementierung, die mehrere nützliche Tools zur Interaktion mit Wikidata über MCP bereitstellt. Allerdings fehlt es an Dokumentation zu Prompt-Vorlagen, Ressourcen sowie Sampling/Roots-Support, was die Flexibilität für fortgeschrittene oder standardisierte MCP-Integrationen einschränkt. Die vorhandene Lizenz, klare Tools und aktive Updates machen ihn zu einem soliden Ausgangspunkt für MCP-Anwendungsfälle rund um Wikidata.
| Hat eine LICENSE | ✅ (MIT) |
|---|---|
| Mindestens ein Tool | ✅ |
| Anzahl der Forks | 5 |
| Anzahl der Stars | 18 |
MCP-Server-Bewertung: 6/10
Solide Kernfunktionalität, aber es fehlen Standard-MCP-Ressourcen/Prompt-Support und fortgeschrittene Features. Gut für direkte Wikidata-Integrationsanwendungen.
Der Wikidata MCP-Server ist eine Implementierung des Model Context Protocol, die KI-Agenten und Tools direkt mit der Wikidata-API verbindet. Sie können damit nach Entitäten und Eigenschaften suchen, Metadaten extrahieren und SPARQL-Abfragen für fortgeschrittene semantische Datenabfrage und -anreicherung ausführen.
Sie können nach Entitäts- und Eigenschafts-IDs suchen, Eigenschaften von Entitäten abrufen, Labels und Beschreibungen extrahieren und SPARQL-Abfragen ausführen – alles über einfache MCP-Tool-Interfaces.
Fügen Sie die MCP-Komponente zu Ihrem Flow hinzu, konfigurieren Sie sie mit den Details Ihres Wikidata MCP-Servers und verbinden Sie sie mit Ihrem KI-Agenten. Dadurch kann der Agent alle Wikidata-MCP-Tools in Ihren Workflows verwenden.
In den meisten Standard-Setups ist kein API-Schlüssel erforderlich, um auf öffentliche Wikidata-Daten zuzugreifen. Falls Ihre Umgebung einen API-Schlüssel benötigt (z.B. für Proxys oder erweiterte Nutzung), können Sie diesen in der Server-Umgebungskonfiguration angeben.
Sie können ihn für semantische Datenabfrage, Metadatenanreicherung, automatisierte SPARQL-Abfragen, Wissensgraph-Erkundung und den Aufbau KI-gestützter Empfehlungen auf Basis der strukturierten Daten von Wikidata nutzen.
Verbessern Sie das logische Denken und die Datenfähigkeiten Ihrer KI, indem Sie Wikidata als strukturierte Wissensquelle in Ihre FlowHunt-Workflows einbinden.
Der Azure Wiki Search MCP Server ermöglicht es KI-Agenten und Entwicklern, programmgesteuert Inhalte aus Azure DevOps Wiki zu durchsuchen und abzurufen. So wird...
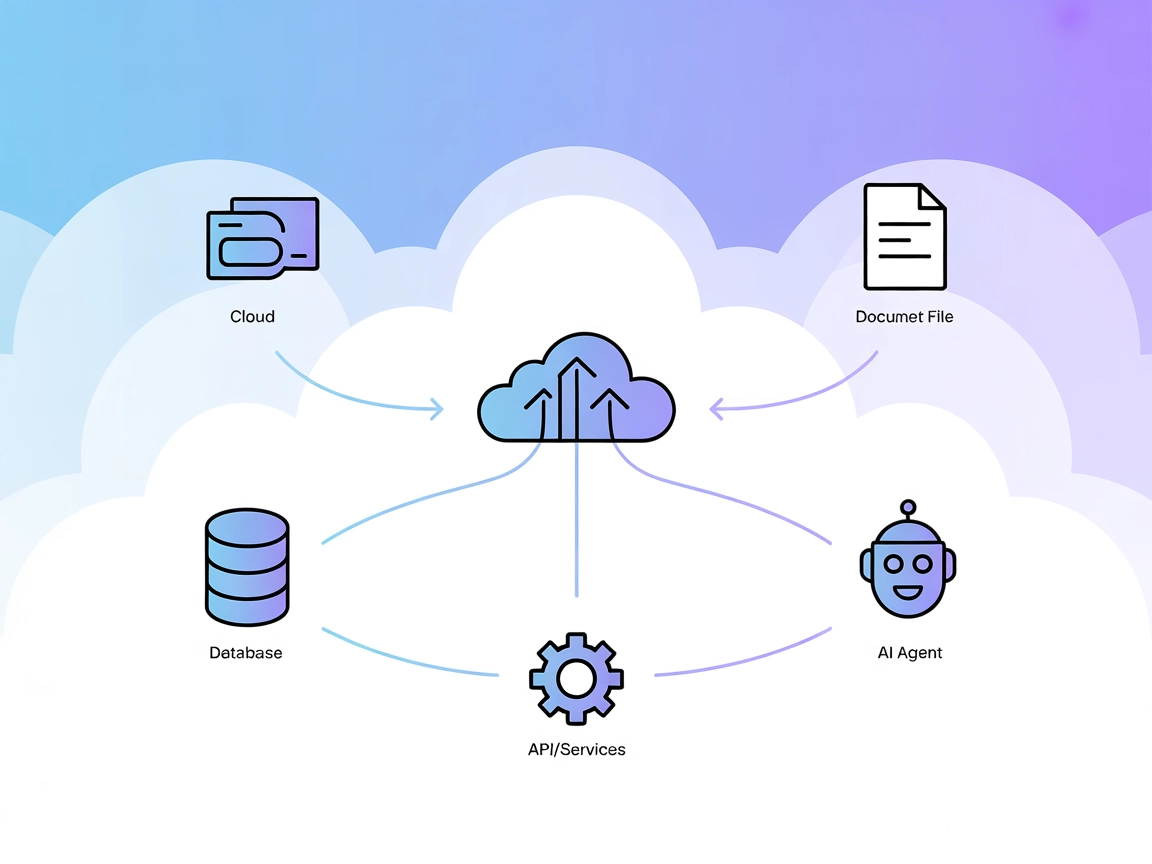
Der Model Context Protocol (MCP) Server verbindet KI-Assistenten mit externen Datenquellen, APIs und Diensten und ermöglicht so eine optimierte Integration komp...

Ermöglichen Sie Ihren KI-Assistenten den Zugriff auf Echtzeit-Websuchdaten mit dem OpenAI WebSearch MCP Server. Diese Integration befähigt FlowHunt und andere P...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.