8 beste Apify-Alternativen in 2026 (Web Scraping & Datenextraktion)
Apify ist leistungsstark, aber komplex und teuer für die meisten Anwendungsfälle. Wir haben 8 Apify-Alternativen für Web Scraping und Datenextraktion verglichen – von No-Code-Tools bis zu Developer-APIs.
Apify ist eine der leistungsstärksten Web-Scraping- und Automatisierungsplattformen – aber es ist für Entwickler konzipiert, erfordert das Erlernen des Actor-Systems und die Kosten summieren sich schnell bei großflächigem Scraping. Wenn Sie etwas Einfacheres, Günstigeres oder besser für KI-Workflows geeignetes suchen, gibt es starke Alternativen.
Was ist Apify?
Apify ist eine cloudbasierte Web-Scraping- und Browser-Automatisierungsplattform. Die Kerneinheit ist der „Actor" – ein wiederverwendbares, teilbares Scraping- oder Automatisierungsskript, das in Apifys Cloud-Infrastruktur läuft. Benutzer können benutzerdefinierte Actors in Node.js mit dem Apify SDK erstellen oder vorgefertigte Actors aus dem Apify Store für gängige Scraping-Aufgaben verwenden (Amazon-Produktdaten, Google Maps-Einträge, LinkedIn-Profile, Social-Media-Inhalte).
Apify handhabt die Infrastruktur-Herausforderungen des Web Scraping: JavaScript-Rendering mit Headless-Browsern, Proxy-Rotation zur Vermeidung von IP-Bans, CAPTCHA-Handhabung, Planung und Ergebnisspeicherung. Dies macht es erheblich leistungsstarker als lokal ausgeführte Scraper.
Der Nachteil: Apify erfordert Entwicklerfähigkeiten zum Erstellen benutzerdefinierter Actors, die Preisgestaltung skaliert mit der Rechenzeit (was bei kontinuierlichem Scraping teuer werden kann) und das Actor-Paradigma hat eine Lernkurve.
Schnellvergleich: Apify vs. Alternativen
Tool
Am besten für
Kostenloser Tier
Startpreis
No-Code
KI-nativ
FlowHunt
KI-integrierte Extraktion
✅
Nutzungsbasiert
✅
✅
Apify
Benutzerdefinierte Entwickler-Scraper
✅
$49/Monat
❌
Teilweise
Browse AI
No-Code-Site-Scraping
✅
$48/Monat
✅
Teilweise
Firecrawl
LLM/KI-Datenvorbereitung
✅
$16/Monat
Teilweise
✅
Octoparse
Visuelles Point-and-Click-Scraping
✅
$75/Monat
✅
❌
ScraperAPI
API-basiertes JS-Rendering
✅
$49/Monat
❌
❌
Bright Data
Enterprise-Datenextraktion
❌
Benutzerdefiniert
❌
Teilweise
PhantomBuster
LinkedIn/Social-Extraktion
✅
$56/Monat
✅
❌
Bardeen
Browser-Task-Automatisierung
✅
$10/Monat
✅
✅
Bereit, Ihr Geschäft zu erweitern?
Starten Sie heute Ihre kostenlose Testversion und sehen Sie innerhalb weniger Tage Ergebnisse.
1. FlowHunt — Best für KI-integrierte Web-Datenextraktion
FlowHunt nähert sich der Web-Datenextraktion anders als Apify: Anstatt eigenständige Scraper zu erstellen, erstellen Sie KI-Agenten, die das Web als Teil größerer automatisierter Workflows durchsuchen. Der Agent kann zu einer URL navigieren, den Seiteninhalt lesen, spezifische Informationen extrahieren und diese Daten sofort im nächsten Schritt verwenden – um sie in ein CRM einzuspeisen, eine Zusammenfassung zu generieren oder eine Outreach-Sequenz auszulösen.
Dies ist ein grundlegend anderer Anwendungsfall als das Batch-Scraping von Millionen von Seiten – FlowHunt zeichnet sich durch intelligente, zielgerichtete Extraktion als Teil eines Geschäftsprozesses aus.
Wichtigste Vorteile gegenüber Apify:
Keine Scraping-Skripte – KI-Agenten navigieren und extrahieren basierend auf natürlichsprachigen Anweisungen
Integrierter Workflow – extrahierte Daten fließen sofort in nachgelagerte Automatisierungsschritte
Handhabt unstrukturierte Seiten – KI versteht Inhalte semantisch, nicht nur nach CSS-Selektor
Integrierte Integrationen – senden Sie extrahierte Daten an CRM, Slack, Sheets oder eines von über 1.400 Tools
Keine Infrastrukturverwaltung – vollständig gehostet und skaliert
Beste Anwendungsfälle:
Überwachung von Konkurrenzpreisen oder Produktänderungen
Extrahieren von Lead-Daten von Unternehmenswebsites
Recherche-Automatisierung (Lesen von Artikeln, Extrahieren von Schlüsselfakten)
Integration von Web-Daten in KI-Zusammenfassungs- oder Analysepipelines
Nicht ideal für: Großflächiges Batch-Scraping von Tausenden von Seiten auf einmal (verwenden Sie dafür ScraperAPI oder Bright Data).
Preisgestaltung: Kostenloser Tier verfügbar. Nutzungsbasierte Preisgestaltung skaliert mit tatsächlichen Workflow-Läufen.
2. Browse AI — Best No-Code Web Scraping Alternative
Browse AI ist die einfachste Apify-Alternative für Nicht-Entwickler. Sie navigieren zur Website, die Sie scrapen möchten, zeigen Browse AI, welche Daten extrahiert werden sollen, indem Sie darauf klicken, und es erstellt einen „Roboter", der die Extraktion nach Plan wiederholt.
Es handhabt dynamisch JavaScript-gerenderte Seiten, Paginierung und Login-geschützte Seiten – ohne Code.
Professional – $149/Monat. 10.000 Credits, priorisierte Läufe, Webhooks, Bulk-Läufe
Team – $399/Monat. 40.000 Credits, mehrere Teammitglieder, API-Zugriff
Enterprise – Kontaktieren Sie den Vertrieb für benutzerdefiniertes Volumen und SLA
Wichtigste Funktionen:
Point-and-Click-Roboter-Training – keine Kodierung erforderlich
Handhabt JavaScript-gerenderte und Login-geschützte Seiten
Geplante Extraktion und automatisierte Änderungsüberwachung
Vorgefertigte Roboter für Amazon, LinkedIn, Google Maps und mehr
Webhook- und Google Sheets-Integration
Bulk-Datenexport zu CSV, JSON und Tabellenkalkulationen
Vorteile: Wirklich No-Code – Setup in Minuten mit Point-and-Click-Schnittstelle; handhabt JavaScript-intensive Seiten gut; geplante Überwachung und Änderungserkennung integriert; vorgefertigte Roboter für gängige Seiten
Nachteile: Begrenzte Flexibilität für komplexe benutzerdefinierte Extraktionslogik; skaliert weniger gut als Apify für sehr großflächiges Scraping; Preis pro Lauf kann für häufig geänderte Seiten unvorhersehbar sein
Am besten für: Nicht-technische Benutzer, die wiederkehrende Extraktion von bestimmten Websites ohne Code oder Infrastrukturverwaltung benötigen.
Abonnieren Sie unseren Newsletter
Erhalten Sie die neuesten Tipps, Trends und Angebote kostenlos.
3. Firecrawl — Best für LLM- und KI-Anwendungsdaten
Firecrawl ist speziell für einen bestimmten Anwendungsfall entwickelt: ganze Websites in sauberes Markdown umzuwandeln, das LLMs lesen können. Es crawlt Websites, rendert JavaScript, handhabt Paginierung und gibt strukturierten, sauberen Text aus – ideal zum Erstellen von RAG (Retrieval-Augmented Generation) Knowledge Bases oder zum Füttern von Web-Inhalten an KI-Agenten.
Preisgestaltung:
Kostenlos – 500 Credits/Monat, bis zu 500 gescrapte Seiten
Hobby – $16/Monat. 3.000 Credits/Monat, vollständiger API-Zugriff, grundlegender Support
Standard – $83/Monat. 100.000 Credits/Monat, höhere Rate Limits, priorisierter Support
Enterprise – Kontaktieren Sie den Vertrieb für benutzerdefiniertes Volumen, SLAs und On-Premise-Optionen
Wichtigste Funktionen:
Konvertiert vollständige Websites in sauberes, LLM-optimiertes Markdown-Output
Vollständiges Website-Crawling mit Sitemap- und Link-Erkennung
JavaScript-Rendering für dynamische Single-Page-Anwendungen
Extract-Endpunkt für strukturierte Datenextraktion mit Schema
Search-Endpunkt für KI-gestützte Web-Suche
Einfache REST-API mit SDKs für Python, Node.js, Go und Rust
Vorteile: Sauberes LLM-bereites Markdown-Output – keine HTML-Bereinigung erforderlich; vollständiges Website-Crawling mit Sitemap-Support; Maps und crawlt dynamische JavaScript-Seiten; einfache API – Integration in Minuten
Nachteile: Nicht geeignet zum Extrahieren strukturierter Daten (Preise, Produktspezifikationen) – gibt Text aus, keine strukturierten Datensätze; kein visueller Builder – nur Developer-API; nicht für geplante Überwachungsanwendungsfälle konzipiert
Am besten für: Entwickler, die KI-Agenten, RAG-Pipelines oder LLM-Anwendungen erstellen, die saubere, strukturierte Web-Inhalte als Input benötigen.
4. Octoparse — Best Visual Scraper mit Cloud-Ausführung
Octoparse bietet eine Desktop-Anwendung mit einer Point-and-Click-Schnittstelle zum visuellen Erstellen von Scrapern, die dann nach Plan in der Cloud ausgeführt werden. Es handhabt die meisten gängigen Scraping-Szenarien – Paginierung, unendliches Scrollen, Dropdown-Navigation – ohne Code.
Preisgestaltung:
Kostenlos – Begrenzt auf 10.000 Datensätze pro Export, lokales (Cloud-loses) Scraping
Standard – $75/Monat. Cloud-Scraping, 10 Cloud-Tasks, Planung, API-Zugriff
Professional – $149/Monat. 30 Cloud-Tasks, IP-Rotation, schnellere Cloud-Ausführung, priorisierter Support
Enterprise – Kontaktieren Sie den Vertrieb. Unbegrenzte Tasks, dedizierter Server, benutzerdefinierte Integrationen, SLA
Wichtigste Funktionen:
Visueller Workflow-Builder – keine Kodierung erforderlich
Cloud-Ausführung mit Planung und automatischer IP-Rotation
Handhabt komplexe Paginierung, unendliches Scrollen und mehrseitige Flows
Integrierte CAPTCHA-Handhabung und Anti-Block-Mechanismen
Export zu Excel, CSV, Google Sheets und Datenbanken (MySQL, SQL Server)
1.000+ vorgefertigte Vorlagen für gängige Websites
Vorteile: Visueller Workflow-Builder – keine Kodierung erforderlich; Cloud-Ausführung mit Planung und IP-Rotation; handhabt komplexe Paginierung und mehrseitige Flows; Export zu Excel, CSV, Google Sheets, Datenbanken
Nachteile: Teurer als Alternativen für gleichwertige Funktionen; Desktop-Client (Windows/Mac) erhöht Reibung gegenüber Browser-basierten Tools; weniger geeignet für Echtzeit-Extraktion gegenüber geplanten Batch-Läufen
Am besten für: Nicht-technische Analysten und Operations-Teams, die zuverlässige geplante Datenextraktion von komplexen oder paginierten Websites benötigen.
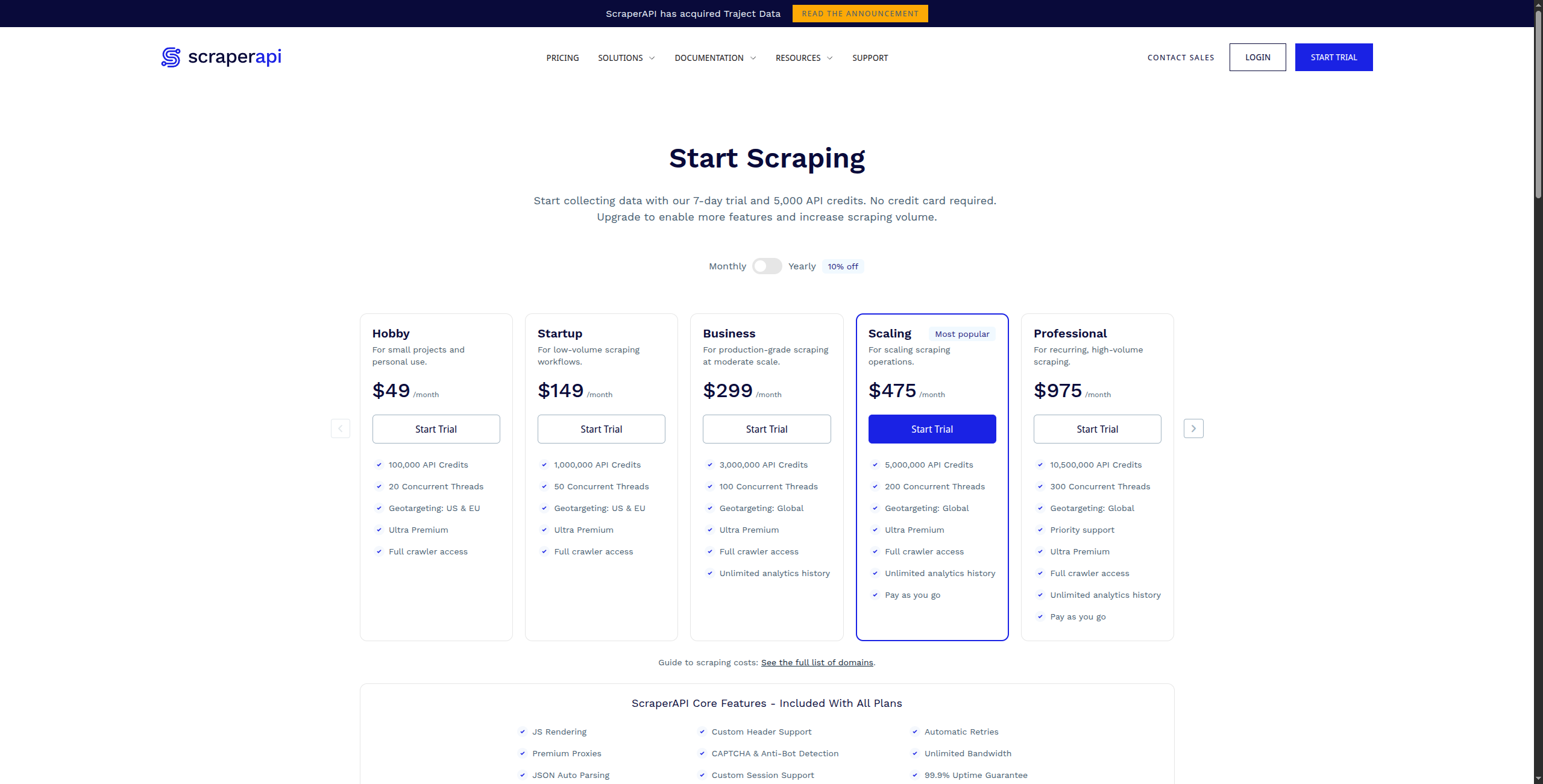
5. ScraperAPI — Best für Developer-Grade Proxy und Rendering
ScraperAPI ist ein API-Service, der die schwierigsten Teile des Web Scraping im großen Maßstab handhabt: JavaScript-Rendering, CAPTCHA-Lösung und automatische Proxy-Rotation. Entwickler senden eine URL an ScraperAPI und erhalten sauberes HTML zurück – es handhabt alles dazwischen.
Preisgestaltung:
Kostenlos – 1.000 API-Aufrufe/Monat, bis zu 5 gleichzeitige Anfragen
Business – $299/Monat. 3.000.000 API-Aufrufe, 50 gleichzeitige Anfragen, dedizierte Proxies
Enterprise – Kontaktieren Sie den Vertrieb für benutzerdefiniertes Volumen und dedizierte Infrastruktur
Wichtigste Funktionen:
Einzelner API-Aufruf gibt gerendertes HTML von jeder URL zurück
Automatische Proxy-Rotation mit über 40 Millionen Wohn- und Rechenzentrum-IPs
JavaScript-Rendering über Headless Chrome für SPAs und dynamische Seiten
CAPTCHA-Lösung und Anti-Bot-Maßnahmen-Umgehung
Geo-Targeting mit länder-spezifischer Proxy-Auswahl
Strukturierte Daten-Endpunkte für Amazon, Google, Walmart und mehr
Vorteile: Einfache API-Integration – ein Funktionsaufruf ersetzt komplexe Scraping-Infrastruktur; handhabt CAPTCHA, Geo-Targeting und Device-Emulation; strukturierte Daten-Endpunkte für gängige Seiten (Amazon, Google, eBay); niedrigere Kosten als Apify für großflächiges einfaches Scraping
Nachteile: Gibt HTML zurück – Sie müssen Daten immer noch selbst analysieren und extrahieren; kein visueller Builder oder No-Code-Schnittstelle; keine Planung oder Überwachung – nur eine Rendering/Proxy-Schicht
Am besten für: Entwickler, die Scraper erstellen und zuverlässige, skalierbare Proxy- und Rendering-Infrastruktur ohne Verwaltung ihres eigenen Proxy-Pools benötigen.
6. Bright Data — Best Enterprise Web Data Platform
Bright Data betreibt eines der weltweit größten Proxy-Netzwerke (über 72 Millionen IPs) und bietet eine vollständige Suite von Web-Datenprodukten: Proxy-Netzwerke, Scraping-APIs, Browser-Automatisierung und vorgefertigte Datensätze für Hunderte beliebter Websites. Für Web-Datenbedürfnisse im Enterprise-Maßstab ist es ungeschlagen.
Preisgestaltung:
Pay-as-you-go – Verfügbar für alle Produkte; Rechenzentrum-Proxies ab $0,6/GB, Wohn-Proxies ab $8,4/GB, ISP-Proxies ab $15/GB
Monatliche Pläne – Ab ~$500/Monat für Rechenzentrum-Proxy-Pläne; Rabatte für höhere verbindliche Volumen
Scraping Browser – Ab $0,1/GB verbrauchte Bandbreite
Web Scraper API – Ab $1,50/1.000 Anfragen für strukturierte Daten-Endpunkte
Datensätze – Vorgefertigte Datensätze für Amazon, LinkedIn, Instagram ab $0,001/Datensatz; benutzerdefinierte Datensatzbereitstellung kontaktieren Sie den Vertrieb
Enterprise – Kontaktieren Sie den Vertrieb für dedizierte Infrastruktur, Compliance-Garantien und SLA
Wichtigste Funktionen:
Proxy-Netzwerk mit über 72 Millionen IPs – Wohn-, Rechenzentrum-, ISP- und Mobile-Proxies
Scraping Browser API für vollständige Browser-Automatisierung im großen Maßstab
Web Scraper IDE zum Erstellen und Verwalten benutzerdefinierter Scraper
Vorgefertigte strukturierte Datensätze für über 100 beliebte Websites
Compliance-grade Datenerfassung mit Rechtsprüfungsprozessen
Enterprise SLA mit 99,9% Uptime-Garantie
Vorteile: Größtes Proxy-Netzwerk der Welt – am besten zur Umgehung fortgeschrittener Anti-Bot-Schutzmaßnahmen; vorgefertigte Datensätze für gängige Anwendungsfälle (Amazon, LinkedIn, Social Media); Web Scraper IDE zum Erstellen benutzerdefinierter Scraper; Enterprise-Compliance und Datenqualitätsgarantien
Nachteile: Komplexe Preisgestaltung – mehrere Produkte mit unterschiedlichen Kostenmodellen; Overkill für kleine oder mittlere Scraping-Anforderungen; erfordert technische Ressourcen für gute Implementierung
Am besten für: Enterprise-Teams mit großflächigen Scraping-Anforderungen, strikten Compliance-Anforderungen oder fortgeschrittenen Anti-Bot-Umgehungsanforderungen.
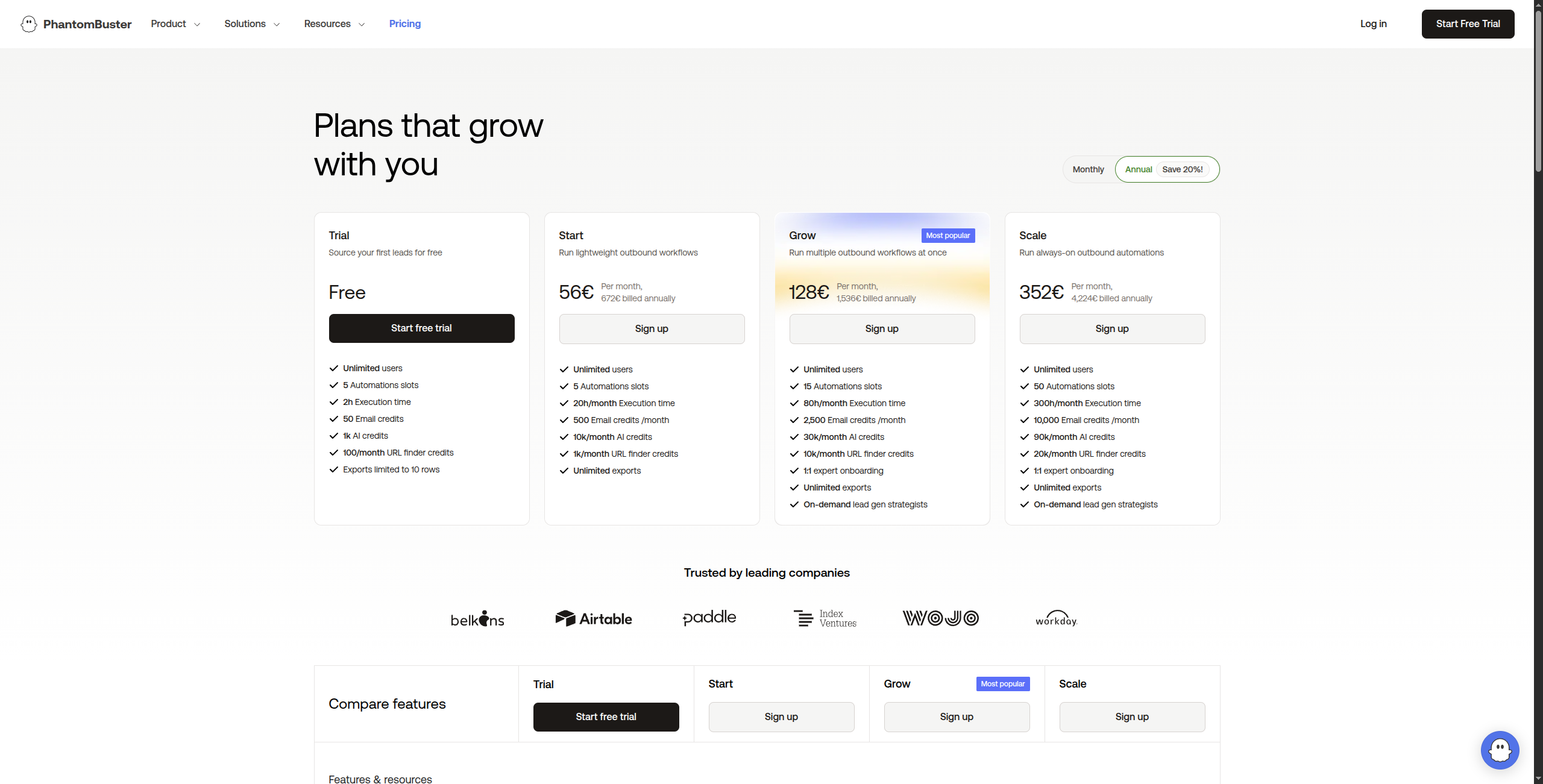
7. PhantomBuster — Best für Social Media Data Extraction
PhantomBuster spezialisiert sich auf das Extrahieren von Daten und das Automatisieren von Aktionen auf Social-Media-Plattformen – LinkedIn, Twitter/X, Instagram, Facebook, Google Maps und mehr. Es ist kein General-Purpose-Web-Scraper, aber zeichnet sich in seiner Nische aus.
Preisgestaltung:
Kostenlose Testversion – 14 Tage, vollständiger Zugriff auf alle Phantoms
Automatisierte Outreach-Sequenzen mit Verbindungsanfragen und Nachrichten
Export zu CSV, Google Sheets, CRM-Webhooks
Geplante Läufe mit konfigurierbarem Drosseln zur Verringerung des Kontorrisikos
Multi-Account-Verwaltung für Agenturnutzung
Vorteile: Vorgefertigte Phantoms für gängige Social-Scraping-Szenarien; LinkedIn-Lead-Extraktion ohne Scraping-Skripte; Automatisierung (Profilbesuche, Verbindungsanfragen) neben Datenextraktion; No-Code-Schnittstelle für die meisten Anwendungsfälle
Nachteile: Plattformspezifisch – nicht nützlich für beliebiges Website-Scraping; LinkedIn-TOS-Compliance-Risiko mit Automatisierung; niedrigere Ausführungszeit-Limits bei niedrigeren Plänen
Am besten für: Sales-Teams und Growth-Marketer, die LinkedIn- und Social-Media-Daten für Lead-Generierung und Outreach extrahieren und nutzen müssen.
8. Bardeen — Best für Browser Task Automation
Bardeen ist eine Chrome-Erweiterung, die Browser-Aktionen aufzeichnet und wiederholt, Daten aus Seiten, die Sie anschauen, extrahiert und extrahierte Daten mit über 100 Apps integriert. Es ist am besten für halbautomatisierte, bedarfsgerechte Extraktion statt vollständig unbeaufsichtigtes Scraping.
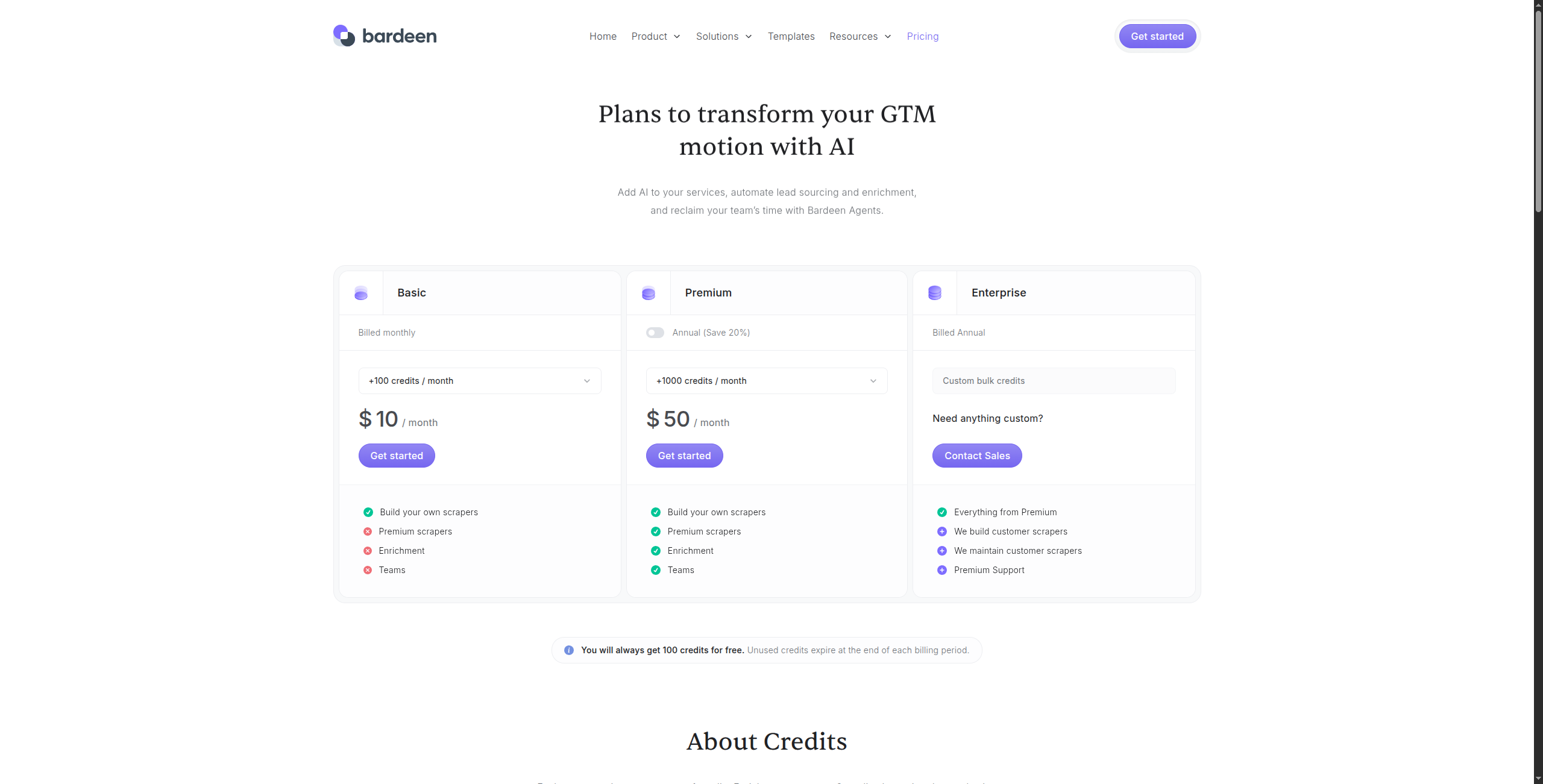
Professional – $10/Monat. Unbegrenzte automatisierte Läufe, Cloud-Speicher, Premium-Integrationen (HubSpot, Salesforce, Pipedrive), priorisierter Support
Business – $15/Benutzer/Monat. Team-Sharing von Automatisierungen, freigegebene Ordner, Admin-Kontrollen
Enterprise – Kontaktieren Sie den Vertrieb für SSO, erweiterte Sicherheit und benutzerdefinierte Integrationen
Wichtigste Funktionen:
AI Magic Actions – beschreiben Sie in einfachem Englisch, was extrahiert werden soll, keine CSS-Selektoren erforderlich
Zeichnet Browser-Aktionen auf und spielt sie als wiederholbare Automatisierungen ab
Integriert mit über 100 Apps: Notion, Airtable, HubSpot, Salesforce, Google Sheets
Scraped Tabellen, Listen und strukturierte Daten von jeder sichtbaren Seite
Läuft im Chrome-Browser – funktioniert auf jeder Website, auf die der Benutzer zugreifen kann
Unterstützt trigger-basierte Automatisierung (zeitbasiert, Webhook oder manuell)
Vorteile: No-Code-Chrome-Erweiterung – null Setup; AI Magic Actions zum Extrahieren von Daten nach Beschreibung, nicht CSS-Selektoren; starke Integrationen mit Notion, Airtable, HubSpot, Salesforce; gut für persönliche Produktivitäts- und Recherche-Workflows
Nachteile: Erfordert offenen Chrome – nicht vollständig unbeaufsichtigte Automatisierung; nicht geeignet für serverseitig großflächiges Scraping; begrenzt auf das, auf das der angemeldete Benutzer in einem Browser zugreifen kann
Am besten für: Einzelne Mitwirkende und kleine Teams, die wiederholte Browser-Recherchen und Datenerfassungsaufgaben ohne Code automatisieren müssen.
Welche Apify-Alternative sollten Sie wählen?
KI-integrierte Extraktion für Business-Workflows → FlowHunt
No-Code-Site-Überwachung und Extraktion → Browse AI
Websites in KI-Knowledge-Basen umwandeln → Firecrawl
Visuelles Scraping komplexer Seiten → Octoparse
Developer-API für Proxy und JavaScript-Rendering → ScraperAPI
Enterprise-Scraping mit Anti-Bot-Umgehung → Bright Data
LinkedIn- und Social-Media-Datenextraktion → PhantomBuster
On-Demand-Browser-Extraktionsaufgaben → Bardeen
Für die meisten Business-Anwendungsfälle – Konkurrenzüberwachung, Lead-Datenextraktion, Prospect-Recherche – schlägt FlowHunt’s KI-nativer Ansatz Apifys Developer-zentriertes Modell sowohl in Bezug auf Setup-Geschwindigkeit als auch Workflow-Integration. Für großflächige technische Scraping-Projekte sind ScraperAPI und Bright Data die richtigen Tools.
Häufig gestellte Fragen
Apify ist eine Web-Scraping- und Automatisierungsplattform, mit der Entwickler Web-Scraper – sogenannte "Actors" – erstellen, bereitstellen und in der Cloud ausführen können. Sie handhabt JavaScript-Rendering, Proxy-Rotation und Planung. Benutzer können benutzerdefinierte Scraper erstellen oder vorgefertigte Actors aus dem Apify Store für gängige Seiten wie Amazon, LinkedIn, Google Maps und Social Media verwenden.
Ja – Browse AI hat einen kostenlosen Plan (50 Läufe/Monat), Bardeen ist kostenlos für grundlegende Automatisierungen, Firecrawl hat einen kostenlosen API-Tier, und FlowHunt's kostenloser Tier beinhaltet Web-Browsing-Funktionen. Für Entwickler sind Open-Source-Bibliotheken wie Playwright, Puppeteer und Scrapy kostenlos, erfordern aber Selbstverwaltung.
Browse AI ist das einfachste – Sie zeigen ihm einfach, was zu scrapen ist, indem Sie durch eine Website klicken, und es erstellt den Scraper automatisch. Octoparse ist ähnlich Point-and-Click. Bardeen ist am besten für einmalige Datenextraktionsaufgaben, bei denen Sie wiederholte Browser-Aktionen automatisieren möchten, ohne technisches Setup.
Firecrawl ist speziell für KI-Anwendungen entwickelt – es konvertiert ganze Websites in sauberes, strukturiertes Markdown, das LLMs direkt verarbeiten können. FlowHunt integriert Web-Extraktion in KI-Agent-Workflows und ist daher die beste Wahl, wenn die extrahierten Daten in Reasoning-, Zusammenfassungs- oder Entscheidungsschritte fließen müssen.
Für Web-Datenbedürfnisse im Enterprise-Maßstab (Millionen von Seiten, komplexe Anti-Bot-Umgehung) ist Bright Data die stärkste Alternative – es betreibt eines der weltweit größten Proxy-Netzwerke und verfügt über Enterprise-grade-Scraping-Infrastruktur. ScraperAPI ist eine erschwinglichere Option für mittleres Scraping mit JavaScript-Rendering und CAPTCHA-Handhabung.
Arshia ist eine AI Workflow Engineerin bei FlowHunt. Mit einem Hintergrund in Informatik und einer Leidenschaft für KI spezialisiert sie sich darauf, effiziente Arbeitsabläufe zu entwickeln, die KI-Tools in alltägliche Aufgaben integrieren und so Produktivität und Kreativität steigern.
Arshia Kahani
AI Workflow Engineerin
Scrape Any Website with AI — Try FlowHunt Free
FlowHunt's AI agents browse the web, extract structured data, and feed it into your workflows automatically — no scraping scripts required.
Beste Browse AI Alternativen in 2026: 8 Web-Scraping-Tools im Vergleich
Suchen Sie nach Browse AI Alternativen? Wir haben 8 Web-Scraping- und Datenextraktions-Tools verglichen — von KI-gestützten Scrapern bis zu vollständigen Automa...
10 beste KI-Web-Scraper 2026: Gerankt und getestet
Die 10 besten KI-Web-Scraper 2026, gerankt nach Extraktionsgenauigkeit, Benutzerfreundlichkeit, Anti-Bot-Handling und Preisgestaltung. Finden Sie das richtige K...
Integrieren Sie FlowHunt mit dem Apify Actors MCP Server, um groß angelegtes Web-Scraping, Datenextraktion und das Management von Actors mithilfe KI-gestützter ...
3 Min. Lesezeit
AI
Apify
+5
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.