8 Migliori Alternative a Apify nel 2026 (Web Scraping ed Estrazione Dati)
Apify è potente ma complesso e costoso per la maggior parte dei casi d’uso. Abbiamo confrontato 8 alternative a Apify per il web scraping e l’estrazione dati — da strumenti senza codice a API per sviluppatori.
Apify è una delle piattaforme di web scraping e automazione più potenti disponibili — ma è costruita per sviluppatori, richiede l’apprendimento del suo sistema di Actor ed i costi aumentano rapidamente per lo scraping ad alto volume. Se stai cercando qualcosa di più semplice, più economico o più adatto ai flussi di lavoro AI, ci sono alternative solide.
Cos’è Apify?
Apify è una piattaforma di web scraping e automazione del browser basata su cloud. La sua unità principale è l’“Actor” — uno script di scraping o automazione riutilizzabile e condivisibile che viene eseguito nell’infrastruttura cloud di Apify. Gli utenti possono creare Actor personalizzati in Node.js utilizzando l’SDK di Apify, oppure utilizzare Actor pre-costruiti dall’Apify Store per attività di scraping comuni (dati di prodotti Amazon, elenchi di Google Maps, profili LinkedIn, contenuti social media).
Apify gestisce le sfide infrastrutturali del web scraping: rendering JavaScript con browser headless, rotazione dei proxy per evitare i ban degli IP, gestione dei CAPTCHA, programmazione e archiviazione dei risultati. Questo lo rende considerevolmente più potente rispetto all’esecuzione di scraper in locale.
Il compromesso: Apify richiede competenze di sviluppo per creare Actor personalizzati, il suo prezzo scala con il tempo di calcolo (che può diventare costoso per lo scraping continuo) e il paradigma di Actor ha una curva di apprendimento.
Confronto Rapido: Apify vs Alternative
Strumento
Migliore Per
Tier Gratuito
Prezzo di Partenza
Senza Codice
Nativo AI
FlowHunt
Estrazione integrata con AI
✅
Basato su utilizzo
✅
✅
Apify
Scraper personalizzati per sviluppatori
✅
$49/mese
❌
Parziale
Browse AI
Scraping di siti senza codice
✅
$48/mese
✅
Parziale
Firecrawl
Preparazione dati LLM/AI
✅
$16/mese
Parziale
✅
Octoparse
Scraping visuale point-and-click
✅
$75/mese
✅
❌
ScraperAPI
Rendering JS basato su API
✅
$49/mese
❌
❌
Bright Data
Estrazione su scala aziendale
❌
Personalizzato
❌
Parziale
PhantomBuster
Estrazione LinkedIn/social
✅
$56/mese
✅
❌
Bardeen
Automazione dei compiti del browser
✅
$10/mese
✅
✅
Pronto a far crescere il tuo business?
Inizia oggi la tua prova gratuita e vedi i risultati in pochi giorni.
1. FlowHunt — Migliore per l’Estrazione Dati Web Integrata con AI
FlowHunt affronta l’estrazione dati web diversamente da Apify: invece di creare scraper autonomi, crei agenti AI che navigano il web come parte di flussi di lavoro automatizzati più ampi. L’agente può navigare verso un URL, leggere il contenuto della pagina, estrarre informazioni specifiche e utilizzare immediatamente quei dati nel passaggio successivo — alimentandoli in un CRM, generando un riepilogo o attivando una sequenza di outreach.
Questo è un caso d’uso fondamentalmente diverso dallo scraping batch di milioni di pagine — FlowHunt eccelle nell’estrazione intelligente e mirata come parte di un processo aziendale.
Vantaggi principali rispetto a Apify:
Nessuno script di scraping — Gli agenti AI navigano ed estraggono in base a istruzioni in linguaggio naturale
Flusso di lavoro integrato — I dati estrattti alimentano immediatamente i passaggi di automazione successivi
Gestisce pagine non strutturate — L’IA comprende il contenuto semanticamente, non solo dai selettori CSS
Integrazioni integrate — Invia dati estratti a CRM, Slack, fogli o qualsiasi altro di 1.400+ strumenti
Nessuna gestione dell’infrastruttura — Completamente ospitato e scalato
Casi d’uso migliori:
Monitoraggio dei prezzi dei concorrenti o dei cambiamenti di prodotto
Estrazione di dati di lead dai siti web aziendali
Automazione della ricerca (lettura di articoli, estrazione di fatti chiave)
Integrazione dei dati web in pipeline di sintesi o analisi AI
Non ideale per: Scraping batch ad alto volume di migliaia di pagine contemporaneamente (usa ScraperAPI o Bright Data per quello).
Prezzo: Tier gratuito disponibile. Il prezzo basato sull’utilizzo scala con le esecuzioni effettive del flusso di lavoro.
2. Browse AI — Migliore Alternativa di Web Scraping Senza Codice
Browse AI è l’alternativa a Apify più semplice per i non sviluppatori. Navighi verso il sito web che vuoi scrapare, mostri a Browse AI quali dati estrarre facendo clic su di essi e crea un “robot” che ripete l’estrazione secondo una pianificazione.
Gestisce siti resi dinamicamente con JavaScript, paginazione e pagine protette da login — senza alcun codice.
Gestisce pagine rese con JavaScript e protette da login
Estrazione pianificata e monitoraggio automatico dei cambiamenti
Robot pre-costruiti per Amazon, LinkedIn, Google Maps e altro
Integrazione webhook e Google Sheets
Esportazione dati bulk in CSV, JSON e fogli di calcolo
Pro: Veramente senza codice — configura in minuti con interfaccia point-and-click; gestisce bene i siti ricchi di JavaScript; monitoraggio pianificato e rilevamento dei cambiamenti integrati; robot pre-costruiti per siti comuni
Contro: Flessibilità limitata per la logica di estrazione personalizzata complessa; scala meno bene rispetto ad Apify per lo scraping ad altissimo volume; il prezzo per esecuzione può essere imprevedibile per siti frequentemente modificati
Migliore per: Utenti non tecnici che hanno bisogno di estrazione ricorrente da siti web specifici senza scrivere codice o gestire l’infrastruttura.
Iscriviti alla nostra newsletter
Ricevi gratuitamente gli ultimi consigli, tendenze e offerte.
3. Firecrawl — Migliore per i Dati di Applicazioni LLM e AI
Firecrawl è costruita appositamente per un caso d’uso specifico: trasformare interi siti web in markdown pulito che gli LLM possono leggere. Esegue il crawling dei siti web, esegue il rendering JavaScript, gestisce la paginazione e produce testo strutturato e pulito — ideale per costruire basi di conoscenza RAG (Retrieval-Augmented Generation) o alimentare contenuti web agli agenti AI.
Prezzo:
Gratuito — 500 crediti/mese, fino a 500 pagine scrapate
Hobby — $16/mese. 3.000 crediti/mese, accesso API completo, supporto di base
Standard — $83/mese. 100.000 crediti/mese, limiti di velocità superiori, supporto prioritario
Enterprise — Contatta le vendite per volume personalizzato, SLA e opzioni on-premise
Caratteristiche principali:
Converte interi siti web in output markdown pulito e ottimizzato per LLM
Crawling completo del sito web con scoperta di sitemap e link
Rendering JavaScript per applicazioni a pagina singola dinamiche
Endpoint di estrazione per estrazione dati strutturata con schema
Endpoint di ricerca per ricerca web alimentata da IA
API REST semplice con SDK per Python, Node.js, Go e Rust
Pro: Output markdown pronto per LLM pulito — nessuna pulizia HTML necessaria; crawling completo del sito web con supporto sitemap; mappa e esegue il crawling di siti JavaScript dinamici; API semplice — integra in minuti
Contro: Non adatto per estrarre dati strutturati (prezzi, specifiche dei prodotti) — produce testo, non record strutturati; nessun generatore visuale — solo API per sviluppatori; non progettato per casi di monitoraggio pianificato
Migliore per: Sviluppatori che costruiscono agenti AI, pipeline RAG o applicazioni LLM che hanno bisogno di contenuti web puliti e strutturati come input.
4. Octoparse — Migliore Scraper Visuale con Esecuzione Cloud
Octoparse fornisce un’applicazione desktop con un’interfaccia point-and-click per creare scraper visivamente, quindi li esegue nel cloud secondo una pianificazione. Gestisce la maggior parte degli scenari di scraping comuni — paginazione, scorrimento infinito, navigazione nei menu a discesa — senza codice.
Prezzo:
Gratuito — Limitato a 10.000 record per esportazione, scraping solo locale (non cloud)
Standard — $75/mese. Scraping cloud, 10 attività cloud, programmazione, accesso API
Professional — $149/mese. 30 attività cloud, rotazione IP, esecuzione cloud più veloce, supporto prioritario
Enterprise — Contatta le vendite. Attività illimitate, server dedicato, integrazioni personalizzate, SLA
Caratteristiche principali:
Generatore di flusso di lavoro visuale — nessun codice necessario
Esecuzione cloud con programmazione e rotazione IP automatica
Gestisce paginazione complessa, scorrimento infinito e flussi multi-pagina
Gestione integrata dei CAPTCHA e meccanismi anti-blocco
Esportazione in Excel, CSV, Google Sheets e database (MySQL, SQL Server)
1.000+ modelli pre-costruiti per siti web comuni
Pro: Generatore di flusso di lavoro visuale — nessun codice necessario; esecuzione cloud con programmazione e rotazione IP; gestisce paginazione complessa e flussi multi-pagina; esportazione in Excel, CSV, Google Sheets, database
Contro: Più costoso rispetto alle alternative per capacità equivalenti; client desktop (Windows/Mac) aggiunge attrito rispetto agli strumenti basati su browser; meno adatto per l’estrazione in tempo reale rispetto alle esecuzioni batch pianificate
Migliore per: Analisti non tecnici e team operativi che hanno bisogno di estrazione dati pianificata affidabile da siti web complessi o paginati.
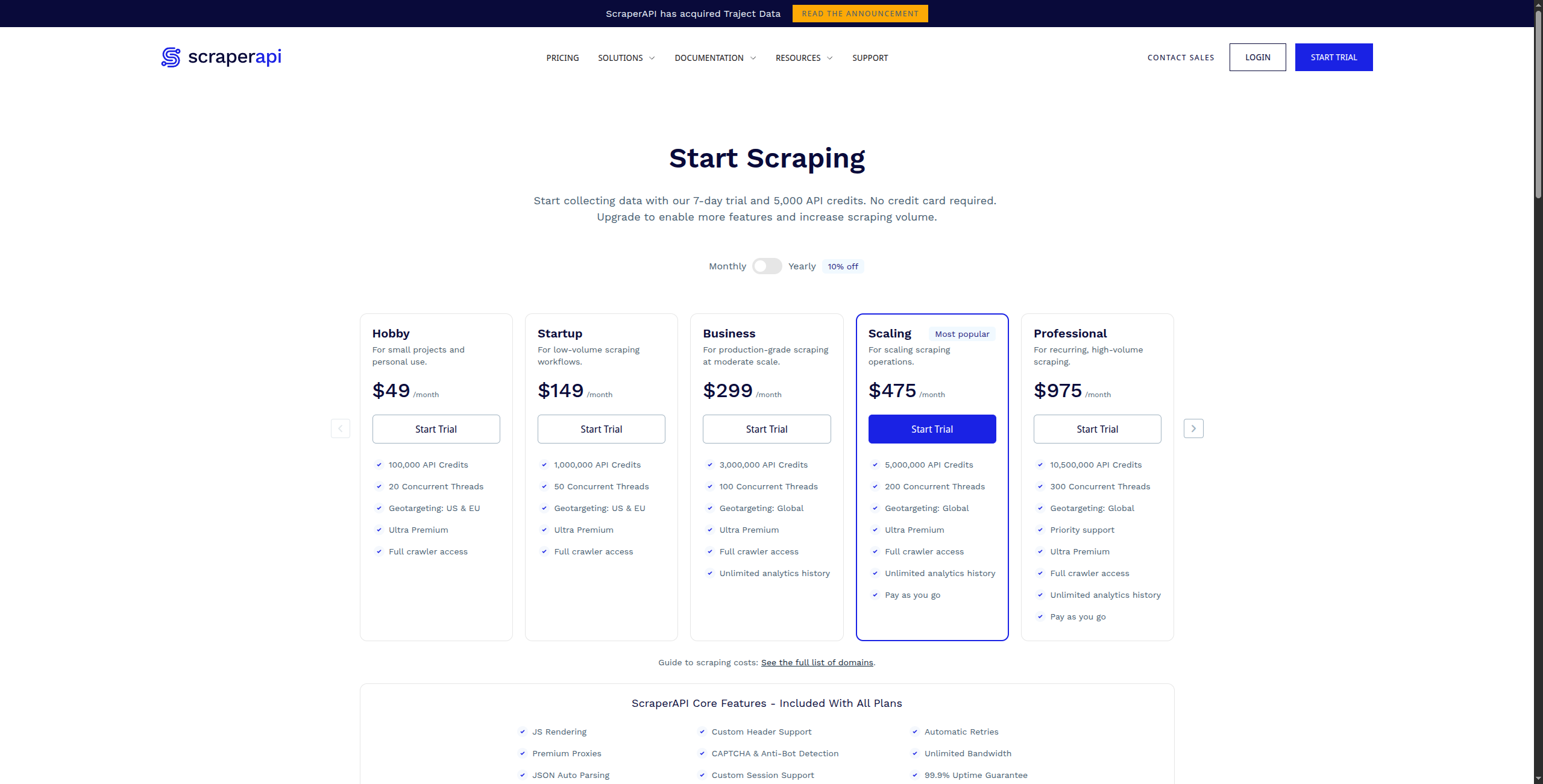
5. ScraperAPI — Migliore per Proxy e Rendering di Livello Sviluppatore
ScraperAPI è un servizio API che gestisce le parti più difficili del web scraping su larga scala: rendering JavaScript, risoluzione dei CAPTCHA e rotazione automatica dei proxy. Gli sviluppatori inviano un URL a ScraperAPI e ricevono indietro HTML pulito — gestisce tutto nel mezzo.
Prezzo:
Gratuito — 1.000 chiamate API/mese, fino a 5 richieste simultanee
Enterprise — Contatta le vendite per volume personalizzato e infrastruttura dedicata
Caratteristiche principali:
Una singola chiamata API restituisce HTML renderizzato da qualsiasi URL
Rotazione automatica dei proxy con 40M+ IP residenziali e datacenter
Rendering JavaScript tramite Chrome headless per SPA e siti dinamici
Risoluzione dei CAPTCHA e bypass delle misure anti-bot
Geo-targeting con selezione proxy specifica per paese
Endpoint dati strutturati per Amazon, Google, Walmart e altro
Pro: Integrazione API semplice — una chiamata di funzione sostituisce l’infrastruttura di scraping complessa; gestisce CAPTCHA, geo-targeting ed emulazione dei dispositivi; endpoint dati strutturati per siti comuni (Amazon, Google, eBay); costo inferiore rispetto a Apify per lo scraping semplice ad alto volume
Contro: Restituisce HTML — devi comunque analizzare ed estrarre i dati tu stesso; nessun generatore visuale o interfaccia senza codice; nessuna programmazione o monitoraggio — solo un livello di rendering/proxy
Migliore per: Sviluppatori che costruiscono scraper che hanno bisogno di infrastruttura proxy e rendering affidabile e scalabile senza gestire il proprio pool di proxy.
6. Bright Data — Migliore Piattaforma Dati Web Aziendale
Bright Data gestisce una delle più grandi reti proxy del mondo (72M+ IP) e fornisce una suite completa di prodotti per dati web: reti proxy, API di scraping, automazione del browser e set di dati pre-costruiti per centinaia di siti web popolari. Per le esigenze di dati web su scala aziendale, è inarrivabile.
Prezzo:
Pay-as-you-go — Disponibile su tutti i prodotti; proxy datacenter da $0,6/GB, proxy residenziali da $8,4/GB, proxy ISP da $15/GB
Piani mensili — A partire da ~$500/mese per piani proxy datacenter; sconti per volumi impegnati più elevati
Scraping Browser — Da $0,1/GB di larghezza di banda consumata
Web Scraper API — Da $1,50/1.000 richieste per endpoint dati strutturati
Set di dati — Set di dati pre-costruiti per Amazon, LinkedIn, Instagram da $0,001/record; consegna set di dati personalizzati contatta le vendite
Enterprise — Contatta le vendite per infrastruttura dedicata, garanzie di conformità e SLA
Caratteristiche principali:
Rete proxy 72M+ IP — proxy residenziali, datacenter, ISP e mobili
API Scraping Browser per automazione completa del browser su larga scala
Web Scraper IDE per creare e gestire scraper personalizzati
Set di dati strutturati pre-costruiti per 100+ siti web popolari
Raccolta dati conforme con processi di revisione legale
SLA aziendale con garanzia di uptime del 99,9%
Pro: La più grande rete proxy del mondo — migliore per bypassare la protezione anti-bot avanzata; set di dati pre-costruiti per casi d’uso comuni (Amazon, LinkedIn, social media); Web Scraper IDE per creare scraper personalizzati; garanzie di conformità e qualità dei dati aziendali
Contro: Prezzo complesso — più prodotti con modelli di costo diversi; eccessivo per le esigenze di scraping piccole o medie; richiede risorse tecniche per implementare bene
Migliore per: Team aziendali con esigenze di scraping ad alto volume, requisiti di conformità rigorosi o requisiti di evasione anti-bot avanzati.
7. PhantomBuster — Migliore per l’Estrazione Dati dai Social Media
PhantomBuster si specializza nell’estrazione di dati e nell’automazione di azioni su piattaforme social — LinkedIn, Twitter/X, Instagram, Facebook, Google Maps e altro. Non è uno scraper web generale ma eccelle nella sua nicchia.
Prezzo:
Prova gratuita — 14 giorni, accesso completo a tutti i Phantom
Starter — $56/mese. 20 ore di tempo di esecuzione/mese, 5 Phantom in esecuzione simultanea, supporto email
Pro — $128/mese. 80 ore di tempo di esecuzione/mese, 15 Phantom simultaneamente, supporto prioritario
Team — $352/mese. 300 ore di tempo di esecuzione/mese, Phantom simultanei illimitati, supporto dedicato
Enterprise — Contatta le vendite per tempo di esecuzione personalizzato e volume
Caratteristiche principali:
100+ “Phantom” pre-costruiti per LinkedIn, Twitter, Instagram, Facebook e Google Maps
Scraping di LinkedIn: dati di profilo, pagine aziendali, risultati di ricerca di Sales Navigator, coinvolgimento dei post
Sequenze di outreach automatizzate con richieste di connessione e messaggi
Esportazione in CSV, Google Sheets, webhook CRM
Esecuzioni pianificate con throttling configurabile per ridurre il rischio dell’account
Gestione multi-account per l’uso dell’agenzia
Pro: Phantom pre-costruiti per scenari comuni di scraping social; estrazione di lead LinkedIn senza script di scraping; automazione (visite di profilo, richieste di connessione) insieme all’estrazione di dati; interfaccia senza codice per la maggior parte dei casi d’uso
Contro: Specifico della piattaforma — non utile per lo scraping di siti web arbitrari; rischio di conformità ai TOS di LinkedIn con l’automazione; limiti di tempo di esecuzione inferiori su piani inferiori
Migliore per: Team di vendita e marketer della crescita che hanno bisogno di estrarre e agire sui dati di LinkedIn e social media per la generazione di lead e l’outreach.
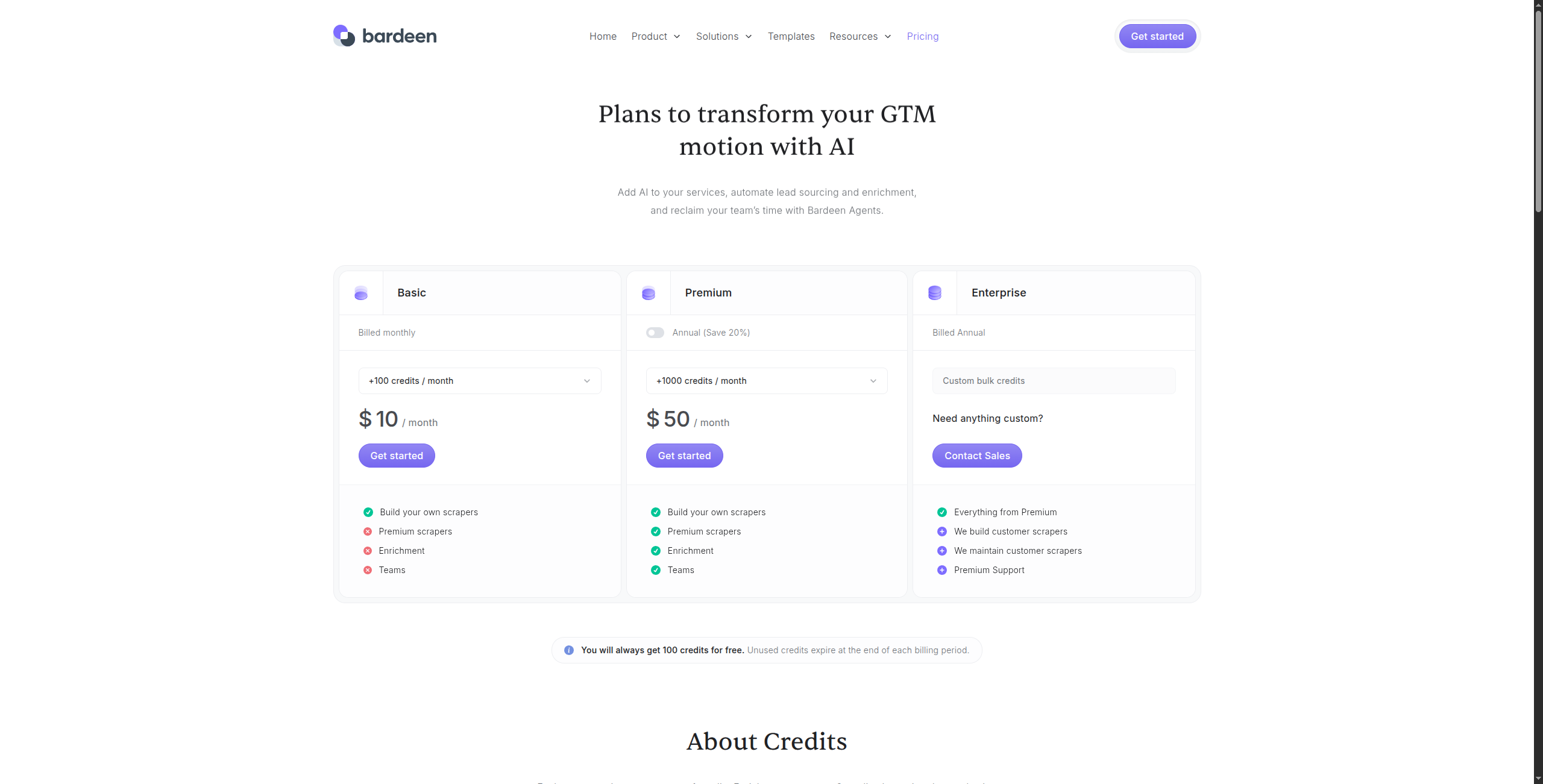
8. Bardeen — Migliore per l’Automazione dei Compiti del Browser
Bardeen è un’estensione Chrome che registra e riproduce azioni del browser, estrae dati dalle pagine che stai visualizzando e integra i dati estratti con oltre 100 app. È migliore per l’estrazione semi-automatizzata e su richiesta piuttosto che per lo scraping completamente automatico.
Prezzo:
Gratuito — Esecuzioni manuali illimitate, integrazioni di base, supporto della comunità
Business — $15/utente/mese. Condivisione di automazioni del team, cartelle condivise, controlli di amministrazione
Enterprise — Contatta le vendite per SSO, sicurezza avanzata e integrazioni personalizzate
Caratteristiche principali:
AI Magic Actions — descrivi in inglese semplice cosa estrarre, nessun selettore CSS necessario
Registra e riproduce azioni del browser come automazioni ripetibili
Si integra con 100+ app: Notion, Airtable, HubSpot, Salesforce, Google Sheets
Esegue lo scraping di tabelle, elenchi e dati strutturati da qualsiasi pagina visibile
Viene eseguito nel browser Chrome — funziona su qualsiasi sito a cui l’utente può accedere
Supporta automazione basata su trigger (basata su tempo, webhook o manuale)
Pro: Estensione Chrome senza codice — zero setup; azioni AI magic per estrarre dati per descrizione, non per selettori CSS; forti integrazioni con Notion, Airtable, HubSpot, Salesforce; buono per flussi di lavoro di produttività personale e ricerca
Contro: Richiede Chrome aperto — non automazione completamente automatica; non adatto per lo scraping lato server ad alto volume; limitato a ciò a cui l’utente connesso può accedere in un browser
Migliore per: Collaboratori individuali e piccoli team che hanno bisogno di automatizzare attività ripetitive di ricerca del browser e raccolta dati senza scrivere codice.
Quale Alternativa a Apify Dovresti Scegliere?
Estrazione integrata con AI per flussi di lavoro aziendali → FlowHunt
Monitoraggio e estrazione di siti senza codice → Browse AI
Trasformazione di siti web in basi di conoscenza AI → Firecrawl
Scraping visuale di siti complessi → Octoparse
API per sviluppatori per proxy e rendering JavaScript → ScraperAPI
Scraping su scala aziendale con evasione anti-bot → Bright Data
Estrazione dati da LinkedIn e social media → PhantomBuster
Attività di estrazione su richiesta del browser → Bardeen
Per la maggior parte dei casi d’uso aziendali — monitoraggio dei concorrenti, estrazione di dati di lead, ricerca di prospect — l’approccio nativo all’IA di FlowHunt batte il modello incentrato sullo sviluppatore di Apify sia in termini di velocità di configurazione che di integrazione del flusso di lavoro. Per progetti di scraping tecnico ad alto volume, ScraperAPI e Bright Data sono gli strumenti giusti.
Domande frequenti
Apify è una piattaforma di web scraping e automazione che consente agli sviluppatori di creare, distribuire ed eseguire web scraper — chiamati "Actors" — nel cloud. Gestisce il rendering JavaScript, la rotazione dei proxy e la programmazione. Gli utenti possono creare scraper personalizzati o utilizzare Actors pre-costruiti dall'Apify Store per siti comuni come Amazon, LinkedIn, Google Maps e social media.
Sì — Browse AI ha un piano gratuito (50 esecuzioni/mese), Bardeen è gratuito per le automazioni di base, Firecrawl ha un livello API gratuito e il tier gratuito di FlowHunt include capacità di navigazione web. Per gli sviluppatori, librerie open-source come Playwright, Puppeteer e Scrapy sono gratuite ma richiedono gestione autonoma.
Browse AI è la più semplice — letteralmente le mostri cosa scrapare facendo clic su un sito web e costruisce automaticamente lo scraper. Octoparse è altrettanto point-and-click. Bardeen è il migliore per attività di estrazione dati una tantum dove vuoi automatizzare azioni ripetitive del browser senza alcuna configurazione tecnica.
Firecrawl è costruita appositamente per le applicazioni AI — converte interi siti web in markdown pulito e strutturato che gli LLM possono consumare direttamente. FlowHunt integra l'estrazione web nei flussi di lavoro degli agenti AI, rendendola la scelta migliore quando i dati estratti devono alimentare passaggi di ragionamento, sintesi o processo decisionale.
Per le esigenze di dati web su scala aziendale (milioni di pagine, evasione anti-bot complessa), Bright Data è l'alternativa più forte — gestisce una delle più grandi reti proxy del mondo e dispone di infrastruttura di scraping di livello aziendale. ScraperAPI è un'opzione più conveniente per lo scraping su scala media con rendering JavaScript e gestione dei CAPTCHA.
Arshia è una AI Workflow Engineer presso FlowHunt. Con una formazione in informatica e una passione per l'IA, è specializzata nella creazione di workflow efficienti che integrano strumenti di intelligenza artificiale nelle attività quotidiane, migliorando produttività e creatività.
Arshia Kahani
AI Workflow Engineer
Scrape Any Website with AI — Try FlowHunt Free
FlowHunt's AI agents browse the web, extract structured data, and feed it into your workflows automatically — no scraping scripts required.
Migliori Alternative a Browse AI nel 2026: 8 Strumenti di Web Scraping Confrontati
Stai cercando alternative a Browse AI? Abbiamo confrontato 8 strumenti di web scraping ed estrazione dati — dai scraper basati su AI alle piattaforme di automaz...
I 10 Migliori AI Web Scraper nel 2026: Classifica e Recensione
I 10 migliori AI web scraper nel 2026, classificati per accuratezza di estrazione, facilità d'uso, gestione anti-bot e prezzi. Trova lo strumento AI di scraping...
Integra FlowHunt con Apify Actors MCP Server per automatizzare e orchestrare su larga scala lo scraping web, l’estrazione dati e la gestione degli actor tramite...
4 min di lettura
AI
Apify
+5
Consenso Cookie Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.