8 najlepszych alternatyw Apify w 2026 roku (Web Scraping i ekstrakcja danych)
Apify to potężna, ale skomplikowana i droga platforma dla większości przypadków użycia. Porównaliśmy 8 alternatyw Apify do web scrapingu i ekstrakcji danych — od narzędzi bez kodu do API dla deweloperów.
Apify to jedna z najpotężniejszych dostępnych platform do web scrapingu i automatyzacji — ale jest zbudowana dla deweloperów, wymaga nauki systemu Actor i koszty szybko się kumulują w przypadku scrapingu o dużej objętości. Jeśli szukasz czegoś prostszego, tańszego lub lepiej dostosowanego do przepływów pracy AI, istnieją silne alternatywy.
Co to jest Apify?
Apify to oparta na chmurze platforma web scrapingu i automatyzacji przeglądarki. Jej jednostką podstawową jest “Actor” — wielokrotnego użytku, wymienialny skrypt scrapingu lub automatyzacji, który działa w infrastrukturze chmury Apify. Użytkownicy mogą budować niestandardowe Actors w Node.js przy użyciu Apify SDK lub używać wstępnie zbudowanych Actors z Apify Store do popularnych zadań scrapingu (dane produktów Amazon, listy Google Maps, profile LinkedIn, zawartość mediów społecznościowych).
Apify obsługuje wyzwania infrastrukturalne web scrapingu: renderowanie JavaScript za pomocą bezgłowych przeglądarek, rotacja proxy, aby uniknąć blokad IP, obsługę CAPTCHA, planowanie i magazynowanie wyników. To czyni go znacznie bardziej potężnym niż uruchamianie scraperów lokalnie.
Kompromis: Apify wymaga umiejętności deweloperskich do budowania niestandardowych Actors, jego ceny skalują się wraz z czasem obliczeń (co może być drogie dla ciągłego scrapingu), a paradygmat Actor ma krzywą uczenia.
1. FlowHunt — najlepszy do ekstrakcji danych internetowych zintegrowanych z AI
FlowHunt podchodzi do ekstrakcji danych internetowych inaczej niż Apify: zamiast budować samodzielne scrapery, budujesz agentów AI, którzy przeglądają sieć w ramach większych zautomatyzowanych przepływów pracy. Agent może przejść do adresu URL, przeczytać zawartość strony, wyodrębnić określone informacje i natychmiast wykorzystać te dane w następnym kroku — wprowadzając je do CRM, generując podsumowanie lub wyzwalając sekwencję outreach.
To jest fundamentalnie inny przypadek użycia niż scraping wsadowy milionów stron — FlowHunt doskonale sprawdza się w inteligentnej, docelowej ekstrakcji jako część procesu biznesowego.
Kluczowe zalety w stosunku do Apify:
Brak skryptów scrapingu — agenci AI nawigują i wyodrębniają na podstawie instrukcji w języku naturalnym
Zintegrowany przepływ pracy — wyodrębnione dane natychmiast trafiają do następnych kroków automatyzacji
Obsługuje nieustrukturyzowane strony — AI rozumie zawartość semantycznie, nie tylko za pomocą selektora CSS
Wbudowane integracje — wysyłaj wyodrębnione dane do CRM, Slack, arkuszy lub dowolnego z ponad 1400 narzędzi
Brak zarządzania infrastrukturą — w pełni hostowana i skalowana
Nie idealne dla: Scraping wsadowy o dużej objętości tysięcy stron naraz (użyj ScraperAPI lub Bright Data do tego).
Ceny: Dostępna bezpłatna warstwa. Ceny oparte na użyciu skalują się wraz z rzeczywistymi przebiegami przepływu pracy.
2. Browse AI — najlepsza alternatywa web scrapingu bez kodu
Browse AI to najłatwiejsza alternatywa Apify dla osób niebędących deweloperami. Przechodzisz do strony internetowej, którą chcesz scrapować, pokazujesz Browse AI, jakie dane wyodrębnić, klikając na nie, a ona buduje “robota”, który powtarza ekstrakcję zgodnie z harmonogramem.
Obsługuje dynamiczne strony renderowane JavaScript, paginację i strony chronione logowaniem — bez żadnego kodu.
Professional — $149/miesiąc. 10000 kredytów, przebiegi priorytetowe, webhooks, przebiegi zbiorcze
Team — $399/miesiąc. 40000 kredytów, wielu członków zespołu, dostęp do API
Enterprise — Skontaktuj się z działem sprzedaży, aby uzyskać niestandardową objętość i SLA
Kluczowe funkcje:
Szkolenie robotów point-and-click — bez kodu wymaganego
Obsługuje strony renderowane JavaScript i chronione logowaniem
Zaplanowana ekstrakcja i automatyczne monitorowanie zmian
Wstępnie zbudowane roboty dla Amazon, LinkedIn, Google Maps i innych
Integracja webhook i Google Sheets
Zbiorczy eksport danych do CSV, JSON i arkuszy kalkulacyjnych
Zalety: Prawdziwie bez kodu — skonfiguruj w minuty za pomocą interfejsu point-and-click; dobrze obsługuje strony bogate w JavaScript; zaplanowane monitorowanie i wykrywanie zmian wbudowane; wstępnie zbudowane roboty dla popularnych stron
Wady: Ograniczona elastyczność dla złożonej logiki ekstrakcji niestandardowej; skaluje się gorzej niż Apify dla bardzo dużego scrapingu; cena za przebieg może być nieprzewidywalna dla często zmieniających się stron
Najlepsze dla: Użytkowników nietechnicznych, którzy potrzebują powtarzającej się ekstrakcji z określonych stron internetowych bez pisania kodu lub zarządzania infrastrukturą.
Dołącz do naszego newslettera
Otrzymuj najnowsze wskazówki, trendy i oferty za darmo.
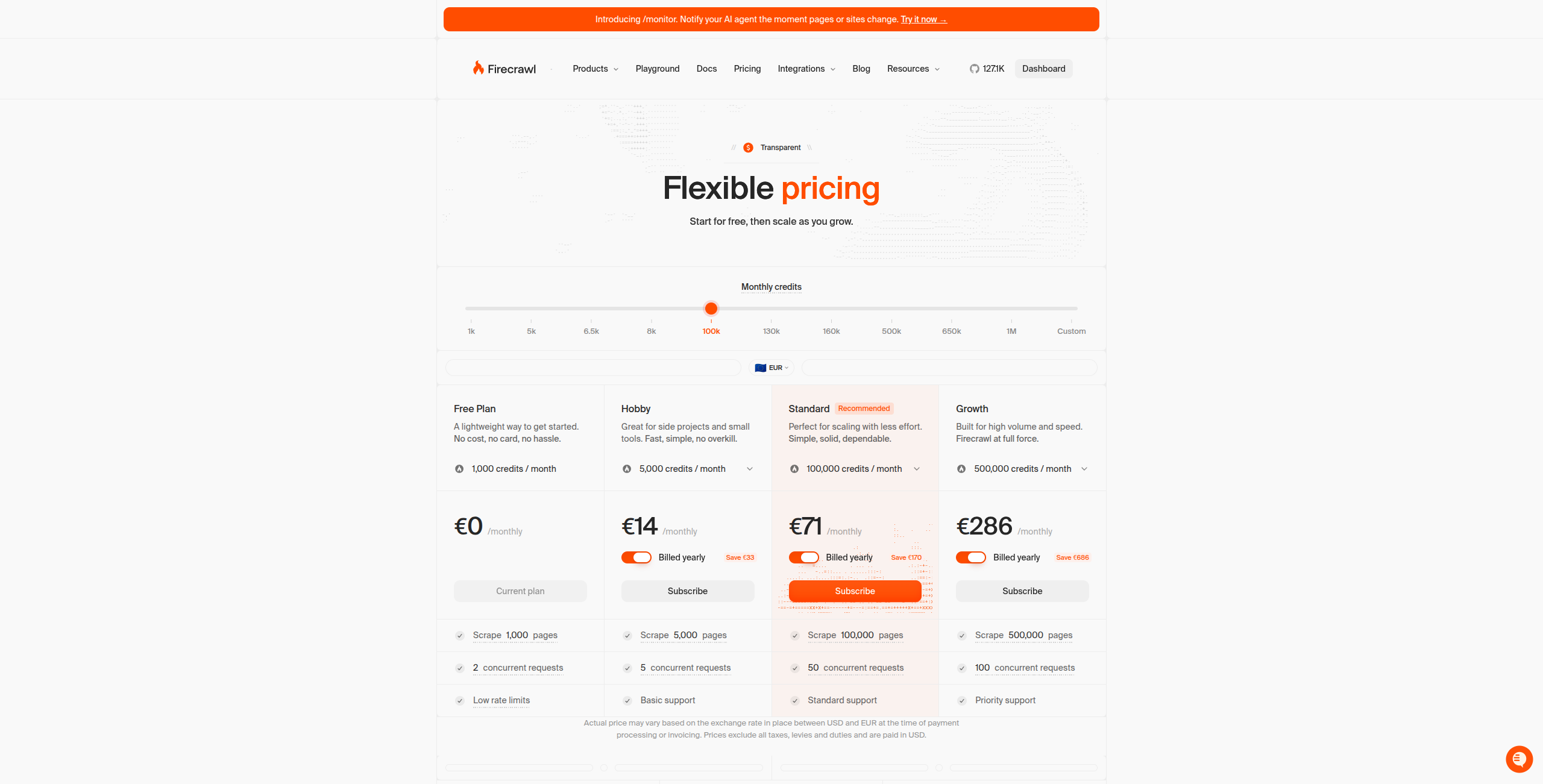
3. Firecrawl — najlepszy dla danych aplikacji LLM i AI
Firecrawl jest stworzona specjalnie dla konkretnego przypadku użycia: zamienianie całych stron internetowych na czysty markdown, który LLM mogą czytać. Crawluje strony internetowe, renderuje JavaScript, obsługuje paginację i wyświetla ustrukturyzowany, czysty tekst — idealny do budowania baz wiedzy RAG (Retrieval-Augmented Generation) lub wprowadzania zawartości internetowej do agentów AI.
Ceny:
Bezpłatny — 500 kredytów/miesiąc, do 500 scrapowanych stron
Hobby — $16/miesiąc. 3000 kredytów/miesiąc, pełny dostęp do API, podstawowe wsparcie
Standard — $83/miesiąc. 100000 kredytów/miesiąc, wyższe limity szybkości, wsparcie priorytetowe
Growth — $333/miesiąc. 500000 kredytów/miesiąc, dedykowane wsparcie, zaawansowane funkcje
Enterprise — Skontaktuj się z działem sprzedaży, aby uzyskać niestandardową objętość, SLA i opcje on-premise
Kluczowe funkcje:
Konwertuje pełne strony internetowe na czysty, zoptymalizowany dla LLM markdown
Pełne crawlowanie stron internetowych z odkrywaniem sitemapy i linków
Renderowanie JavaScript dla dynamicznych aplikacji jednostronicowych
Punkt końcowy ekstrakcji dla ekstrakcji danych strukturalnych ze schematem
Punkt końcowy wyszukiwania dla wyszukiwania internetowego zasilanego AI
Prosty REST API z SDK dla Python, Node.js, Go i Rust
Zalety: Czysty markdown gotowy dla LLM — bez potrzeby czyszczenia HTML; pełne crawlowanie stron internetowych z obsługą sitemapy; mapuje i crawluje dynamiczne strony JavaScript; proste API — integruj w minuty
Wady: Nie nadaje się do wyodrębniania danych strukturalnych (ceny, specyfikacje produktów) — wyświetla tekst, nie rekordy strukturalne; brak konstruktora wizualnego — tylko API dla deweloperów; nie zaprojektowany dla zaplanowanych przypadków użycia monitorowania
Najlepsze dla: Deweloperów budujących agentów AI, potoki RAG lub aplikacje LLM, które potrzebują czystej, ustrukturyzowanej zawartości internetowej jako danych wejściowych.
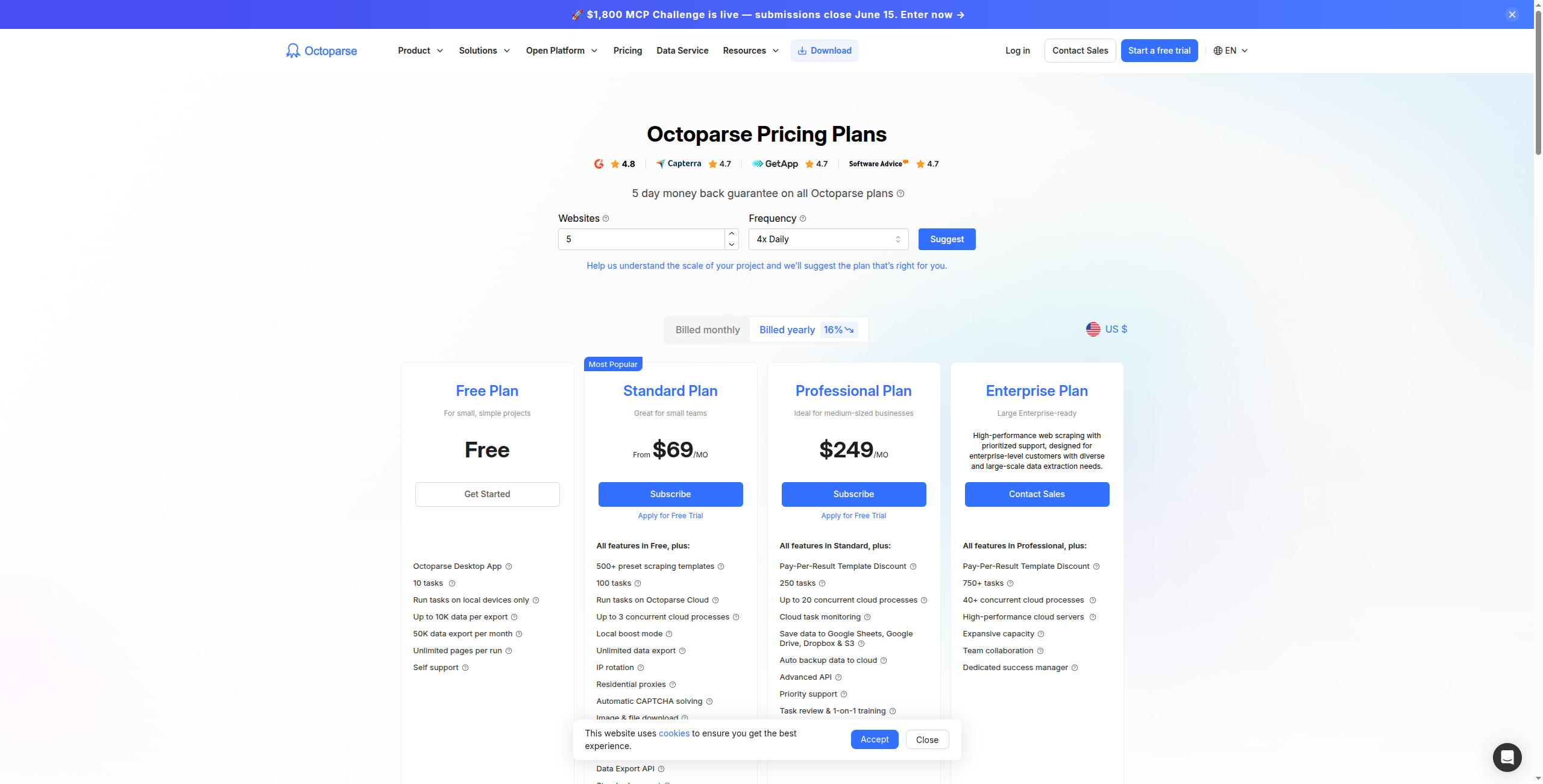
4. Octoparse — najlepszy wizualny scraper z wykonaniem w chmurze
Octoparse zapewnia aplikację desktopową z interfejsem point-and-click do wizualnego budowania scraperów, a następnie uruchamia je w chmurze zgodnie z harmonogramem. Obsługuje większość powszechnych scenariuszy scrapingu — paginację, nieskończone przewijanie, nawigację rozwijającą się — bez kodu.
Ceny:
Bezpłatny — Ograniczony do 10000 rekordów na eksport, scraping lokalny (bez chmury)
Standard — $75/miesiąc. Scraping w chmurze, 10 zadań w chmurze, planowanie, dostęp do API
Professional — $149/miesiąc. 30 zadań w chmurze, rotacja IP, szybsze wykonanie w chmurze, wsparcie priorytetowe
Enterprise — Skontaktuj się z działem sprzedaży. Nieograniczone zadania, dedykowany serwer, niestandardowe integracje, SLA
Kluczowe funkcje:
Konstruktor przepływu pracy wizualnego — bez kodu wymaganego
Wykonanie w chmurze z planowaniem i automatyczną rotacją IP
Obsługuje złożoną paginację, nieskończone przewijanie i przepływy wielostronicowe
Wbudowana obsługa CAPTCHA i mechanizmy przeciwko blokowaniu
Eksport do Excel, CSV, Google Sheets i baz danych (MySQL, SQL Server)
Ponad 1000 wstępnie zbudowanych szablonów dla popularnych stron
Zalety: Konstruktor przepływu pracy wizualnego — bez kodu wymaganego; wykonanie w chmurze z planowaniem i rotacją IP; obsługuje złożoną paginację i przepływy wielostronicowe; eksport do Excel, CSV, Google Sheets, baz danych
Wady: Droższe niż alternatywy dla równoważnych możliwości; klient desktopowy (Windows/Mac) dodaje tarcie w porównaniu z narzędziami opartymi na przeglądarce; mniej odpowiednie dla ekstrakcji w czasie rzeczywistym w porównaniu z zaplanowanymi przebiegami wsadowymi
Najlepsze dla: Nietechnicznych analityków i zespołów operacyjnych, którzy potrzebują niezawodnej ekstrakcji zaplanowanych danych ze złożonych lub paginowanych stron.
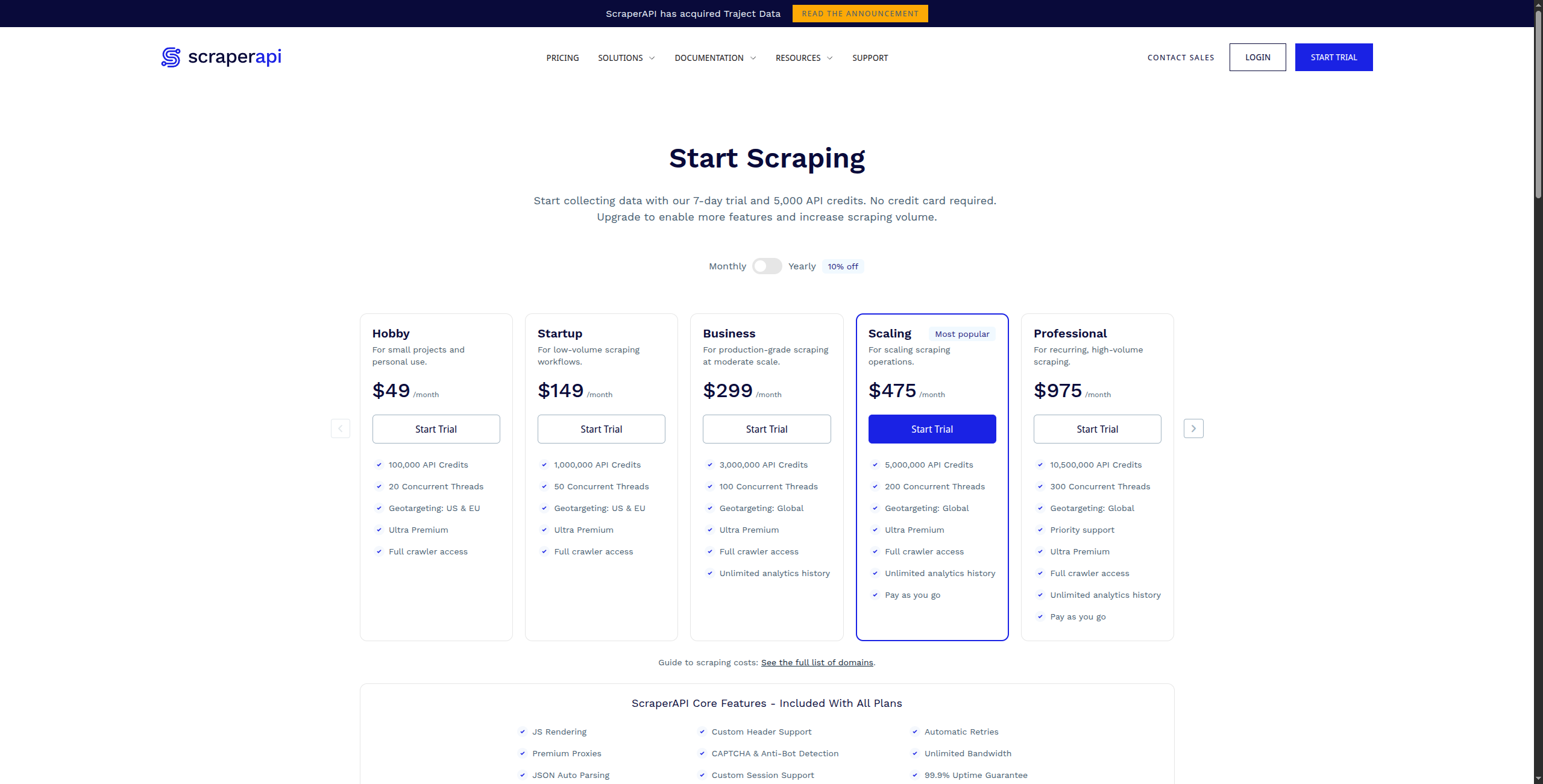
5. ScraperAPI — najlepszy dla proxy i renderowania na poziomie deweloperskim
ScraperAPI to usługa API, która obsługuje najtrudniejsze części web scrapingu na skalę: renderowanie JavaScript, rozwiązywanie CAPTCHA i automatyczną rotację proxy. Deweloperzy wysyłają adres URL do ScraperAPI i otrzymują czysty HTML — obsługuje wszystko pomiędzy.
Ceny:
Bezpłatny — 1000 wywołań API/miesiąc, do 5 jednoczesnych żądań
Enterprise — Skontaktuj się z działem sprzedaży, aby uzyskać niestandardową objętość i dedykowaną infrastrukturę
Kluczowe funkcje:
Jedno wywołanie API zwraca renderowany HTML z dowolnego adresu URL
Automatyczna rotacja proxy z ponad 40 milionami rezydencjalnych i datacenter IP
Renderowanie JavaScript za pomocą bezgłowego Chrome dla SPA i dynamicznych stron
Rozwiązywanie CAPTCHA i omijanie środków ochrony przed botami
Geo-targeting z wyborem proxy specyficznym dla kraju
Punkty końcowe danych strukturalnych dla Amazon, Google, Walmart i innych
Zalety: Prosta integracja API — jedno wywołanie funkcji zastępuje złożoną infrastrukturę scrapingu; obsługuje CAPTCHA, geo-targeting i emulację urządzenia; punkty końcowe danych strukturalnych dla popularnych stron (Amazon, Google, eBay); niższy koszt niż Apify dla scrapingu o dużej objętości
Wady: Zwraca HTML — wciąż musisz samodzielnie parsować i wyodrębniać dane; brak konstruktora wizualnego lub interfejsu bez kodu; brak planowania lub monitorowania — tylko warstwa renderowania/proxy
Najlepsze dla: Deweloperów budujących scrapery, którzy potrzebują niezawodnej, skalowalnej infrastruktury proxy i renderowania bez zarządzania własną pulą proxy.
6. Bright Data — najlepsza platforma danych internetowych dla przedsiębiorstw
Bright Data obsługuje jedną z największych sieci proxy na świecie (ponad 72 miliony IP) i zapewnia pełny zestaw produktów danych internetowych: sieci proxy, interfejsy API scrapingu, automatyzacja przeglądarki i wstępnie zbudowane zestawy danych dla setek popularnych stron. Dla potrzeb danych internetowych na skalę przedsiębiorstwa jest niezrównana.
Ceny:
Płatność za użycie — dostępne dla wszystkich produktów; proxy datacenter od $0,6/GB, proxy rezydencjalne od $8,4/GB, proxy ISP od $15/GB
Plany miesięczne — począwszy od około $500/miesiąc dla planów proxy datacenter; rabaty za wyższe zobowiązane objętości
Scraping Browser — Od $0,1/GB zużytej przepustowości
Web Scraper API — Od $1,50/1000 żądań dla punktów końcowych danych strukturalnych
Zestawy danych — Wstępnie zbudowane zestawy danych dla Amazon, LinkedIn, Instagram od $0,001/rekord; niestandardowe dostarczanie zestawów danych — skontaktuj się z działem sprzedaży
Enterprise — Skontaktuj się z działem sprzedaży, aby uzyskać dedykowaną infrastrukturę, gwarancje zgodności i SLA
Kluczowe funkcje:
Sieć proxy 72M+ IP — rezydencjalne, datacenter, ISP i mobilne proxy
Scraping Browser API dla pełnej automatyzacji przeglądarki na skalę
Web Scraper IDE do budowania i zarządzania niestandardowymi scraperami
Wstępnie zbudowane zestawy danych strukturalnych dla ponad 100 popularnych stron
Zbieranie danych na poziomie zgodności z przeglądem prawnym
Enterprise SLA z gwarancją 99,9% czasu pracy
Zalety: Największa sieć proxy na świecie — najlepsza do omijania zaawansowanej ochrony przed botami; wstępnie zbudowane zestawy danych dla popularnych przypadków użycia (Amazon, LinkedIn, media społecznościowe); Web Scraper IDE do budowania niestandardowych scraperów; gwarancje zgodności i jakości danych na poziomie przedsiębiorstwa
Wady: Skomplikowana cena — wiele produktów z różnymi modelami kosztów; przesada dla małych lub średnich potrzeb scrapingu; wymaga zasobów technicznych do dobrego wdrożenia
Najlepsze dla: Zespołów przedsiębiorstw z potrzebami scrapingu o dużej objętości, ścisłymi wymogami zgodności lub zaawansowanymi wymaganiami unikania bot-ochrony.
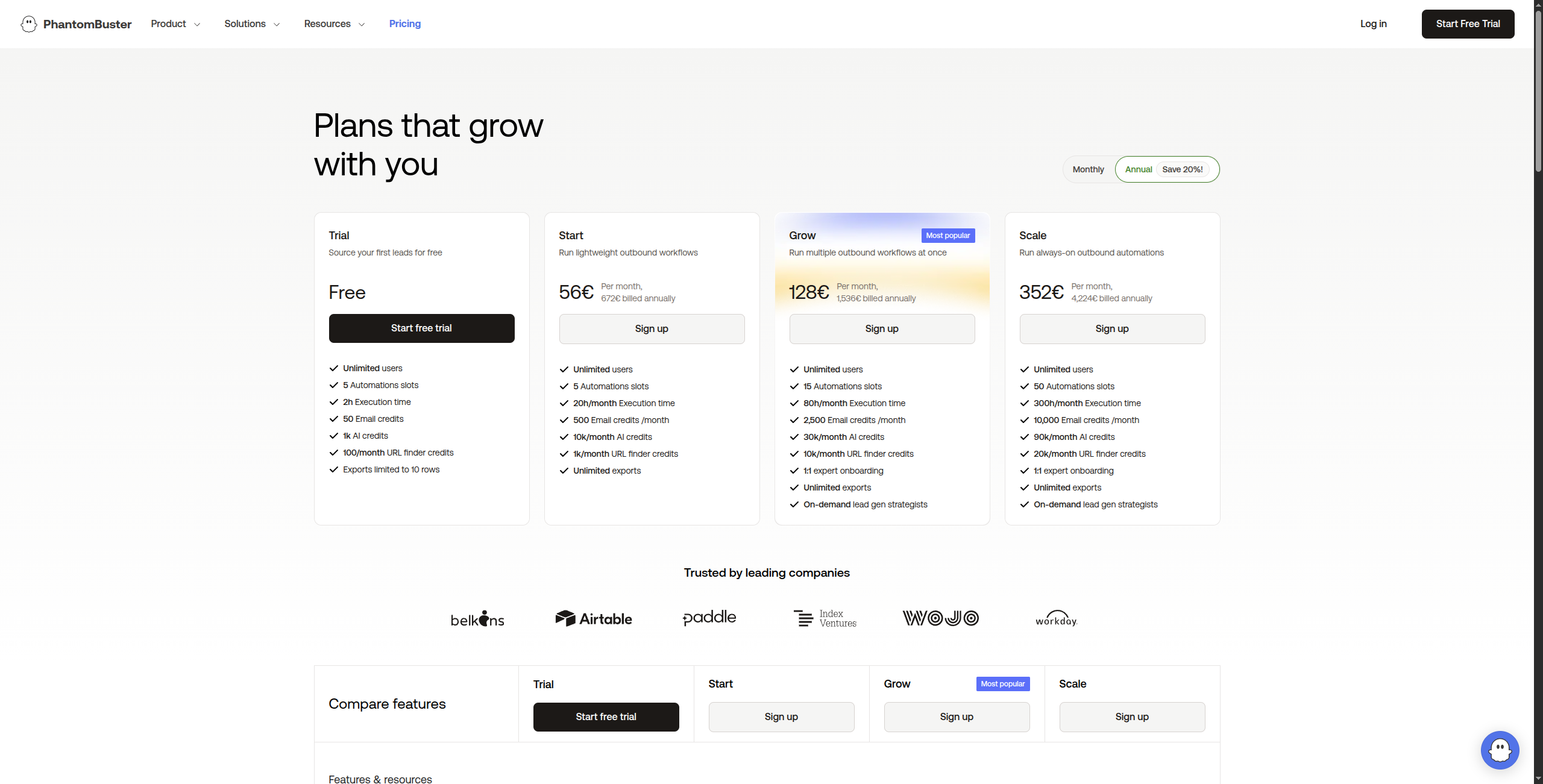
7. PhantomBuster — najlepszy do ekstrakcji danych mediów społecznych
PhantomBuster specjalizuje się w wyodrębnianiu danych i automatyzacji działań na platformach społecznych — LinkedIn, Twitter/X, Instagram, Facebook, Google Maps i inne. To nie jest ogólny web scraper, ale doskonale sprawdza się w swojej niszy.
Ceny:
Bezpłatny okres próbny — 14 dni, pełny dostęp do wszystkich Phantoms
Starter — $56/miesiąc. 20 godzin czasu wykonania/miesiąc, 5 Phantoms uruchomionych jednocześnie, wsparcie e-mail
Pro — $128/miesiąc. 80 godzin czasu wykonania/miesiąc, 15 Phantoms jednocześnie, wsparcie priorytetowe
Team — $352/miesiąc. 300 godzin czasu wykonania/miesiąc, nieograniczone jednoczesne Phantoms, dedykowane wsparcie
Enterprise — Skontaktuj się z działem sprzedaży, aby uzyskać niestandardowy czas wykonania i objętość
Kluczowe funkcje:
Ponad 100 wstępnie zbudowanych “Phantoms” dla LinkedIn, Twitter, Instagram, Facebook i Google Maps
Scraping LinkedIn: dane profilu, strony firm, wyniki Sales Navigator, zaangażowanie postów
Zautomatyzowane sekwencje outreach z żądaniami połączenia i wiadomościami
Eksport do CSV, Google Sheets, webhooks CRM
Zaplanowane przebiegi z konfigurowaniem throttlingu w celu zmniejszenia ryzyka konta
Zarządzanie wieloma kontami dla użytku agencji
Zalety: Wstępnie zbudowane phantoms dla powszechnych scenariuszy scrapingu społecznego; ekstrakcja potencjalnych klientów LinkedIn bez skryptów scrapingu; automatyzacja (wizyty profilu, żądania połączenia) obok ekstrakcji danych; interfejs bez kodu dla większości przypadków użycia
Wady: Specyficzne dla platformy — nieprzydatne dla arbitralnego scrapingu stron; ryzyko zgodności TOS LinkedIn z automatyzacją; niższe limity czasu wykonania na niższych planach
Najlepsze dla: Zespołów sprzedaży i marketerów wzrostu, którzy potrzebują wyodrębniania i działania na danych LinkedIn i mediów społecznych do generowania potencjalnych klientów i outreach.
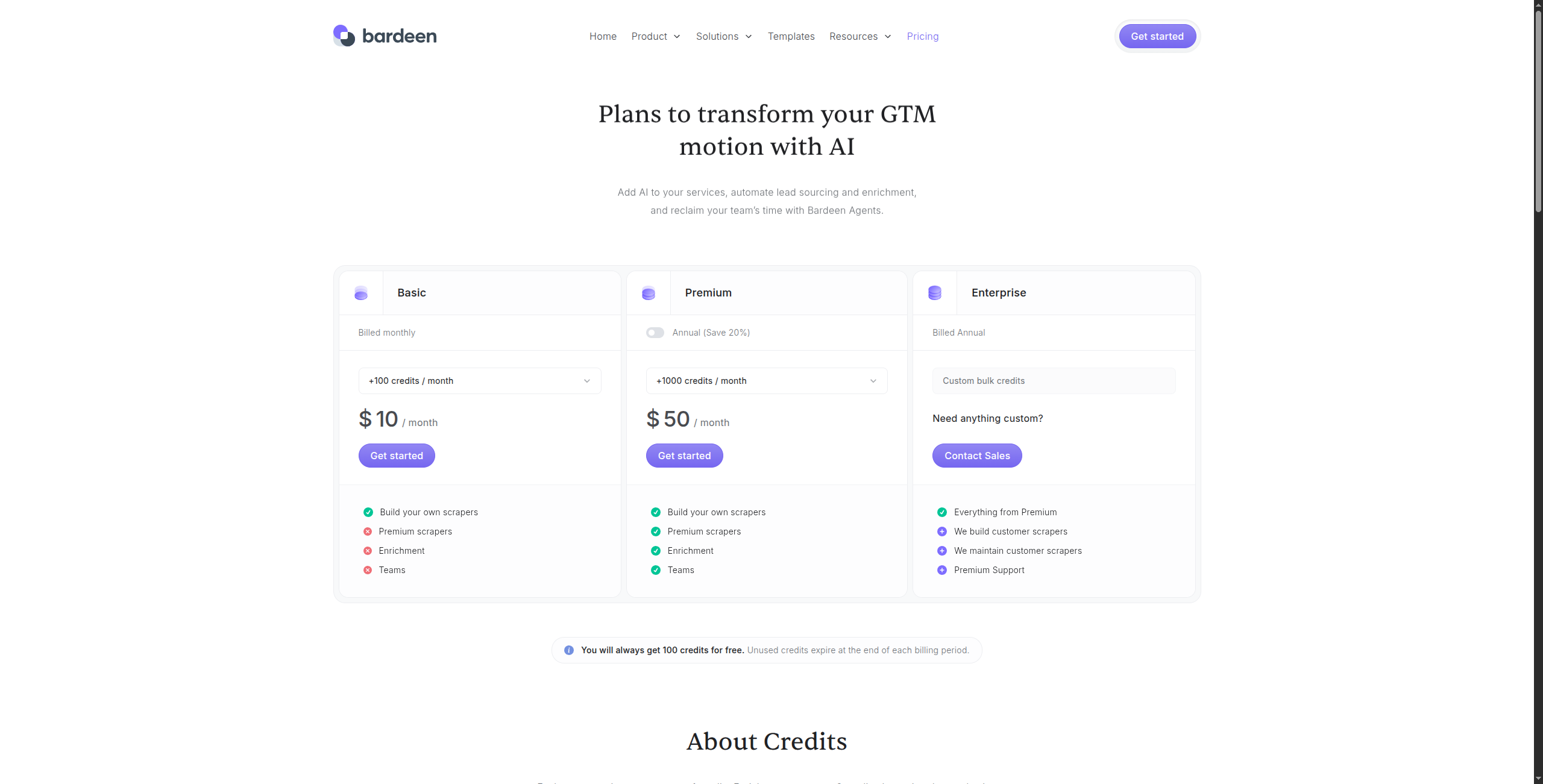
8. Bardeen — najlepszy do automatyzacji zadań przeglądarki
Bardeen to rozszerzenie Chrome, które nagrywała i odtwarza działania przeglądarki, wyodrębnia dane ze stron, które przeglądasz, i integruje wyodrębnione dane z ponad 100 aplikacjami. Najlepiej sprawdza się dla semi-zautomatyzowanej, ekstrakcji na żądanie, a nie w pełni nienadzorowanego scrapingu.
Ceny:
Bezpłatny — Nieograniczone ręczne przebiegi, podstawowe integracje, wsparcie społeczności
Professional — $10/miesiąc. Nieograniczone zautomatyzowane przebiegi, magazynowanie w chmurze, premium integracje (HubSpot, Salesforce, Pipedrive), wsparcie priorytetowe
Business — $15/użytkownik/miesiąc. Udostępnianie automatyzacji zespołu, foldery udostępniane, kontrola administracyjna
Enterprise — Skontaktuj się z działem sprzedaży, aby uzyskać SSO, zaawansowane bezpieczeństwo i niestandardowe integracje
Kluczowe funkcje:
AI Magic Actions — opisz w zwykłym angielskim, co wyodrębnić, bez selektorów CSS
Nagrywanie i odtwarzanie działań przeglądarki jako powtarzalne automatyzacje
Integruje się z ponad 100 aplikacjami: Notion, Airtable, HubSpot, Salesforce, Google Sheets
Scrapuje tabele, listy i dane strukturalne z dowolnej widocznej strony
Działa w przeglądarce Chrome — działa na dowolnej stronie, do której użytkownik ma dostęp
Obsługuje automatyzację wyzwalacza (oparte na czasie, webhook lub ręczne)
Zalety: Brak kodu rozszerzenie Chrome — zerowa konfiguracja; działania AI Magic do wyodrębniania danych według opisu, a nie selektory CSS; silne integracje z Notion, Airtable, HubSpot, Salesforce; dobry dla przepływów pracy produktywności osobistej i badań
Wady: Wymaga otwartej przeglądarki Chrome — nie w pełni nienadzorowana automatyzacja; nie nadaje się do scrapingu wysokiej objętości po stronie serwera; ograniczone do tego, do czego zalogowany użytkownik ma dostęp w przeglądarce
Najlepsze dla: Poszczególnych współpracowników i małych zespołów, którzy potrzebują zautomatyzować powtarzające się zadania badań przeglądarki i zbierania danych bez pisania kodu.
Którą alternatywę Apify wybrać?
Ekstrakcja zintegrowana z AI dla przepływów pracy biznesowych → FlowHunt
Monitorowanie stron bez kodu i ekstrakcja → Browse AI
Zamienianie stron internetowych na bazy wiedzy AI → Firecrawl
Wizualny scraping złożonych stron → Octoparse
API dla deweloperów do proxy i renderowania JavaScript → ScraperAPI
Scraping na skalę przedsiębiorstwa z unikaniem bot-ochrony → Bright Data
Ekstrakcja danych LinkedIn i mediów społecznych → PhantomBuster
Zadania ekstrakcji przeglądarki na żądanie → Bardeen
Dla większości przypadków użycia biznesowego — monitorowania konkurencji, wyodrębniania danych potencjalnych klientów, badania perspektyw — podejście natywne dla AI FlowHunt pokonuje model zorientowany na deweloperów Apify zarówno w szybkości konfiguracji, jak i integracji przepływu pracy. W przypadku dużych technicznych projektów scrapingu, ScraperAPI i Bright Data to właściwe narzędzia.
Najczęściej zadawane pytania
Apify to platforma web scrapingu i automatyzacji, która pozwala deweloperom budować, wdrażać i uruchamiać web scrapery — zwane 'Actors' — w chmurze. Obsługuje renderowanie JavaScript, rotację proxy i planowanie. Użytkownicy mogą budować niestandardowe scrapery lub używać wstępnie zbudowanych Actors z Apify Store do popularnych stron, takich jak Amazon, LinkedIn, Google Maps i media społecznościowe.
Tak — Browse AI ma darmowy plan (50 przebiegów/miesiąc), Bardeen jest bezpłatny dla podstawowych automatyzacji, Firecrawl ma bezpłatną warstwę API, a bezpłatna warstwa FlowHunt obejmuje możliwości przeglądania sieci. Dla deweloperów biblioteki open-source, takie jak Playwright, Puppeteer i Scrapy, są bezpłatne, ale wymagają samodzielnego zarządzania.
Browse AI jest najprostsza — dosłownie pokazujesz jej, co scrapować, klikając na stronę internetową, a ona automatycznie buduje scraper. Octoparse jest podobnie point-and-click. Bardeen jest najlepszy dla jednorazowych zadań ekstrakcji danych, gdzie chcesz zautomatyzować powtarzające się działania przeglądarki bez żadnych technicznych przygotowań.
Firecrawl jest stworzona specjalnie dla aplikacji AI — konwertuje całe strony internetowe na czysty, ustrukturyzowany markdown, który LLM mogą bezpośrednio konsumować. FlowHunt integruje ekstrakcję internetową w przepływy pracy agentów AI, co czyni go najlepszym wyborem, gdy wyodrębnione dane muszą trafiać do kroków rozumowania, podsumowania lub podejmowania decyzji.
W przypadku potrzeb danych internetowych na skalę przedsiębiorstwa (miliony stron, złożone unikanie bot-ochrony), Bright Data jest najsilniejszą alternatywą — obsługuje jedną z największych sieci proxy na świecie i ma infrastrukturę scrapingu na poziomie przedsiębiorstwa. ScraperAPI to bardziej przystępna opcja dla scrapingu na średnią skalę z renderowaniem JavaScript i obsługą CAPTCHA.
Arshia jest Inżynierką Przepływów Pracy AI w FlowHunt. Z wykształceniem informatycznym i pasją do sztucznej inteligencji, specjalizuje się w tworzeniu wydajnych przepływów pracy, które integrują narzędzia AI z codziennymi zadaniami, zwiększając produktywność i kreatywność.
Arshia Kahani
Inżynierka Przepływów Pracy AI
Scrapuj dowolną stronę internetową za pomocą AI — spróbuj FlowHunt za darmo
Agenci AI FlowHunt przeglądają sieć, wyodrębniają dane strukturalne i automatycznie wprowadzają je do twoich przepływów pracy — bez konieczności pisania skryptów scrapingowych.
Najlepsze alternatywy dla Browse AI w 2026 roku: 8 porównanych narzędzi do web scrapingu
Szukasz alternatyw dla Browse AI? Porównaliśmy 8 narzędzi do web scrapingu i ekstrakcji danych — od zasilanego sztuczną inteligencją scrapera do pełnych platfor...
Zintegruj FlowHunt z serwerem Apify Actors MCP, aby automatyzować i orkiestracyjnie zarządzać wielkoskalowym web scrapingiem, ekstrakcją danych oraz zarządzanie...
10 Najlepszych Web Scraperów AI w 2026: Ranking i Recenzje
10 najlepszych web scraperów AI w 2026, ocenionych pod kątem dokładności ekstrakcji, łatwości użycia, obsługi anty-botów i cen. Znajdź idealne narzędzie scrapin...
10 min czytania
Web Scraping
AI Tools
+2
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.