Acteurs Apify MCP
Intégrez FlowHunt avec le serveur MCP Actors d'Apify pour automatiser et orchestrer le scraping web à grande échelle, l’extraction de données et la gestion des ...
4 min de lecture
AI
Apify
+5

Apify est puissant mais complexe et coûteux pour la plupart des cas d’utilisation. Nous avons comparé 8 alternatives à Apify pour le web scraping et l’extraction de données — des outils sans code aux API pour développeurs.
Apify est l’une des plateformes de web scraping et d’automatisation les plus puissantes disponibles — mais elle est construite pour les développeurs, nécessite d’apprendre son système Actor, et les coûts augmentent rapidement pour le scraping de haut volume. Si vous cherchez quelque chose de plus simple, moins cher ou mieux adapté aux workflows IA, il existe de bonnes alternatives.
Apify est une plateforme cloud de web scraping et d’automatisation de navigateur. Son unité de base est l’“Actor” — un script de scraping ou d’automatisation réutilisable et partageable qui s’exécute dans l’infrastructure cloud d’Apify. Les utilisateurs peuvent créer des Actors personnalisés en Node.js en utilisant l’Apify SDK, ou utiliser des Actors pré-construits de l’Apify Store pour les tâches de scraping courantes (données de produits Amazon, annonces Google Maps, profils LinkedIn, contenu des médias sociaux).
Apify gère les défis d’infrastructure du web scraping : rendu JavaScript avec navigateurs headless, rotation de proxies pour éviter les interdictions d’IP, gestion des CAPTCHA, programmation et stockage des résultats. Cela le rend considérablement plus puissant que l’exécution de scrapers localement.
Le compromis : Apify nécessite des compétences en développement pour créer des Actors personnalisés, sa tarification évolue avec le temps de calcul (ce qui peut devenir coûteux pour le scraping continu), et le paradigme Actor a une courbe d’apprentissage.
| Outil | Meilleur pour | Tier gratuit | Prix de départ | Sans code | Natif IA |
|---|---|---|---|---|---|
| FlowHunt | Extraction intégrée à l’IA | ✅ | Basé sur l’utilisation | ✅ | ✅ |
| Apify | Scrapers développeur personnalisés | ✅ | $49/mois | ❌ | Partiel |
| Browse AI | Scraping de site sans code | ✅ | $48/mois | ✅ | Partiel |
| Firecrawl | Préparation de données LLM/IA | ✅ | $16/mois | Partiel | ✅ |
| Octoparse | Scraping visuel pointer-cliquer | ✅ | $75/mois | ✅ | ❌ |
| ScraperAPI | Rendu JS basé sur API | ✅ | $49/mois | ❌ | ❌ |
| Bright Data | Extraction à l’échelle de l’entreprise | ❌ | Personnalisé | ❌ | Partiel |
| PhantomBuster | Extraction LinkedIn/réseaux sociaux | ✅ | $56/mois | ✅ | ❌ |
| Bardeen | Automatisation des tâches du navigateur | ✅ | $10/mois | ✅ | ✅ |
Commencez votre essai gratuit aujourd'hui et voyez les résultats en quelques jours.
FlowHunt aborde l’extraction de données web différemment qu’Apify : au lieu de construire des scrapers autonomes, vous construisez des agents IA qui parcourent le web dans le cadre de workflows automatisés plus larges. L’agent peut naviguer vers une URL, lire le contenu de la page, extraire des informations spécifiques et utiliser immédiatement ces données à l’étape suivante — les alimenter dans un CRM, générer un résumé ou déclencher une séquence de prospection.
Il s’agit d’un cas d’utilisation fondamentalement différent du scraping par lots de millions de pages — FlowHunt excelle à l’extraction intelligente et ciblée dans le cadre d’un processus métier.
Avantages clés par rapport à Apify :
Meilleurs cas d’utilisation :
Pas idéal pour : Scraping par lots de haut volume de milliers de pages à la fois (utilisez ScraperAPI ou Bright Data pour cela).
Tarification : Tier gratuit disponible. La tarification basée sur l’utilisation évolue avec les exécutions réelles du workflow.
Browse AI est l’alternative à Apify la plus facile pour les non-développeurs. Vous naviguez vers le site web que vous voulez scraper, montrez à Browse AI quelles données extraire en cliquant dessus, et il construit un “robot” qui répète l’extraction selon un calendrier.
Il gère les sites rendus dynamiquement avec JavaScript, la pagination et les pages protégées par connexion — sans aucun code.
Tarification :
Fonctionnalités clés :
Avantages : Vraiment sans code — configurer en quelques minutes avec interface pointer-cliquer ; gère bien les sites riches en JavaScript ; surveillance programmée et détection des changements intégrées ; robots pré-construits pour les sites courants Inconvénients : Flexibilité limitée pour la logique d’extraction personnalisée complexe ; évolue moins bien qu’Apify pour le scraping très haute volume ; la tarification par exécution peut être imprévisible pour les sites fréquemment modifiés Meilleur pour : Les utilisateurs non techniques qui ont besoin d’une extraction récurrente à partir de sites web spécifiques sans écrire de code ou gérer l’infrastructure.
Recevez gratuitement les derniers conseils, tendances et offres.
Firecrawl est spécialement conçue pour un cas d’utilisation spécifique : transformer des sites web entiers en markdown propre que les LLM peuvent lire. Elle crawle les sites web, rend JavaScript, gère la pagination et produit du texte structuré et propre — idéal pour construire des bases de connaissances RAG (Retrieval-Augmented Generation) ou alimenter le contenu web aux agents IA.
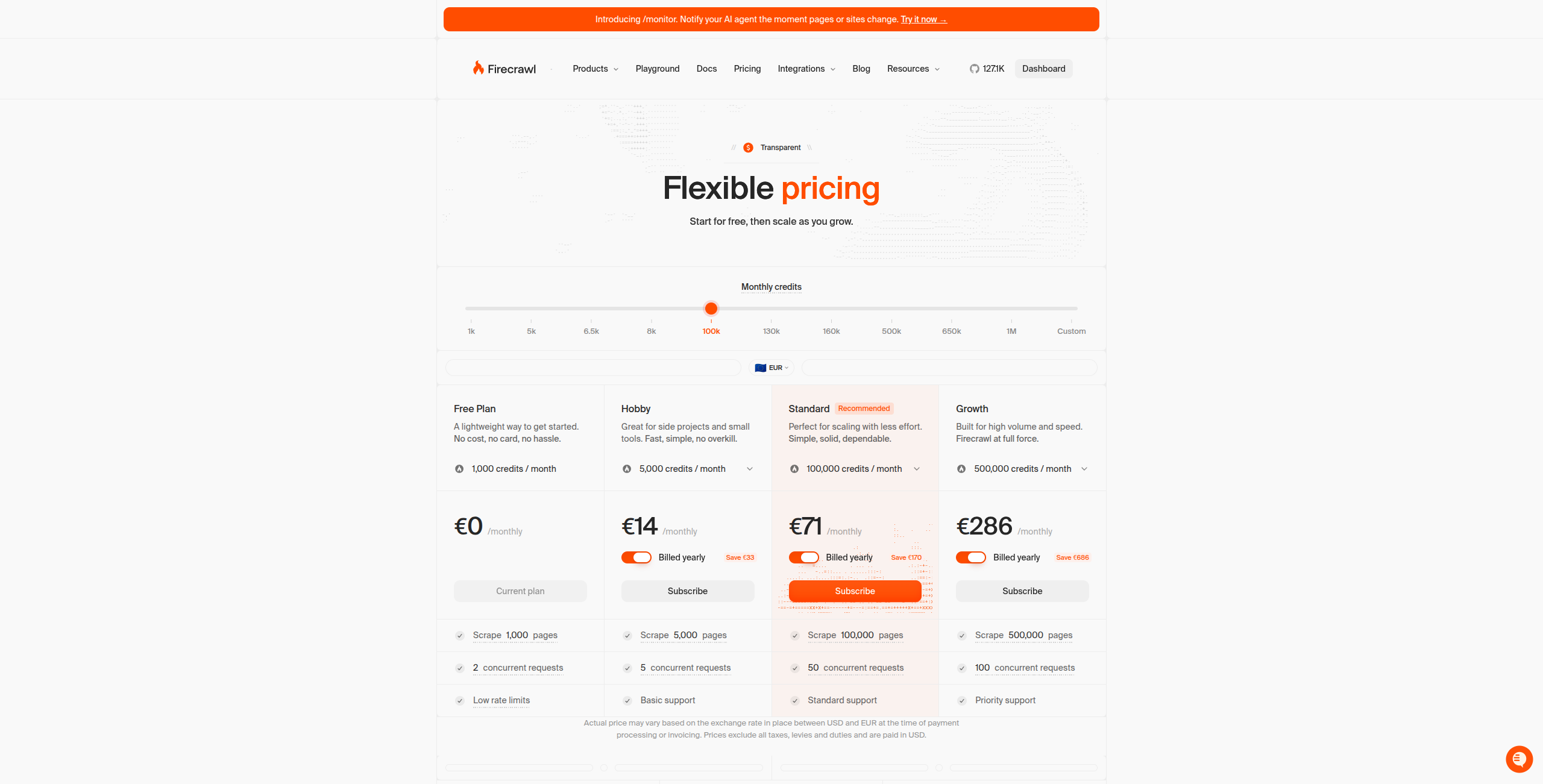
Tarification :
Fonctionnalités clés :
Avantages : Sortie markdown propre prête pour les LLM — aucun nettoyage HTML nécessaire ; crawling de site web complet avec support sitemap ; mappe et crawle les sites JavaScript dynamiques ; API simple — intégrer en quelques minutes Inconvénients : Ne convient pas à l’extraction de données structurées (prix, spécifications de produits) — produit du texte, pas des enregistrements structurés ; pas de générateur visuel — API pour développeurs uniquement ; non conçue pour les cas d’utilisation de surveillance programmée Meilleur pour : Les développeurs construisant des agents IA, des pipelines RAG ou des applications LLM qui ont besoin de contenu web propre et structuré comme entrée.
Octoparse fournit une application de bureau avec une interface pointer-cliquer pour construire des scrapers visuellement, puis les exécute dans le cloud selon un calendrier. Elle gère la plupart des scénarios de scraping courants — pagination, défilement infini, navigation par liste déroulante — sans code.
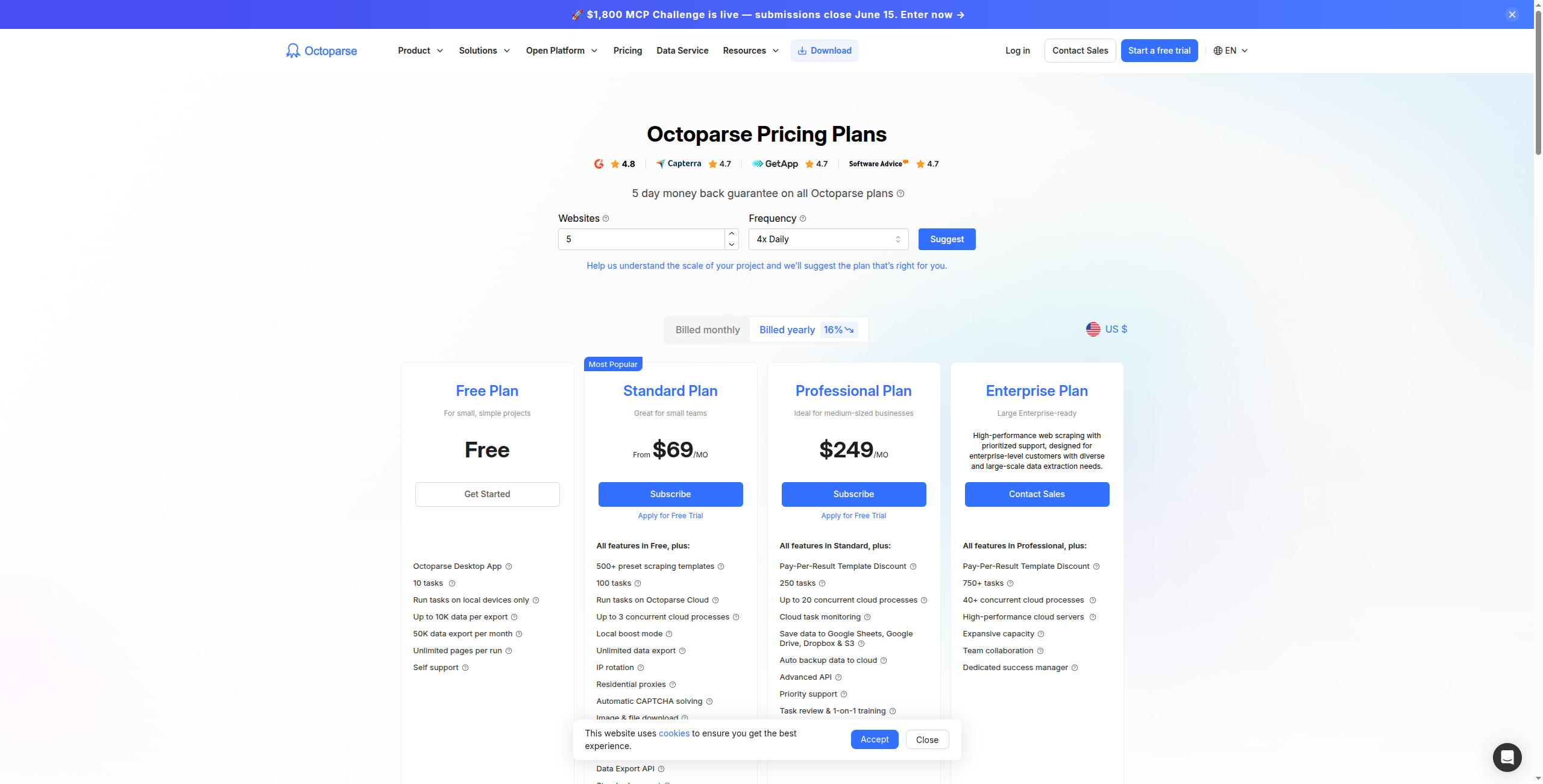
Tarification :
Fonctionnalités clés :
Avantages : Générateur de workflow visuel — aucun code nécessaire ; exécution cloud avec programmation et rotation d’IP ; gère la pagination complexe et les flux multi-pages ; export vers Excel, CSV, Google Sheets, bases de données Inconvénients : Plus cher que les alternatives pour les capacités équivalentes ; client de bureau (Windows/Mac) ajoute de la friction par rapport aux outils basés sur navigateur ; moins adapté à l’extraction en temps réel par rapport aux exécutions programmées par lots Meilleur pour : Les analystes non techniques et les équipes opérationnelles qui ont besoin d’une extraction de données programmée fiable à partir de sites web complexes ou paginés.
ScraperAPI est un service API qui gère les parties les plus difficiles du web scraping à grande échelle : rendu JavaScript, résolution des CAPTCHA et rotation automatique de proxies. Les développeurs envoient une URL à ScraperAPI et récupèrent du HTML propre — elle gère tout ce qui se passe entre les deux.
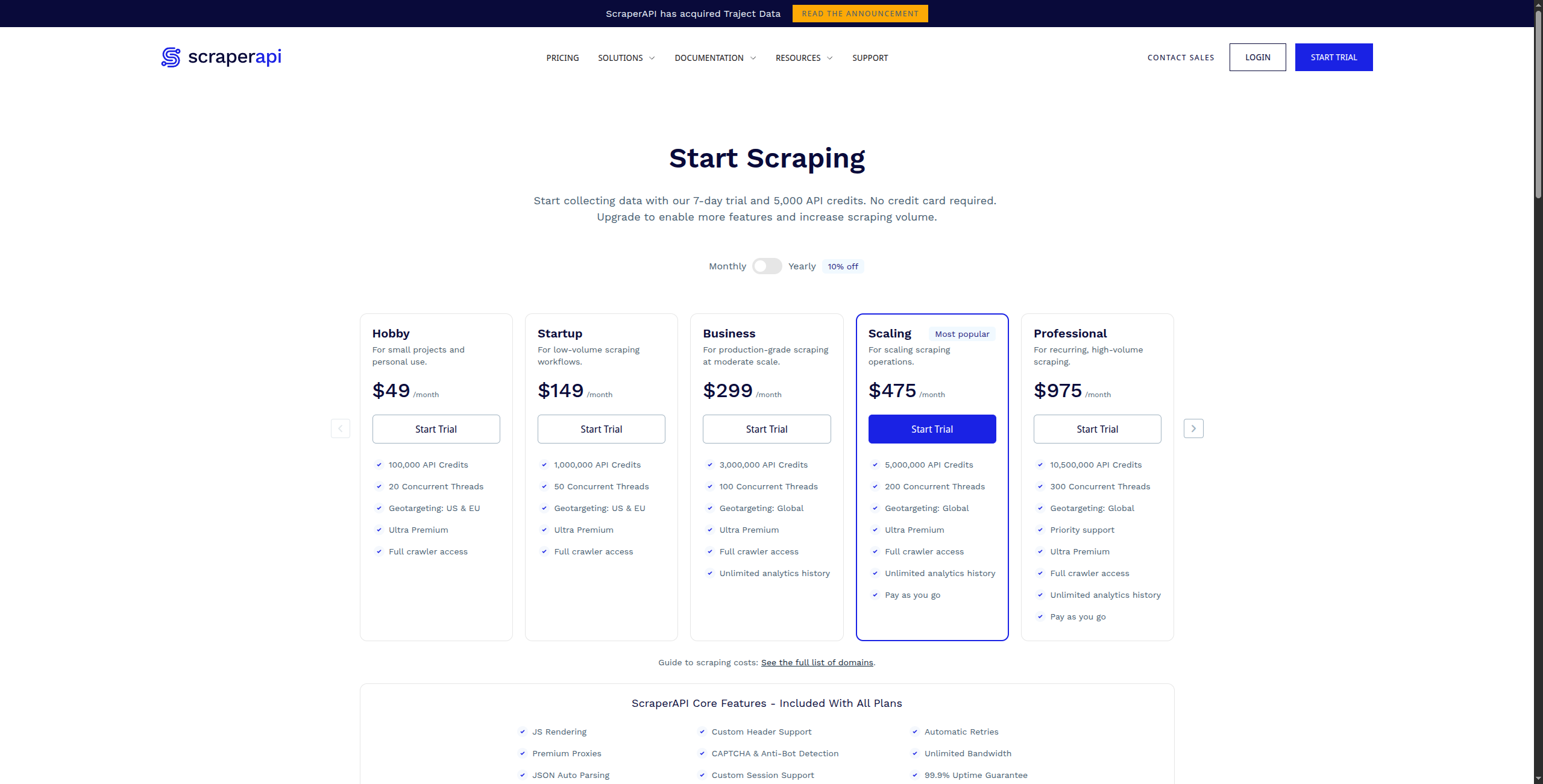
Tarification :
Fonctionnalités clés :
Avantages : Intégration API simple — un appel de fonction remplace l’infrastructure de scraping complexe ; gère les CAPTCHA, le géo-ciblage et l’émulation d’appareil ; points de terminaison de données structurées pour les sites courants (Amazon, Google, eBay) ; coût inférieur à Apify pour le scraping simple de haut volume Inconvénients : Retourne du HTML — vous devez toujours analyser et extraire les données vous-même ; pas d’interface sans code ou de générateur visuel ; pas de programmation ou de surveillance — juste une couche de rendu/proxy Meilleur pour : Les développeurs construisant des scrapers qui ont besoin d’une infrastructure de proxy et de rendu fiable et évolutive sans gérer leur propre pool de proxies.
Bright Data exploite l’un des plus grands réseaux de proxies au monde (72M+ IP) et fournit une suite complète de produits de données web : réseaux de proxies, API de scraping, automatisation de navigateur et ensembles de données pré-construits pour des centaines de sites web populaires. Pour les besoins de données web à l’échelle de l’entreprise, c’est sans égal.
Tarification :
Fonctionnalités clés :
Avantages : Plus grand réseau de proxies au monde — meilleur pour contourner la protection anti-bot avancée ; ensembles de données pré-construits pour les cas d’utilisation courants (Amazon, LinkedIn, médias sociaux) ; IDE Web Scraper pour construire les scrapers personnalisés ; garanties de conformité et de qualité des données d’entreprise Inconvénients : Tarification complexe — plusieurs produits avec différents modèles de coûts ; excessif pour les besoins de scraping petits ou moyens ; nécessite des ressources techniques pour implémenter correctement Meilleur pour : Les équipes d’entreprise avec des besoins de scraping de haut volume, des exigences de conformité strictes ou des besoins d’évasion anti-bot avancée.
PhantomBuster se spécialise dans l’extraction de données et l’automatisation des actions sur les plateformes sociales — LinkedIn, Twitter/X, Instagram, Facebook, Google Maps et plus. Ce n’est pas un scraper web général mais excelle dans sa niche.
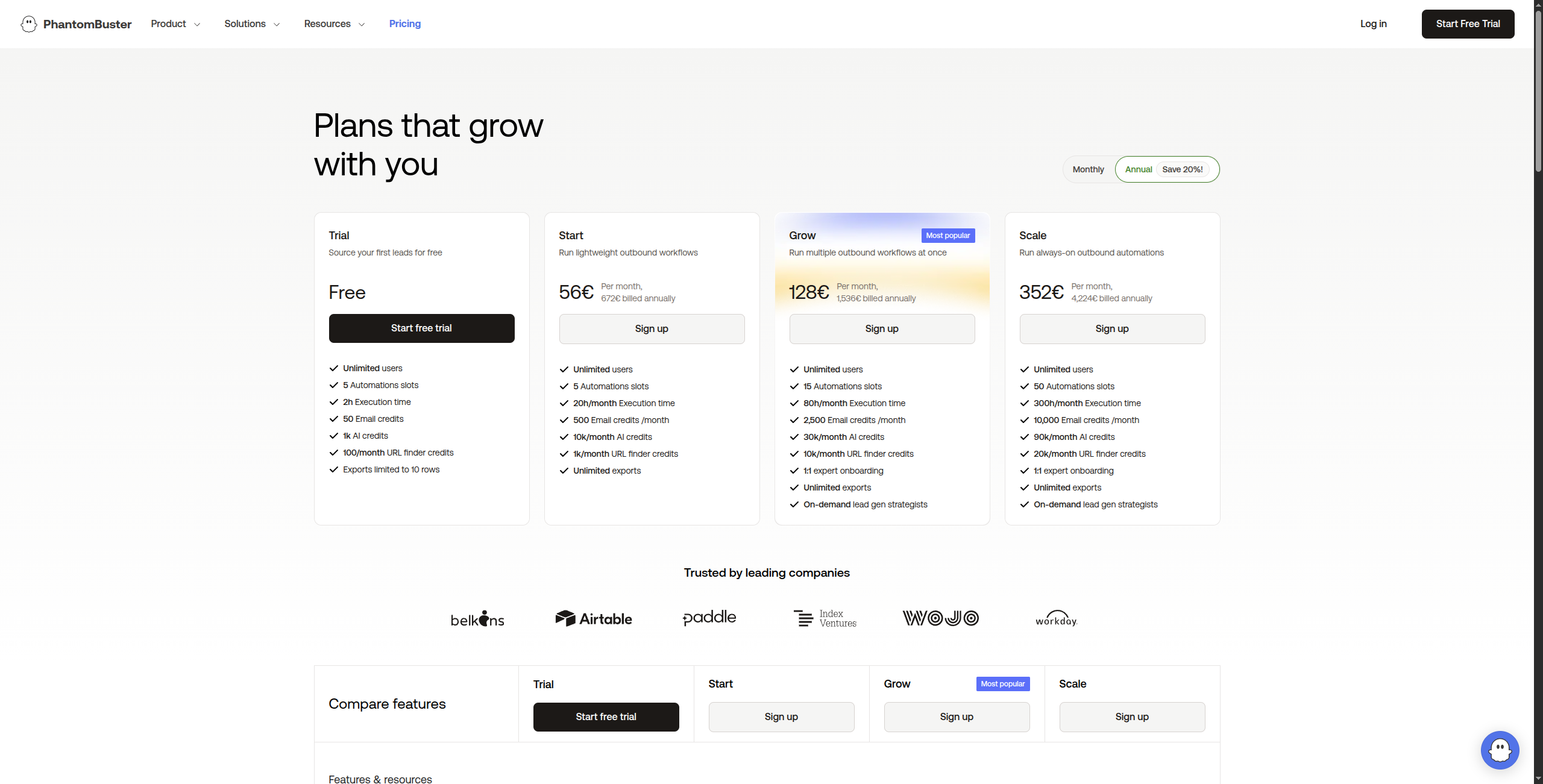
Tarification :
Fonctionnalités clés :
Avantages : Phantoms pré-construits pour les scénarios courants de scraping social ; extraction de prospects LinkedIn sans scripts de scraping ; automatisation (visites de profil, demandes de connexion) aux côtés de l’extraction de données ; interface sans code pour la plupart des cas d’utilisation Inconvénients : Spécifique à la plateforme — pas utile pour le scraping de site web arbitraire ; risque de conformité TOS LinkedIn avec l’automatisation ; limites de temps d’exécution plus faibles sur les plans inférieurs Meilleur pour : Les équipes commerciales et les growth marketers qui ont besoin d’extraire et d’agir sur les données LinkedIn et des médias sociaux pour la génération de prospects et la prospection.
Bardeen est une extension Chrome qui enregistre et rejoue les actions du navigateur, extrait les données des pages que vous consultez et intègre les données extraites avec plus de 100 applications. C’est mieux pour l’extraction semi-automatisée à la demande plutôt que le scraping entièrement sans surveillance.
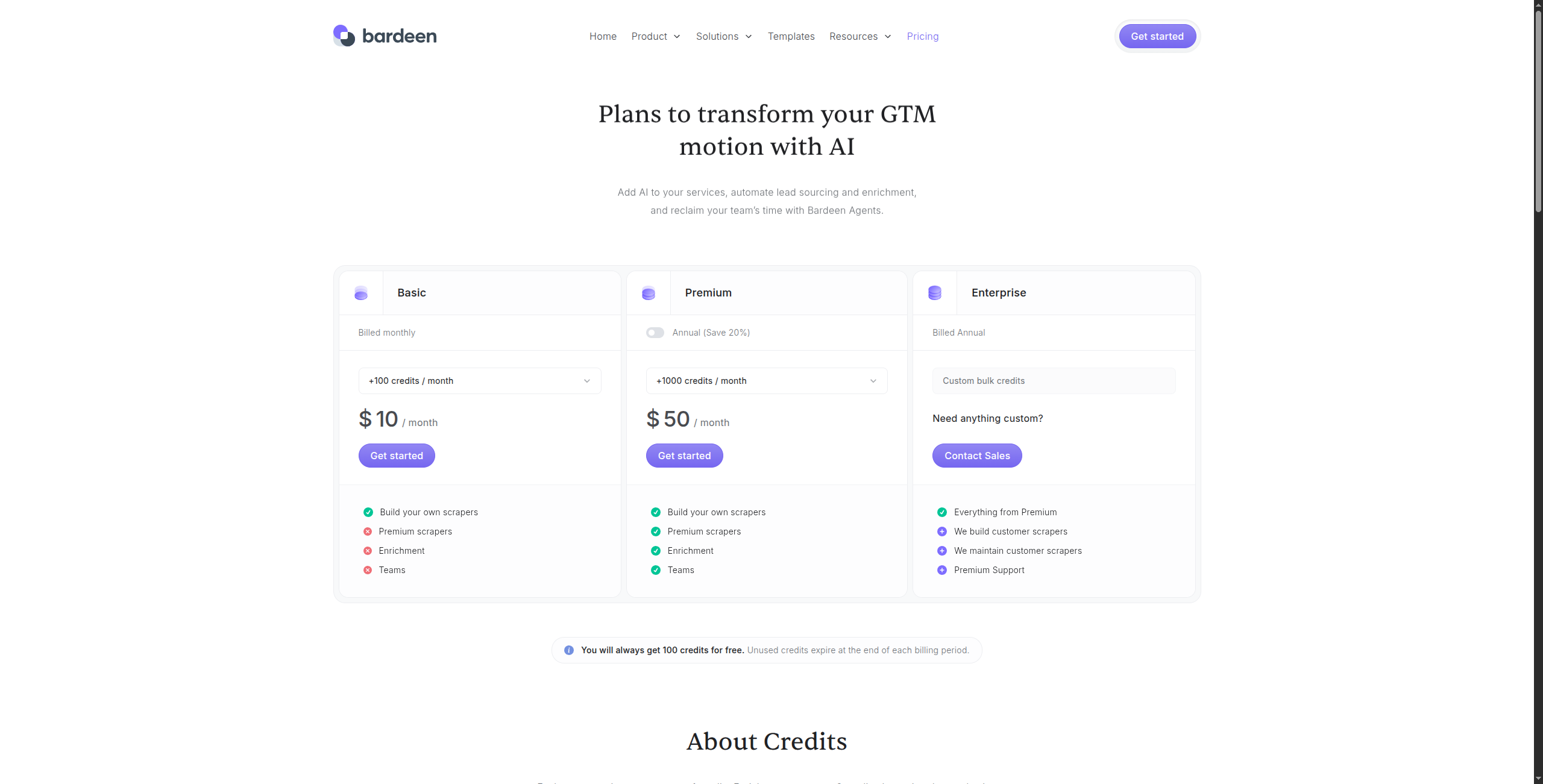
Tarification :
Fonctionnalités clés :
Avantages : Extension Chrome sans code — zéro configuration ; actions magiques IA pour extraire les données par description, pas par sélecteurs CSS ; intégrations fortes avec Notion, Airtable, HubSpot, Salesforce ; bon pour les workflows de productivité personnelle et de recherche Inconvénients : Nécessite que Chrome soit ouvert — pas d’automatisation entièrement sans surveillance ; ne convient pas au scraping côté serveur de haut volume ; limité à ce que l’utilisateur connecté peut accéder dans un navigateur Meilleur pour : Les contributeurs individuels et les petites équipes qui ont besoin d’automatiser les tâches répétitives de recherche et de collecte de données du navigateur sans écrire de code.
Pour la plupart des cas d’utilisation métier — surveiller les concurrents, extraire des données de prospects, rechercher des prospects — l’approche native à l’IA de FlowHunt surpasse le modèle axé sur les développeurs d’Apify en termes de vitesse de configuration et d’intégration de workflow. Pour les projets de scraping technique de haut volume, ScraperAPI et Bright Data sont les bons outils.
Arshia est ingénieure en workflows d'IA chez FlowHunt. Avec une formation en informatique et une passion pour l’IA, elle se spécialise dans la création de workflows efficaces intégrant des outils d'IA aux tâches quotidiennes, afin d’accroître la productivité et la créativité.

Les agents IA de FlowHunt parcourent le web, extraient des données structurées et les alimentent dans vos workflows automatiquement — aucun script de scraping requis.
Intégrez FlowHunt avec le serveur MCP Actors d'Apify pour automatiser et orchestrer le scraping web à grande échelle, l’extraction de données et la gestion des ...

Les 10 meilleurs web scrapers IA en 2026, classés par précision d'extraction, facilité d'utilisation, gestion anti-bot et tarification. Trouvez le bon outil de ...
Le serveur Apify MCP connecte les assistants IA à la plateforme Apify, permettant une automatisation transparente, l’extraction de données et l’orchestration de...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.