8 bedste Apify-alternativer i 2026 (Web Scraping & Dataudtræk)
Apify er kraftfuldt men komplekst og dyrt for de fleste use cases. Vi sammenlignede 8 Apify-alternativer til web scraping og dataudtræk — fra no-code værktøjer til developer APIs.
Apify er en af de mest kraftfulde web scraping og automatiseringsplatforme til rådighed — men den er bygget til udvikler, kræver læring af dens Actor-system, og omkostningerne øges hurtigt til storskalaret scraping. Hvis du leder efter noget enklere, billigere eller bedre egnet til AI-arbejdsflow, er der stærke alternativer.
Hvad er Apify?
Apify er en cloud-baseret web scraping og browser automatiseringsplatform. Dens kerneenhed er “Actor” — et genbrugelig, deleligt scraping eller automatiseringsskript, der køres i Apifys cloud-infrastruktur. Brugere kan bygge brugerdefinerede Actors i Node.js ved hjælp af Apify SDK, eller bruge pre-built Actors fra Apify Store til almindelige scraping opgaver (Amazon-produktdata, Google Maps-annoncer, LinkedIn-profiler, socialt medie-indhold).
Apify håndterer infrastruktur-udfordringerne ved web scraping: JavaScript rendering med headless browsere, proxy rotation for at undgå IP-forbud, CAPTCHA-håndtering, planlægning og resultatopbevaring. Dette gør det betydeligt mere kraftfuldt end at køre scrapers lokalt.
Kompromisset: Apify kræver udvikler-færdigheder til at bygge brugerdefinerede Actors, dens prisfastsættelse skaleres med computertid (som kan blive dyr til kontinuerlig scraping), og Actor-paradigmet har en læringskurve.
Hurtig sammenligning: Apify vs Alternativer
Værktøj
Bedst til
Gratis lag
Startpris
Ingen kode
AI-native
FlowHunt
AI-integreret udtræk
✅
Brugsbaseret
✅
✅
Apify
Brugerdefinerede udvikler scrapers
✅
$49/måned
❌
Delvis
Browse AI
Ingen-kode site scraping
✅
$48/måned
✅
Delvis
Firecrawl
LLM/AI dataforberedelse
✅
$16/måned
Delvis
✅
Octoparse
Visuelt point-and-click scraping
✅
$75/måned
✅
❌
ScraperAPI
API-baseret JS rendering
✅
$49/måned
❌
❌
Bright Data
Enterprise-scale udtræk
❌
Brugerdefineret
❌
Delvis
PhantomBuster
LinkedIn/social udtræk
✅
$56/måned
✅
❌
Bardeen
Browser opgave automatisering
✅
$10/måned
✅
✅
Klar til at vokse din virksomhed?
Start din gratis prøveperiode i dag og se resultater inden for få dage.
1. FlowHunt — Bedst til AI-integreret webdata-udtræk
FlowHunt tilgår web dataudtræk anderledes end Apify: i stedet for at bygge standalone scrapers, bygger du AI-agenter, der gennemser internettet som del af større automatiserede arbejdsflow. Agenten kan navigere til en URL, læse sideindholdet, udtræk specifik information og øjeblikkeligt bruge disse data i næste trin — føre dem ind i en CRM, generere en opsummering eller udløse en outreach-sekvens.
Dette er et fundamentalt anderledes use case end batch scraping af millioner af sider — FlowHunt udmærker sig ved intelligent, målrettet udtræk som del af en forretningsproces.
Vigtige fordele over Apify:
Ingen scraping-scripts — AI-agenter navigerer og udtræk baseret på naturligt sproginstruktioner
Integreret arbejdsflow — udtrykt data føres øjeblikkeligt ind i downstream automatiseringsstrin
Håndterer ustruktureret sider — AI forstår indhold semantisk, ikke blot ved CSS-valg
Indbyggede integrationer — send udtrykt data til CRM, Slack, sheets eller nogen af 1.400+ værktøjer
Ingen infrastruktur-styring — fuldt hosted og skaleret
Bedste use cases:
Overvågning af konkurrentpriser eller produktændringer
Integration af webdata i AI-opsummerings- eller analysepipelines
Ikke ideelt til:Høj-volumen batch scraping af tusinder af sider på engang (brug ScraperAPI eller Bright Data til det).
Prisfastsættelse: Gratis lag tilgængeligt. Brugsbaseret prisfastsættelse skaleres med faktiske arbejdsflowkørsel.
2. Browse AI — Bedst No-Code Web Scraping Alternativ
Browse AI er det nemmeste Apify-alternativ for ikke-udvikler. Du navigerer til hjemmesiden, du vil skrabe, viser Browse AI hvad data der skal udtræk ved at klikke på det, og den bygger en “robot”, der gentager uddrag på en tidsplan.
Den håndterer dynamisk JavaScript-rendererede sites, paginering og login-beskyttede sider — uden nogen kode.
Fordele: Virkelig ingen kode — opsætning på få minutter med point-and-click interface; håndterer JavaScript-tunge sites godt; planlagt overvågning og ændringer detektion indbygget; pre-built robots til almindelige sites
Ulemper: Begrænset fleksibilitet til kompleks brugerdefineret uddrag logik; skaleres mindre godt end Apify til meget høj-volumen scraping; prisfastsættelse pr. kørsel kan være uforudsigelig til hyppigt ændrede sites
Bedst til: Ikke-tekniske brugere, der har brug for tilbagevendende udtræk fra specifikke hjemmesider uden at skrive kode eller administrere infrastruktur.
Tilmeld dig vores nyhedsbrev
Få de seneste tips, trends og tilbud gratis.
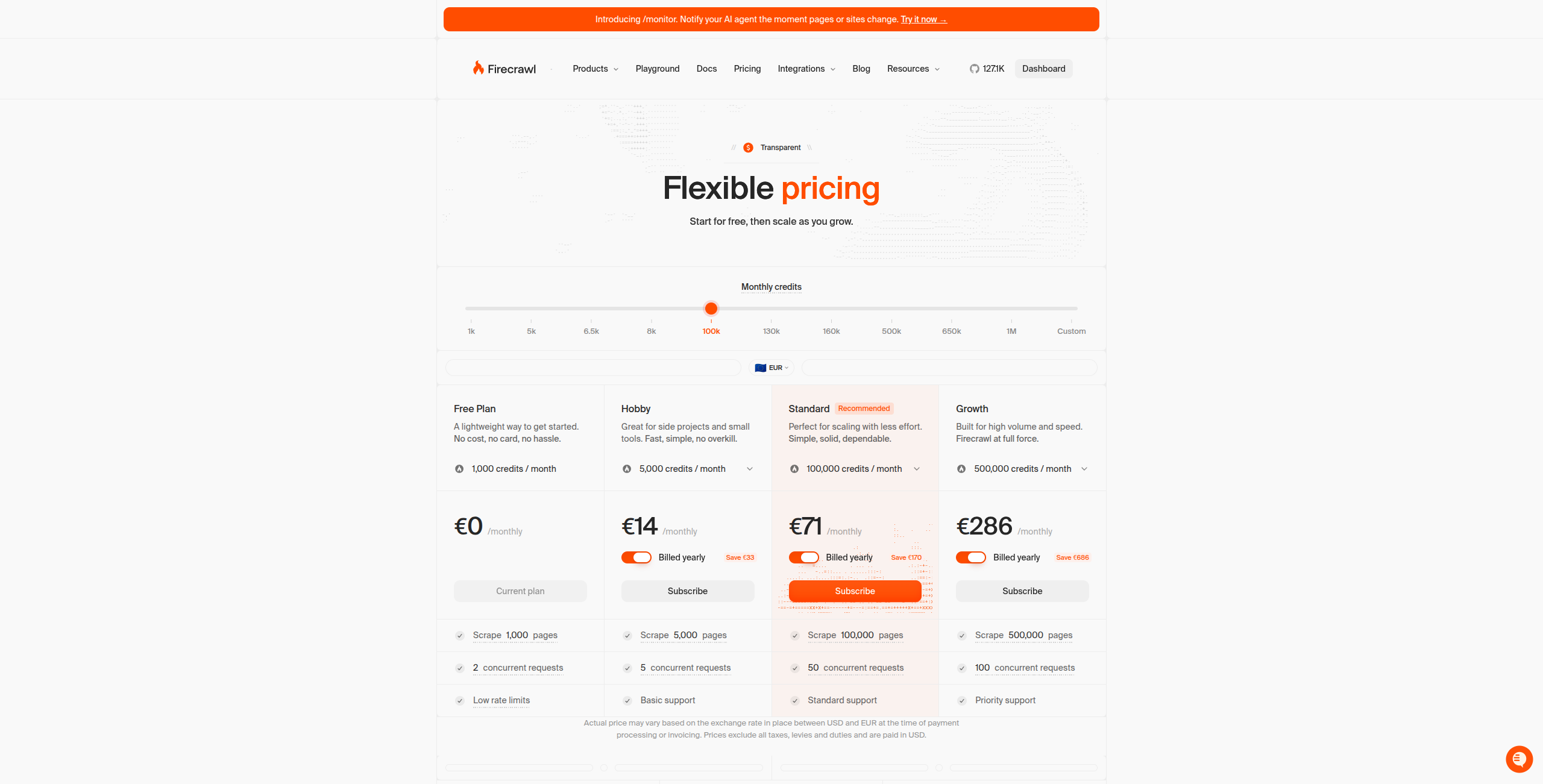
3. Firecrawl — Bedst til LLM og AI-applikationdata
Firecrawl er specialbygget til et specifikt use case: at omdanne hele hjemmesider til ren markdown, som LLM’er kan læse. Det crawler hjemmesider, renderer JavaScript, håndterer paginering og udsender struktureret, ren tekst — ideelt til at bygge RAG (Retrieval-Augmented Generation) vidensbasiser eller føre webindhold ind i AI-agenter.
Prisfastsættelse:
Gratis — 500 credits/måned, op til 500 skrabede sider
Hobby — $16/måned. 3.000 credits/måned, fuld API-adgang, grundlæggende support
Standard — $83/måned. 100.000 credits/måned, højere rate limits, prioritet support
Enterprise — Kontakt salg for brugerdefineret volumen, SLA’er og on-premise muligheder
Vigtige funktioner:
Konverterer hele hjemmesider til ren, LLM-optimiseret markdown output
Fuld hjemmeside crawling med sitemap og link-opdagelse
JavaScript rendering til dynamisk single-page applikationer
Udtræk endpoint til struktureret dataudtræk med skema
Søg endpoint til AI-drevet websøgning
Simpel REST API med SDK’er til Python, Node.js, Go og Rust
Fordele: Ren LLM-klar markdown output — ingen HTML oprydning påkrævet; fuld hjemmeside crawling med sitemap support; kortlægger og crawler dynamisk JavaScript sites; simpel API — integrer på få minutter
Ulemper: Ikke egnet til at udtræk strukturerede data (priser, produktspecifikationer) — udsender tekst, ikke strukturerede poster; ingen visuelt builder — kun developer API; ikke designet til planlagte overvågnings use cases
Bedst til: Udvikler, der bygger AI-agenter, RAG-pipelines eller LLM-applikationer, der har brug for ren, struktureret webindhold som input.
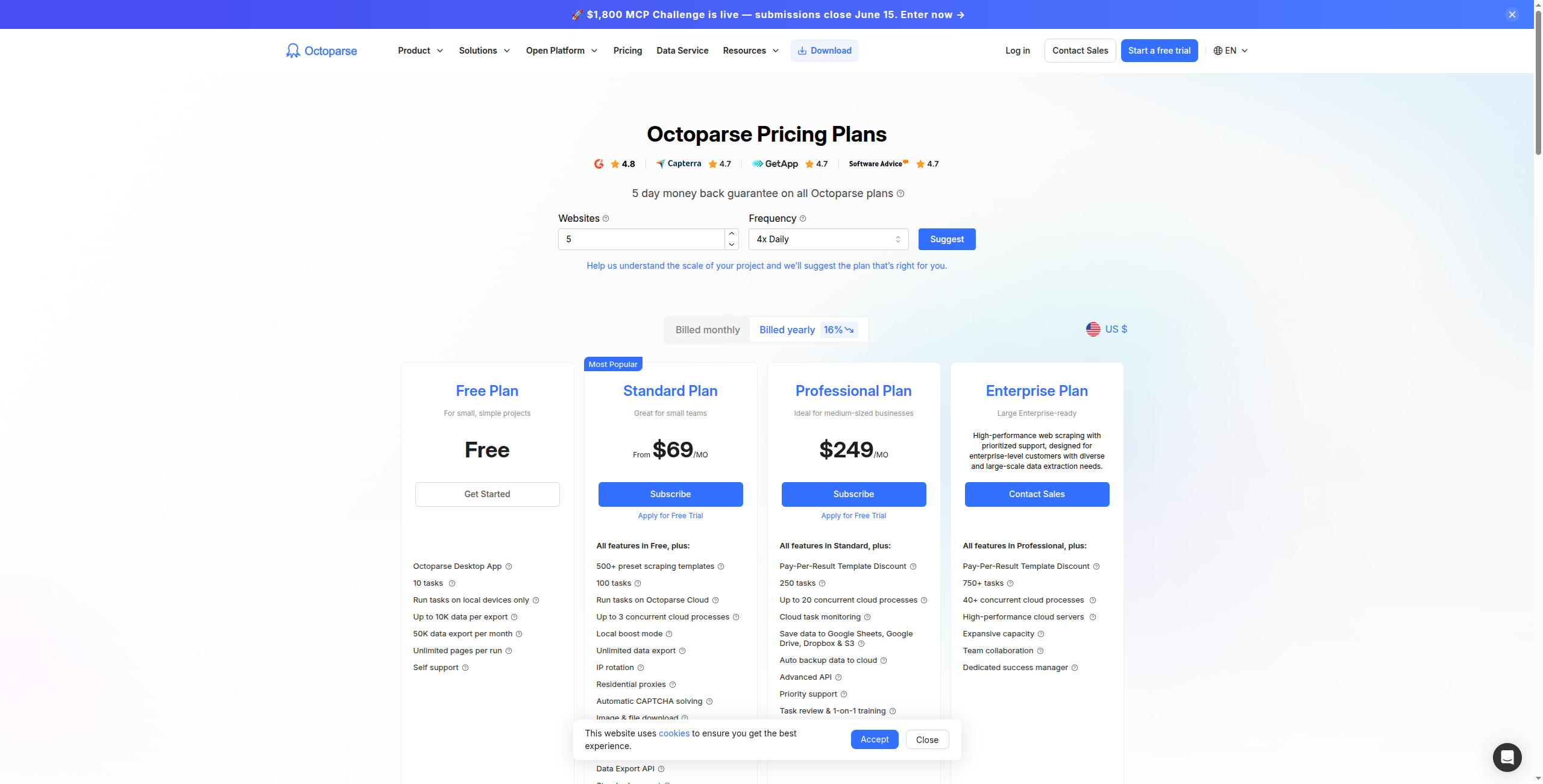
4. Octoparse — Bedst visuelt Scraper med Cloud Execution
Octoparse leverer en desktop applikation med et point-and-click interface til at bygge scrapers visuelt, derefter køre dem i cloudmiljøet på en tidsplan. Den håndterer de fleste almindelige scraping-scenarier — paginering, uendelig scroll, dropdown-navigation — uden kode.
Prisfastsættelse:
Gratis — Begrænset til 10.000 poster pr. eksport, lokal (ikke-cloud) scraping kun
Standard — $75/måned. Cloud scraping, 10 cloud opgaver, planlægning, API-adgang
Professional — $149/måned. 30 cloud opgaver, IP rotation, hurtigere cloud execution, prioritet support
Cloud execution med planlægning og automatisk IP rotation
Håndterer kompleks paginering, uendelig scroll og multi-side flows
Indbygget CAPTCHA-håndtering og anti-block mekanismer
Eksport til Excel, CSV, Google Sheets og databaser (MySQL, SQL Server)
1.000+ pre-built skabeloner til almindelige hjemmesider
Fordele: Visuelt arbejdsflowbygger — ingen kode påkrævet; cloud execution med planlægning og IP rotation; håndterer kompleks paginering og multi-side flows; eksport til Excel, CSV, Google Sheets, databaser
Ulemper: Dyrere end alternativer for tilsvarende kapaciteter; desktop klient (Windows/Mac) tilføjer friktion vs browser-baserede værktøjer; mindre egnet til realtids udtræk vs planlagte batch kørsel
Bedst til: Ikke-tekniske analytikere og driftsteam, der har brug for pålidelig planlagt dataudtræk fra kompleks eller paginerede hjemmesider.
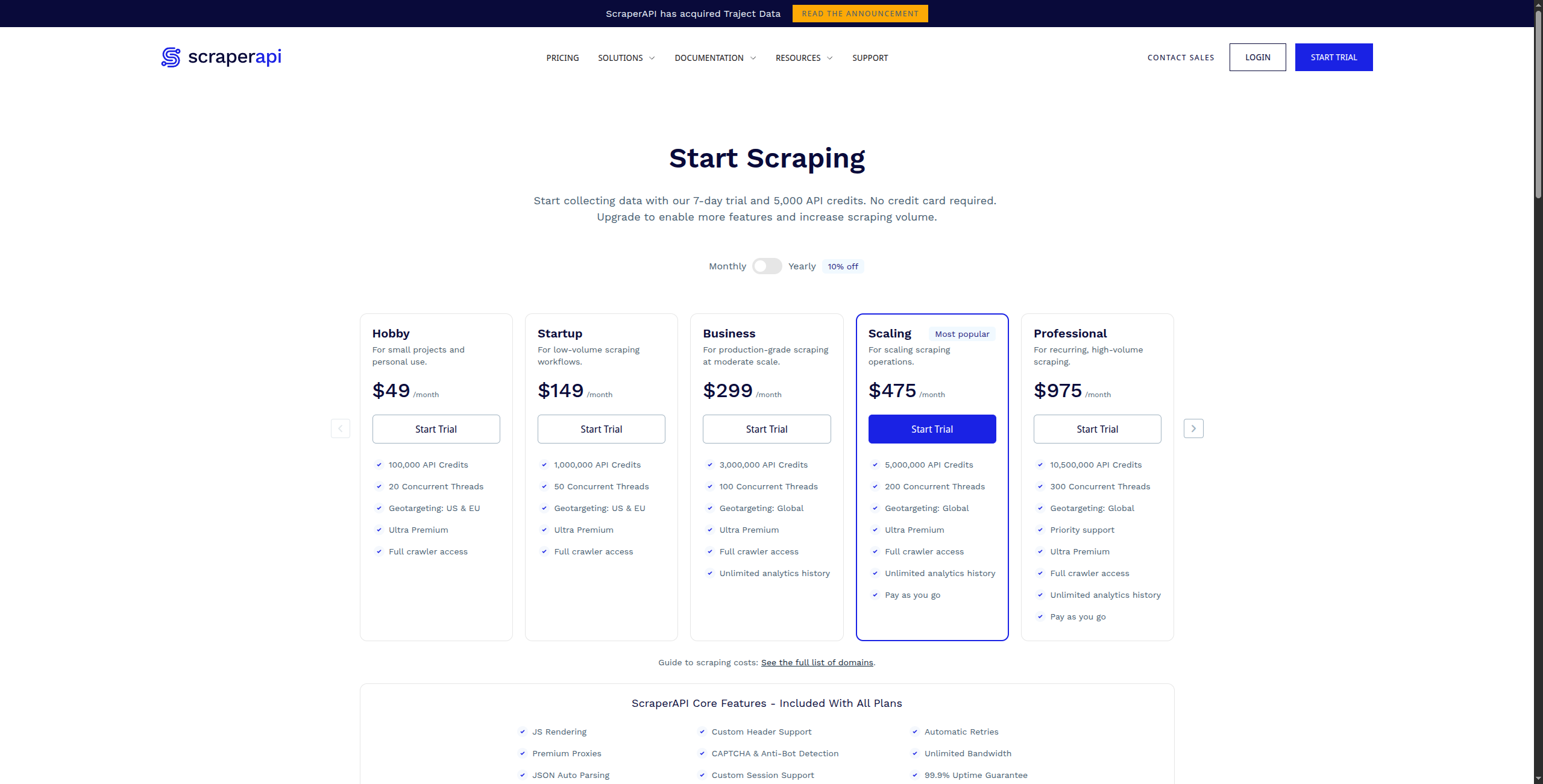
5. ScraperAPI — Bedst til Developer-Grade Proxy og Rendering
ScraperAPI er en API-service, der håndterer de sværeste dele af web scraping i stor skala: JavaScript rendering, CAPTCHA-løsning og automatisk proxy rotation. Udvikler sender en URL til ScraperAPI og får tilbage ren HTML — den håndterer alt derimellem.
Prisfastsættelse:
Gratis — 1.000 API-kald/måned, op til 5 samtidige anmodninger
Business — $299/måned. 3.000.000 API-kald, 50 samtidige anmodninger, dedikerede proxies
Enterprise — Kontakt salg for brugerdefineret volumen og dedikeret infrastruktur
Vigtige funktioner:
Enkelt API-kald returnerer rendereret HTML fra enhver URL
Automatisk proxy rotation med 40M+ residential og datacenter IP’er
JavaScript rendering via headless Chrome til SPA’er og dynamisk sites
CAPTCHA-løsning og anti-bot foranstaltnings bypass
Geo-targeting med land-specifikt proxy valg
Strukturerede datapunkter til Amazon, Google, Walmart og mere
Fordele: Simpel API integration — en funktionskald erstatter kompleks scraping-infrastruktur; håndterer CAPTCHA, geo-targeting og device emulering; strukturerede datapunkter til almindelige sites (Amazon, Google, eBay); lavere omkostning end Apify til høj-volumen simpel scraping
Ulemper: Returnerer HTML — du skal stadig parse og udtræk data selv; ingen visuelt builder eller ingen-kode interface; ingen planlægning eller overvågning — bare et rendering/proxy lag
Bedst til: Udvikler, der bygger scrapers og har brug for pålidelig, skalerbar proxy og rendering-infrastruktur uden at administrere deres eget proxy-pool.
6. Bright Data — Bedst Enterprise Web Data Platform
Bright Data driver et af verdens største proxy-netværk (72M+ IP’er) og leverer en fuld suite af web data-produkter: proxy-netværk, scraping APIs, browser-automatisering og pre-built datasets til hundredvis af populære hjemmesider. For enterprise-scale web data-behov er det uovertruffen.
Prisfastsættelse:
Pay-as-you-go — Tilgængeligt på tværs af alle produkter; datacenter proxies fra $0,6/GB, residential proxies fra $8,4/GB, ISP proxies fra $15/GB
Månedlige planer — Starter fra ~$500/måned til datacenter proxy planer; rabatter til højere committed volumen
Scraping Browser — Fra $0,1/GB båndbredde forbrugt
Web Scraper API — Fra $1,50/1.000 anmodninger til strukturerede datapunkter
Datasets — Pre-built datasets til Amazon, LinkedIn, Instagram fra $0,001/post; brugerdefineret dataset levering kontakt salg
Enterprise — Kontakt salg for dedikeret infrastruktur, compliance garantier og SLA
Vigtige funktioner:
72M+ IP proxy-netværk — residential, datacenter, ISP og mobile proxies
Scraping Browser API til fuld browser-automatisering i stor skala
Web Scraper IDE til at bygge og administrere brugerdefinerede scrapers
Pre-built strukturerede datasets til 100+ populære hjemmesider
Compliance-grade datainsamling med juridisk gennemgangsprocesser
Enterprise SLA med 99,9% uptime garanti
Fordele: Største proxy-netværk i verden — bedst til at omgå avanceret anti-bot beskyttelse; pre-built datasets til almindelige use cases (Amazon, LinkedIn, sociale medier); Web Scraper IDE til at bygge brugerdefinerede scrapers; enterprise compliance og datakvalitets garantier
Ulemper: Kompleks prisfastsættelse — flere produkter med forskellige omkostningsmodeller; overkill til små eller mid-scale scraping behov; kræver tekniske ressourcer til at implementere godt
Bedst til: Enterprise teams med høj-volumen scraping behov, strenge compliance krav eller avanceret anti-bot undvigelse krav.
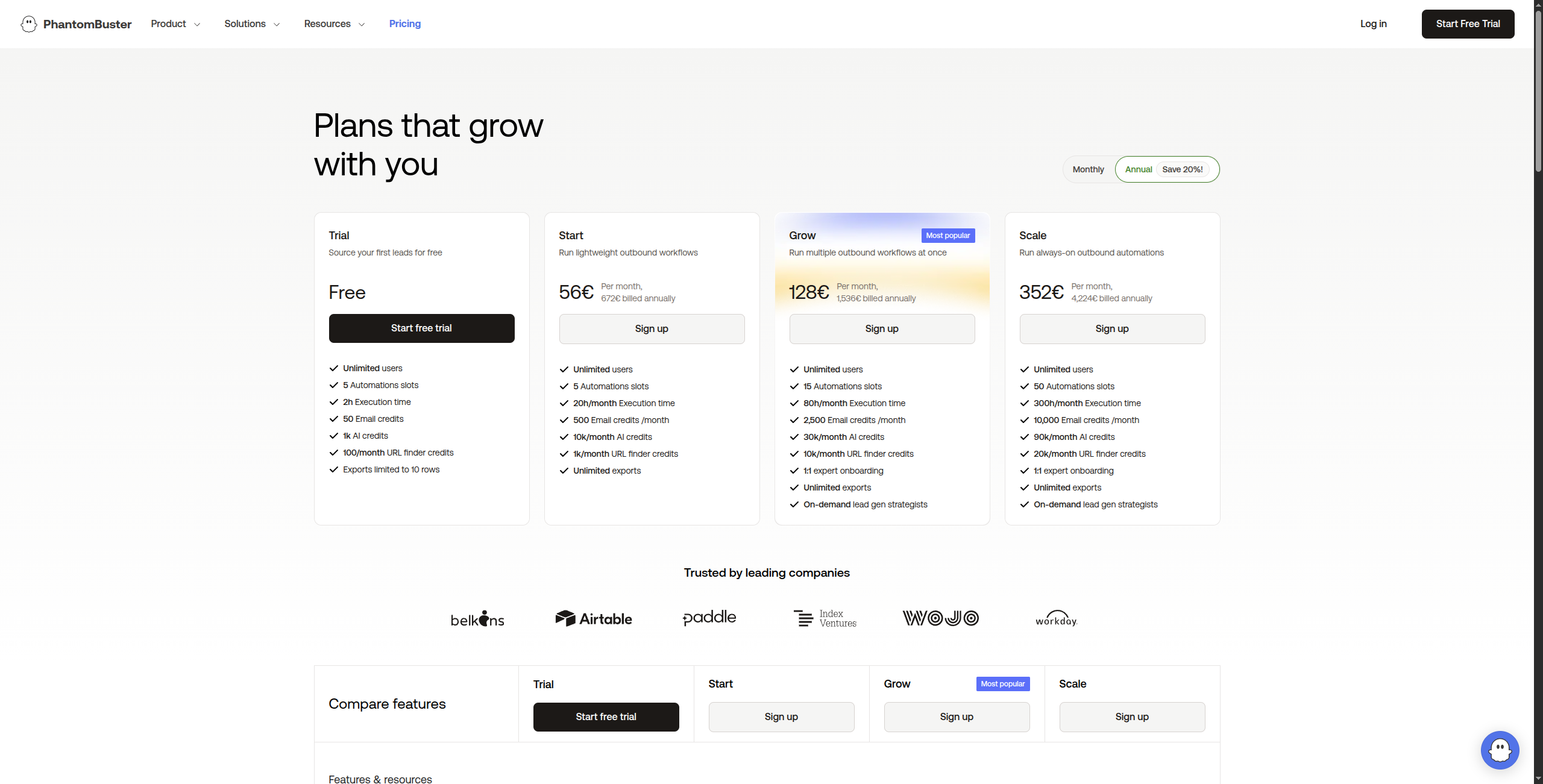
7. PhantomBuster — Bedst til Social Media Data Udtræk
PhantomBuster specialiserer sig i at udtræk data og automatisere handlinger på sociale platforme — LinkedIn, Twitter/X, Instagram, Facebook, Google Maps og mere. Det er ikke en generel web scraper, men udmærker sig i sin niche.
Prisfastsættelse:
Gratis prøveperiode — 14 dage, fuld adgang til alle Phantoms
Pro — $128/måned. 80 timer execution tid/måned, 15 Phantoms samtidigt, prioritet support
Team — $352/måned. 300 timer execution tid/måned, ubegrænsede samtidige Phantoms, dedikeret support
Enterprise — Kontakt salg for brugerdefineret execution tid og volumen
Vigtige funktioner:
100+ pre-built “Phantoms” til LinkedIn, Twitter, Instagram, Facebook og Google Maps
LinkedIn scraping: profil data, virksomhedsside, Sales Navigator søgeresultater, post engagement
Automatiseret outreach sekvenser med forbindelsesanmodninger og beskeder
Eksport til CSV, Google Sheets, CRM webhooks
Planlagte kørsel med konfigurerbar throttling for at reducere kontorisiko
Multi-account styring til agency brug
Fordele: Pre-built phantoms til almindelige social scraping scenarier; LinkedIn lead udtræk uden scraping-scripts; automatisering (profilbesøg, forbindelsesanmodninger) sammen med dataudtræk; ingen-kode interface til de fleste use cases
Ulemper: Platform-specifik — ikke nyttig til vilkårlig hjemmeside scraping; LinkedIn TOS compliance risiko med automatisering; lavere execution tid-grænser på lavere planer
Bedst til: Salgsteam og growth marketers, der har brug for at udtræk og handle på LinkedIn og sociale media-data til lead generation og outreach.
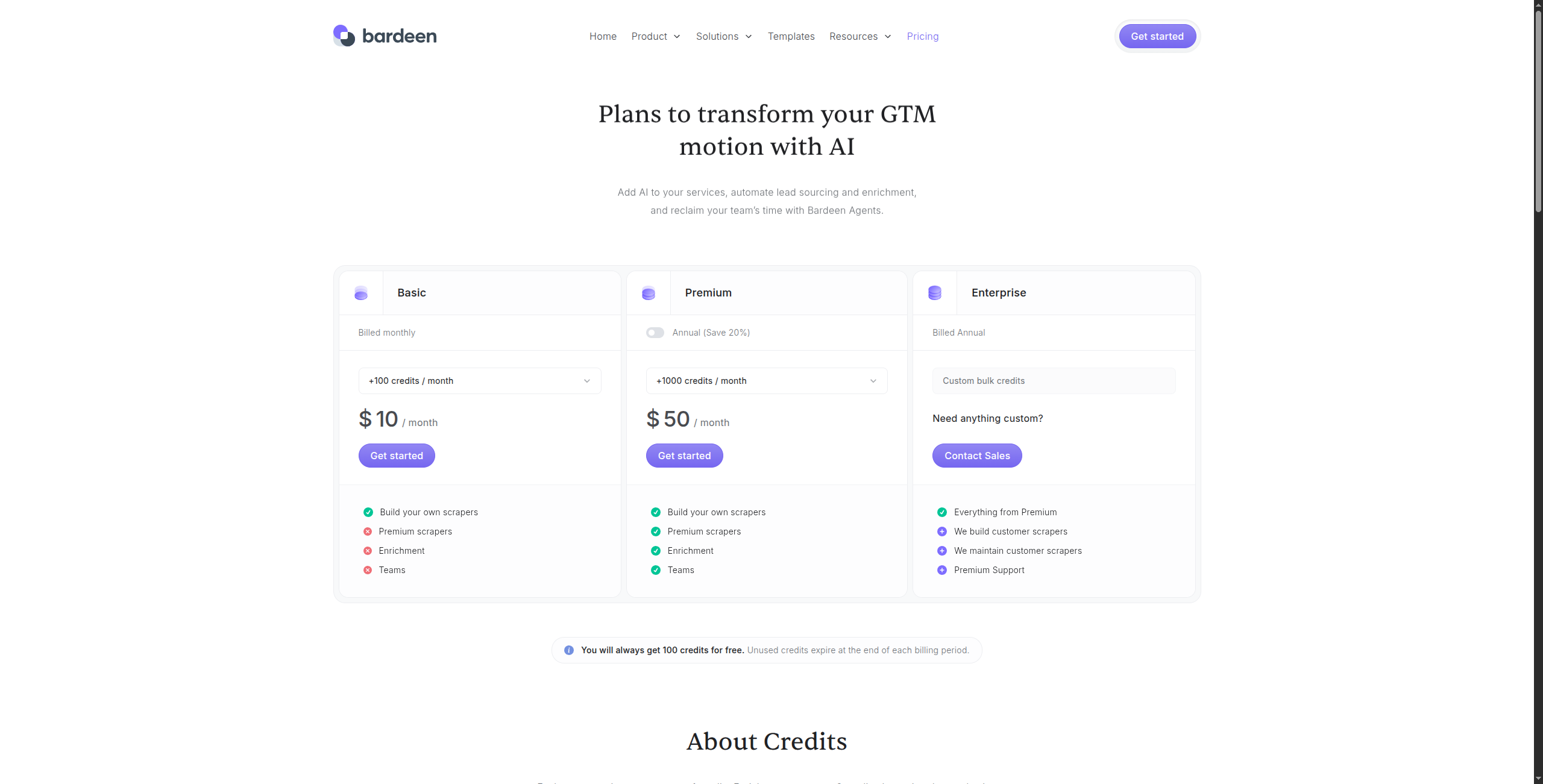
8. Bardeen — Bedst til Browser Task Automatisering
Bardeen er en Chrome-udvidelse, der optager og gengiver browserhandlinger, udtræk data fra sider, du ser, og integrerer uddrag data med 100+ apps. Det er bedst til semi-automatiseret, on-demand udtræk snarere end fuldt uovervåget scraping.
Prisfastsættelse:
Gratis — Ubegrænsede manuel kørsel, grundlæggende integrationer, community support
Professional — $10/måned. Ubegrænsede automatiserede kørsel, cloud opbevaring, premium integrationer (HubSpot, Salesforce, Pipedrive), prioritet support
Business — $15/bruger/måned. Teamdeling af automationer, delte mapper, admin kontroller
Enterprise — Kontakt salg for SSO, avanceret sikkerhed og brugerdefinerede integrationer
Vigtige funktioner:
AI Magic Actions — beskriv i klart engelsk hvad der skal udtræk, ingen CSS-valg påkrævet
Optager og gengiver browserhandlinger som gentagelige automationer
Integreres med 100+ apps: Notion, Airtable, HubSpot, Salesforce, Google Sheets
Skraber tabeller, lister og strukturerede data fra enhver synlig side
Køres i Chrome browser — virker på enhver site, brugeren kan få adgang til
Understøtter trigger-baseret automatisering (tidsbaseret, webhook eller manuel)
Fordele: Ingen-kode Chrome-udvidelse — nul opsætning; AI magic actions til at udtræk data efter beskrivelse, ikke CSS-valg; stærk integrationer med Notion, Airtable, HubSpot, Salesforce; godt til personlig produktivitet og forskning arbejdsflow
Ulemper: Kræver Chrome åbent — ikke fuldt uovervåget automatisering; ikke egnet til server-side høj-volumen scraping; begrænset til hvad den loggede-in bruger kan få adgang til i en browser
Bedst til: Individuelle bidragyder og små teams, der har brug for at automatisere gentagne browser forskning og datainsamling opgaver uden at skrive kode.
Hvilken Apify Alternativ skal du vælge?
AI-integreret udtræk til forretningsarbejdsflow → FlowHunt
Ingen-kode site overvågning og udtræk → Browse AI
Omdanne hjemmesider til AI vidensbasiser → Firecrawl
Visuelt scraping af kompleks sites → Octoparse
Developer API til proxy og JavaScript rendering → ScraperAPI
Enterprise-scale scraping med anti-bot undvigelse → Bright Data
LinkedIn og social media dataudtræk → PhantomBuster
On-demand browser uddrag opgaver → Bardeen
Til de fleste forretnings use cases — overvågning af konkurrenter, uddrag af lead-data, forskning af prospekter — FlowHunts AI-native tilgang slår Apifys developer-centric model i både opsætningshastighed og arbejdsflow integration. Til høj-volumen tekniske scraping projekter er ScraperAPI og Bright Data de rigtige værktøjer.
Ofte stillede spørgsmål
Apify er en web scraping og automatiseringsplatform, der lader udvikler bygge, implementere og køre web scrapers — kaldet "Actors" — i cloudmiljøet. Den håndterer JavaScript rendering, proxy rotation og planlægning. Brugere kan bygge brugerdefinerede scrapers eller bruge pre-built Actors fra Apify Store til almindelige sites som Amazon, LinkedIn, Google Maps og sociale medier.
Ja — Browse AI har en gratis plan (50 kørsel/måned), Bardeen er gratis til grundlæggende automationer, Firecrawl har et gratis API-lag, og FlowHunts gratis lag inkluderer webgennemse-kapaciteter. For udvikler er open-source biblioteker som Playwright, Puppeteer og Scrapy gratis, men kræver selvforvaltning.
Browse AI er det nemmeste — du viser det bogstaveligt talt hvad der skal skrabes ved at klikke gennem en hjemmeside, og den bygger scraperen automatisk. Octoparse er tilsvarende point-and-click. Bardeen er det bedste til engangs dataudtræk, hvor du vil automatisere gentagne browserhandlinger uden teknisk opsætning.
Firecrawl er specialbygget til AI-applikationer — den konverterer hele hjemmesider til ren, struktureret markdown, som LLM'er kan forbruge direkte. FlowHunt integrerer web-udtræk i AI-agent arbejdsflow, hvilket gør det til det bedste valg, når de udtrykte data skal føres ind i ræsonnements-, opsumerings- eller beslutningsprocesstrin.
For enterprise-scale web data-behov (millioner af sider, kompleks anti-bot undvigelse) er Bright Data det stærkeste alternativ — det driver et af verdens største proxy-netværk og har enterprise-grade scraping-infrastruktur. ScraperAPI er en mere overkommelig mulighed til mid-scale scraping med JavaScript rendering og CAPTCHA-håndtering.
Arshia er AI Workflow Engineer hos FlowHunt. Med en baggrund inden for datalogi og en passion for AI, specialiserer han sig i at skabe effektive workflows, der integrerer AI-værktøjer i daglige opgaver og øger produktivitet og kreativitet.
Arshia Kahani
AI Workflow Engineer
Skrab enhver hjemmeside med AI — Prøv FlowHunt gratis
FlowHunts AI-agenter gennemser internettet, udtræker strukturerede data og sender det til dine arbejdsflow automatisk — ingen scraping-scripts påkrævet.
Bedste Browse AI-alternativer i 2026: 8 webscrapingværktøjer sammenlignet
Leder du efter Browse AI-alternativer? Vi sammenlignede 8 webscrapings- og dataekstrationsværktøjer — fra AI-drevne scrapere til fulde automatiseringsplatforme ...
Integrer FlowHunt med Apify Actors MCP Server for at automatisere og orkestrere web scraping i stor skala, dataudtræk og aktørstyring ved hjælp af AI-drevne arb...
10 bedste AI-webscrapere i 2026: rangeret og anmeldt
De 10 bedste AI-webscrapere i 2026, rangeret efter udtrækningsnøjagtighed, brugervenlighed, anti-bot-håndtering og priser. Find det rigtige AI-scrapingværktøj t...
10 min læsning
Web Scraping
AI Tools
+2
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.