
Elasticsearch MCPサーバー
Elasticsearch MCPサーバーは、AIアシスタントとElasticsearchおよびOpenSearchクラスターを連携し、高度な検索、インデックス管理、クラスター操作をAIワークフローから直接実行できるようにします。リアルタイム検索や分析機能をFlowHuntのフローに簡単に統合できます。...
2 分で読める
MCP Server
Elasticsearch
+5

FlowHuntのWikidata MCPサーバー統合でAIアシスタントとWikidataの構造化知識をつなぎ、シームレスなセマンティック検索、メタデータ抽出、SPARQLクエリを実現。
FlowHuntは、お客様の内部システムとAIツールの間に追加のセキュリティレイヤーを提供し、MCPサーバーからアクセス可能なツールをきめ細かく制御できます。私たちのインフラストラクチャーでホストされているMCPサーバーは、FlowHuntのチャットボットや、ChatGPT、Claude、さまざまなAIエディターなどの人気のAIプラットフォームとシームレスに統合できます。
Wikidata MCPサーバーは、Model Context Protocol(MCP)のサーバー実装であり、Wikidata APIと直接連携するために設計されています。AIアシスタントとWikidataの膨大な構造化知識の橋渡しを担い、開発者やAIエージェントがエンティティ・プロパティIDの検索、メタデータ(ラベルや説明など)の抽出、SPARQLクエリの実行をシームレスに行えるようにします。これらの機能をMCPツールとして公開することで、外部の構造化データが必要な開発ワークフローにおけるセマンティック検索、ナレッジ抽出、コンテキスト強化などのタスクを実現します。Wikidataから最新情報を取得・クエリ・推論できるため、AI駆動アプリケーションの能力が高まります。
リポジトリやドキュメントにプロンプトテンプレートは記載されていません。
リポジトリやドキュメントに明示的なMCPリソースの記載はありません。
最新のヒント、トレンド、お得な情報を無料で入手。
mcpServersにWikidata MCPサーバーを追加します。"mcpServers": {
"wikidata-mcp": {
"command": "npx",
"args": ["@zzaebok/mcp-wikidata@latest"]
}
}
APIキーのセキュア設定(必要な場合):
{
"wikidata-mcp": {
"env": {
"WIKIDATA_API_KEY": "your-api-key"
},
"inputs": {
"some_input": "value"
}
}
}
"mcpServers": {
"wikidata-mcp": {
"command": "npx",
"args": ["@zzaebok/mcp-wikidata@latest"]
}
}
APIキーのセキュア設定:
{
"wikidata-mcp": {
"env": {
"WIKIDATA_API_KEY": "your-api-key"
}
}
}
"mcpServers": {
"wikidata-mcp": {
"command": "npx",
"args": ["@zzaebok/mcp-wikidata@latest"]
}
}
APIキーのセキュア設定:
{
"wikidata-mcp": {
"env": {
"WIKIDATA_API_KEY": "your-api-key"
}
}
}
"mcpServers": {
"wikidata-mcp": {
"command": "npx",
"args": ["@zzaebok/mcp-wikidata@latest"]
}
}
APIキーのセキュア設定:
{
"wikidata-mcp": {
"env": {
"WIKIDATA_API_KEY": "your-api-key"
}
}
}
FlowHuntでのMCP利用
FlowHuntワークフローにMCPサーバーを統合するには、まずMCPコンポーネントをフローに追加し、AIエージェントに接続します。

MCPコンポーネントをクリックして設定パネルを開き、system MCP設定欄に下記JSON形式でMCPサーバー情報を挿入します。
{
"wikidata-mcp": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
設定が完了すると、AIエージェントはこのMCPをツールとして利用可能になり、全機能へアクセスできます。“wikidata-mcp"は実際のMCPサーバー名に、URLは自身のMCPサーバーURLに変更してください。
| セクション | 利用可否 | 詳細・備考 |
|---|---|---|
| 概要 | ✅ | README.mdに概要あり |
| プロンプト一覧 | ⛔ | プロンプトテンプレートなし |
| リソース一覧 | ⛔ | 明示的なリソース記載なし |
| ツール一覧 | ✅ | README.mdに詳細記載 |
| APIキーのセキュア設定 | ⛔ | 明示的なAPIキー要件なし |
| サンプリングサポート(評価には重要度低) | ⛔ | 記載なし |
Wikidata MCPサーバーはシンプルながら効果的な実装で、MCP経由でWikidataと連携するための有用なツールを多数提供しています。ただし、プロンプトテンプレートやリソース、サンプリング/ルーツサポートに関するドキュメントが不足しており、より高度または標準化されたMCP統合には柔軟性が制限されます。ライセンスの明記、明確なツール構成、アクティブな更新により、Wikidata特化型のMCPユースケースには好適な出発点です。
| ライセンス有無 | ✅ (MIT) |
|---|---|
| ツールが1つ以上ある | ✅ |
| フォーク数 | 5 |
| スター数 | 18 |
MCPサーバーレーティング: 6/10
コア機能は堅実ですが、標準的なMCPリソース・プロンプトサポートや高度な機能に欠けます。Wikidata直接統合用途には有用です。
Wikidata MCPサーバーは、Model Context Protocolの実装であり、AIエージェントやツールをWikidata APIへ直接接続します。エンティティやプロパティの検索、メタデータ抽出、SPARQLクエリの実行など、高度なセマンティックデータ取得や強化が可能です。
エンティティ・プロパティIDの検索、エンティティのプロパティ取得、ラベルや説明の抽出、SPARQLクエリの実行が、シンプルなMCPツールインターフェースを通じて利用できます。
フローにMCPコンポーネントを追加し、Wikidata MCPサーバーの詳細を設定してAIエージェントに接続します。これでワークフロー内の全Wikidata MCPツールが利用可能になります。
一般的なセットアップでは、公開WikidataデータへのアクセスにAPIキーは不要です。プロキシ利用や高度な用途など、必要な場合はサーバーの環境設定で指定できます。
セマンティックデータ取得、メタデータ強化、自動SPARQLクエリ、ナレッジグラフ探索、Wikidata構造化データに基づくAIリコメンデーションなどに活用できます。
FlowHuntのワークフローにWikidataを構造化知識ソースとして追加し、AIの推論やデータ能力を強化しましょう。
Elasticsearch MCPサーバーは、AIアシスタントとElasticsearchおよびOpenSearchクラスターを連携し、高度な検索、インデックス管理、クラスター操作をAIワークフローから直接実行できるようにします。リアルタイム検索や分析機能をFlowHuntのフローに簡単に統合できます。...
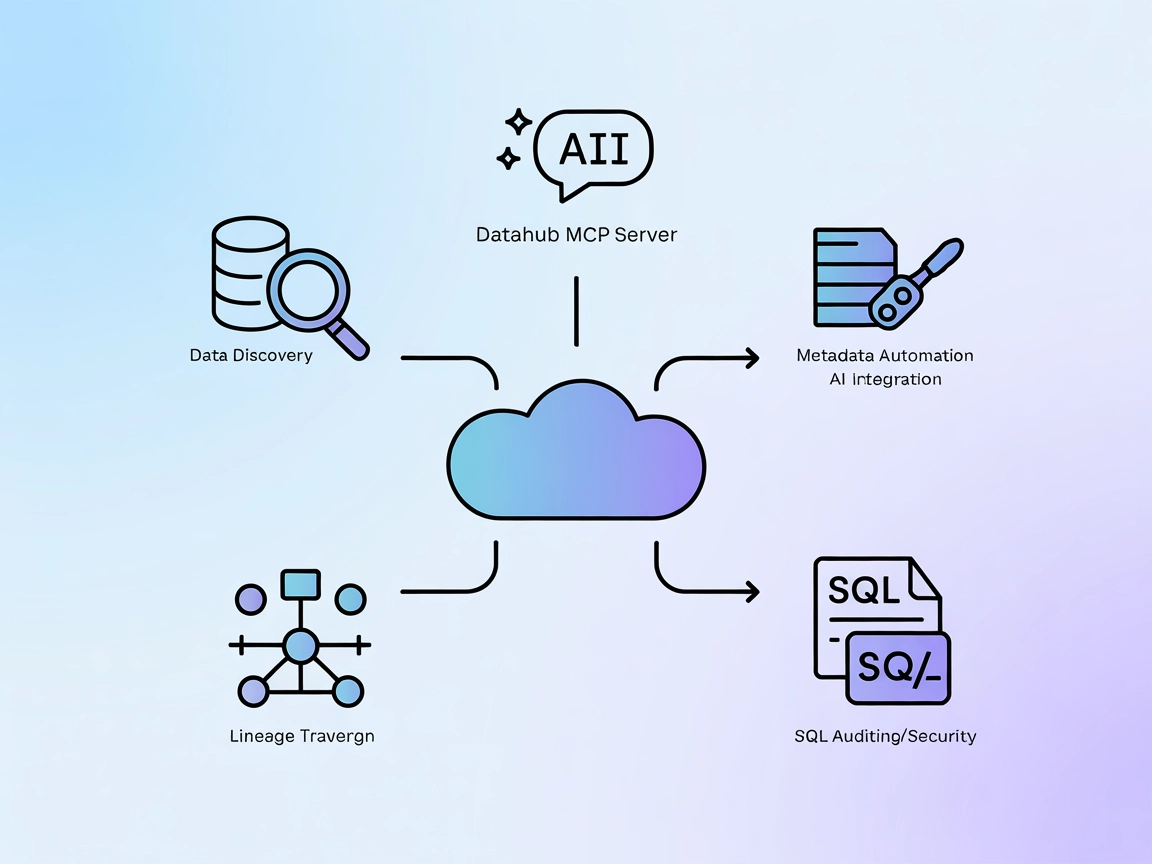
DataHub MCPサーバーは、FlowHuntのAIエージェントとDataHubメタデータプラットフォームを橋渡しし、高度なデータ探索、リネージ分析、自動メタデータ取得、AI駆動ワークフローとのシームレスな統合を実現します。...

Azure Wiki Search MCP サーバーは、AI エージェントや開発者が Azure DevOps wiki からプログラムによる検索やコンテンツ取得を可能にし、MCP 仕様を通じて社内ドキュメントやナレッジベースへのアクセスを効率化します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.