RAG mit Reasoning-LLMs: OpenAI O1 vs. OpenAI GPT4o
OpenAI O1 nutzt Reinforcement Learning und native Chain-of-Thought-Reasoning, um GPT4o bei komplexen RAG-Aufgaben zu übertreffen – allerdings zu höheren Kosten.
OpenAI O1
GPT4o
RAG
Reasoning
AI Agents
Benchmarks
OpenAI hat gerade ein neues Modell namens OpenAI O1aus der O1-Serie veröffentlicht. Die wichtigste architektonische Änderung dieser Modelle ist die Fähigkeit, vor der Beantwortung einer Benutzeranfrage nachzudenken. In diesem Blog gehen wir ausführlich auf die wichtigsten Neuerungen von OpenAI O1 ein, die neuen Paradigmen, die diese Modelle verwenden, und wie dieses Modell die RAG-Genauigkeit deutlich steigern kann. Wir vergleichen dabei einen einfachen RAG-Flow mit dem OpenAI GPT4o und dem OpenAI O1 Modell.
Worin unterscheidet sich OpenAI O1 von früheren Modellen?
Groß angelegtes Reinforcement Learning
Das O1-Modell nutzt groß angelegte Reinforcement-Learning-Algorithmen während seines Trainingsprozesses. Dadurch kann das Modell eine robuste „Chain of Thought“ entwickeln, die es ihm ermöglicht, Probleme tiefer und strategischer zu durchdenken. Durch kontinuierliche Optimierung seiner Reasoning-Pfade mittels Reinforcement Learning verbessert das O1-Modell seine Fähigkeit, komplexe Aufgaben effizient zu analysieren und zu lösen, erheblich.
Chain-of-Thought-Integration
Bisher hat sich Chain of Thought als nützliches Prompt-Engineering-Verfahren erwiesen, um LLMs dazu zu bringen, eigenständig Schritt für Schritt komplexe Fragen zu beantworten. Bei O1-Modellen ist dieser Schritt fest integriert und kommt standardmäßig zur Inferenzzeit zum Einsatz, was sie für mathematische und programmiertechnische Problemlösungen besonders nützlich macht.
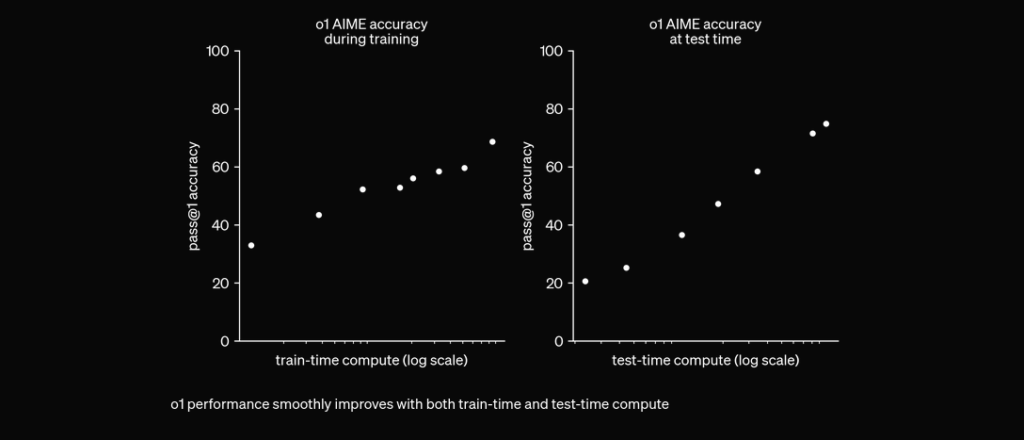
O1 wird mit RL trainiert, um vor der Antwort über eine private Chain of Thought „nachzudenken“. Je länger es nachdenkt, desto besser schneidet es bei Reasoning-Aufgaben ab. Das eröffnet eine neue Skalierungsdimension. Wir sind nicht mehr nur durch Pretraining limitiert. Wir können jetzt auch die Inferenz-Rechenleistung skalieren. pic.twitter.com/niqRO9hhg1 — Noam Brown (@polynoamial) 12. September 2024
Überlegene Benchmark-Leistung
In umfangreichen Evaluierungen hat das O1-Modell bemerkenswerte Leistungen in verschiedenen Benchmarks gezeigt:
AIME (American Invitational Mathematics Examination): Löst 83 % der Aufgaben korrekt – ein erheblicher Fortschritt gegenüber den 13 % von GPT-4o.
GPQA (Expert-Level Test in Sciences): Übertrifft Experten mit PhD-Abschluss und ist das erste KI-Modell, das Menschen in diesem Benchmark schlägt.
MMLU (Multi-Task Language Understanding): Überdurchschnittliche Leistung in 54 von 57 Unterkategorien mit 78,2 % bei aktivierter visueller Wahrnehmung.
Coding-Wettbewerbe: Erreicht hohe Platzierungen auf Plattformen wie Codeforces und übertrifft 93 % der menschlichen Teilnehmer.
OpenAI O1 vs. OpenAI GPT4o im RAG-Flow
Um die Performance-Genauigkeit von OpenAI O1 und GPT4o zu testen, haben wir zwei identische Flows erstellt, jedoch jeweils mit einem anderen LLM. Wir vergleichen die Frage-Antwort-Fähigkeit der Modelle anhand von zwei Quellen, die zum technischen Bericht von OpenAI O1 indexiert sind.
Zunächst erstellen wir im FlowHunt einen einfachen RAG-Flow. Er besteht aus Chat Input, Document Retriever (holt relevante Dokumente), Prompt, Generator und Chat Output. Die LLM-OpenAI-Komponente wird hinzugefügt, um das Modell auszuwählen (ansonsten wird standardmäßig GPT4o genutzt).
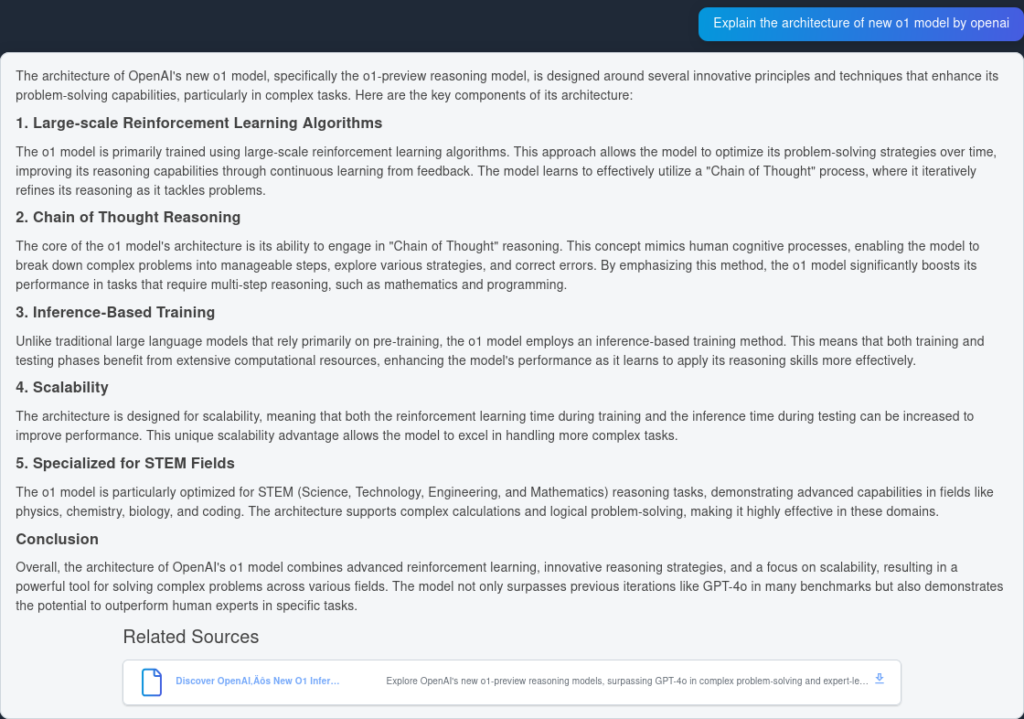
Hier ist die Antwort von GPT4o:
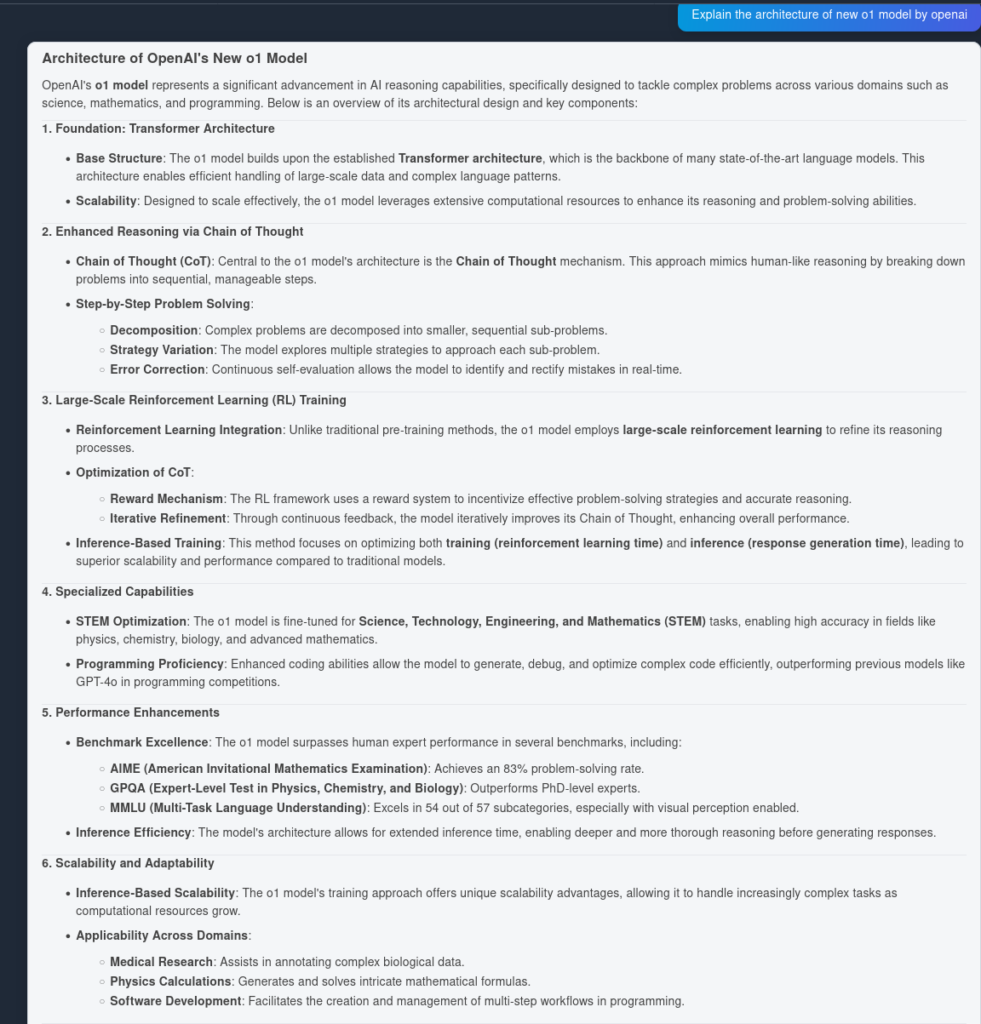
Und hier das Ergebnis von OpenAI O1:
Wie man sieht, hat OpenAI O1 mehr architektonische Vorteile aus dem Artikel herausgearbeitet – 6 Punkte statt 4. Außerdem zieht O1 logische Schlussfolgerungen aus jedem Punkt und bereichert das Dokument mit zusätzlichen Erkenntnissen, warum die architektonische Änderung sinnvoll ist.
Bereit, Ihr Geschäft zu erweitern?
Starten Sie heute Ihre kostenlose Testversion und sehen Sie innerhalb weniger Tage Ergebnisse.
In unseren Experimenten kostet das O1-Modell mehr für die gesteigerte Genauigkeit. Das neue Modell verfügt über drei Token-Typen: Prompt Token, Completion Token und Reason Token (ein neu hinzugefügter Token-Typ), was potenziell teurer ist. In den meisten Fällen liefert OpenAI O1 hilfreichere Antworten, sofern sie auf Fakten beruhen. Es gibt jedoch auch Fälle, in denen GPT4o OpenAI O1 übertrifft – manche Aufgaben benötigen schlicht kein Reasoning.
Häufig gestellte Fragen
OpenAI O1 verwendet groß angelegtes Reinforcement Learning und integriert Chain-of-Thought-Reasoning zur Inferenzzeit, was ein tieferes, strategischeres Problemlösen als bei GPT4o ermöglicht.
Ja, O1 erzielt höhere Werte in Benchmarks wie AIME (83 % vs. 13 % bei GPT4o), GPQA (übertrifft Experten auf PhD-Niveau) und MMLU und ist in 54 von 57 Kategorien führend.
Nicht immer. Während O1 bei reasoning-intensiven Aufgaben glänzt, kann GPT4o bei einfacheren Anwendungsfällen, die kein fortgeschrittenes Reasoning erfordern, besser abschneiden.
O1 führt einen neuen 'Reason'-Token zusätzlich zu Prompt- und Completion-Tokens ein, was anspruchsvolleres Reasoning ermöglicht, aber die Betriebskosten erhöhen kann.
Sie können Plattformen wie FlowHunt nutzen, um RAG-Flows und KI-Agenten mit OpenAI O1 für Aufgaben zu erstellen, die fortschrittliches Reasoning und genaue Dokumentenrecherche erfordern.
Yasha ist ein talentierter Softwareentwickler mit Spezialisierung auf Python, Java und Machine Learning. Yasha schreibt technische Artikel über KI, Prompt Engineering und Chatbot-Entwicklung.
Yasha Boroumand
CTO, FlowHunt
Erstellen Sie fortschrittliche RAG-Flows mit FlowHunt
Testen Sie FlowHunt, um die neuesten LLMs wie OpenAI O1 und GPT4o für überlegene Reasoning- und Retrieval-Augmented-Generation zu nutzen.
GPT-5 Erscheinungsdatum OpenAI: Neueste Updates, o1-Modelle und was als Nächstes kommt
Erfahren Sie das offizielle Erscheinungsdatum von GPT-5 von OpenAI, wie es auf o1 und GPT-4o aufbaut und was die nächste Generation von KI-Modellen für Entwickl...
Wie LLMs als KI-Agenten denken — Modellvergleich (Claude, GPT, Gemini, Llama, Mistral, Grok, DeepSeek)
Wie denken große Sprachmodelle wirklich in einem KI-Agenten? Praktischer Modellvergleich von Claude, GPT und o-Serie, Gemini, Llama, Mistral, Grok und DeepSeek ...
Wie OpenAI's o1 Preview komplexe Schreibaufgaben meistert
Entdecken Sie, wie OpenAI’s o1 Preview GPT-4 übertrifft, indem es komplexe Schreibaufgaben durch interne Planung, Kreativität und Einhaltung von Vorgaben meiste...
3 Min. Lesezeit
OpenAI
o1 Preview
+5
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.