OpenAI vừa ra mắt một mô hình mới mang tên OpenAI O1
thuộc dòng O1. Thay đổi chính về kiến trúc ở các mô hình này là khả năng “suy nghĩ” trước khi trả lời câu hỏi của người dùng. Trong bài viết này, chúng ta sẽ đi sâu vào các thay đổi then chốt của OpenAI O1, những cách tiếp cận mới mà các mô hình này sử dụng, và lý do vì sao mô hình này có thể tăng đáng kể độ chính xác của RAG. Chúng tôi sẽ so sánh một flow RAG đơn giản sử dụng OpenAI GPT4o và OpenAI O1.
OpenAI O1 khác gì so với các mô hình trước?
Học tăng cường quy mô lớn
Mô hình O1 tận dụng các thuật toán học tăng cường quy mô lớn trong quá trình huấn luyện. Điều này giúp mô hình phát triển “Chuỗi suy nghĩ” vững chắc, cho phép suy nghĩ sâu và chiến lược hơn về các vấn đề. Bằng cách liên tục tối ưu hóa đường suy luận của mình qua học tăng cường, O1 cải thiện đáng kể khả năng phân tích và giải quyết các tác vụ phức tạp một cách hiệu quả.
Tích hợp Chuỗi suy nghĩ
Trước đây, chuỗi suy nghĩ đã được chứng minh là một kỹ thuật nhắc lệnh hiệu quả giúp LLM “tự suy nghĩ” và trả lời các câu hỏi phức tạp theo từng bước một. Với các mô hình O1, bước này đã được tích hợp sẵn trong mô hình khi suy luận, cực kỳ hữu ích cho các bài toán toán học và lập trình.
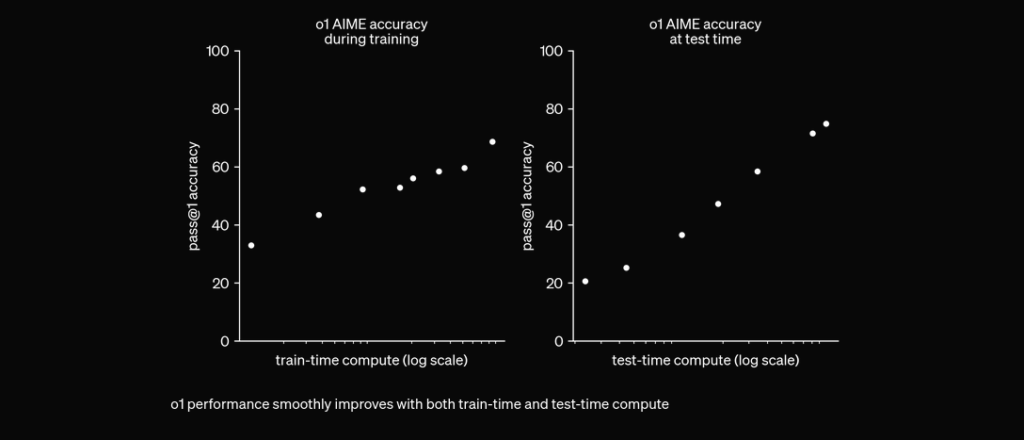
O1 được huấn luyện với RL để “suy nghĩ” trước khi trả lời qua chuỗi suy nghĩ riêng tư. Càng suy nghĩ lâu, khả năng lý luận càng tốt. Điều này mở ra một khía cạnh mới cho việc mở rộng quy mô. Không còn bị giới hạn bởi tiền huấn luyện. Chúng ta có thể mở rộng cả tính toán suy luận. pic.twitter.com/niqRO9hhg1 — Noam Brown (@polynoamial) 12 tháng 9, 2024
Hiệu năng vượt trội trên các chỉ số đánh giá
Qua các thử nghiệm rộng rãi, O1 đã thể hiện hiệu suất xuất sắc trên nhiều chỉ số đánh giá:
AIME (Kỳ thi Toán Mỹ): Giải đúng 83% bài toán, vượt xa 13% của GPT-4o.
GPQA (Bài kiểm tra trình độ chuyên gia khoa học): Vượt qua các chuyên gia tiến sĩ, là mô hình AI đầu tiên vượt trội hơn con người trên chỉ số này.
MMLU (Hiểu ngôn ngữ đa nhiệm): Xuất sắc ở 54/57 phân mục, đạt 78.2% khi kích hoạt nhận diện hình ảnh.
Thi lập trình: Đạt thứ hạng cao trên Codeforces, vượt 93% người thi.
So sánh OpenAI O1 và OpenAI GPT4o trong Flow RAG
Để kiểm tra độ chính xác của OpenAI O1 và GPT4o, chúng tôi đã tạo hai flow giống hệt nhau nhưng dùng hai LLM khác nhau. Chúng ta sẽ so sánh khả năng trả lời câu hỏi của các mô hình dựa trên hai nguồn tài liệu đã được lập chỉ mục về báo cáo kỹ thuật của OpenAI O1.
Đầu tiên, chúng tôi tạo một flow RAG đơn giản trên FlowHunt. Flow gồm Chat Input, Document Retriever (truy xuất tài liệu liên quan), Prompt, Generator và Chat Output. Thành phần LLM OpenAI được thêm để chỉ định mô hình (mặc định là GPT4o nếu không chỉ rõ).
Đây là phản hồi từ GPT4o:
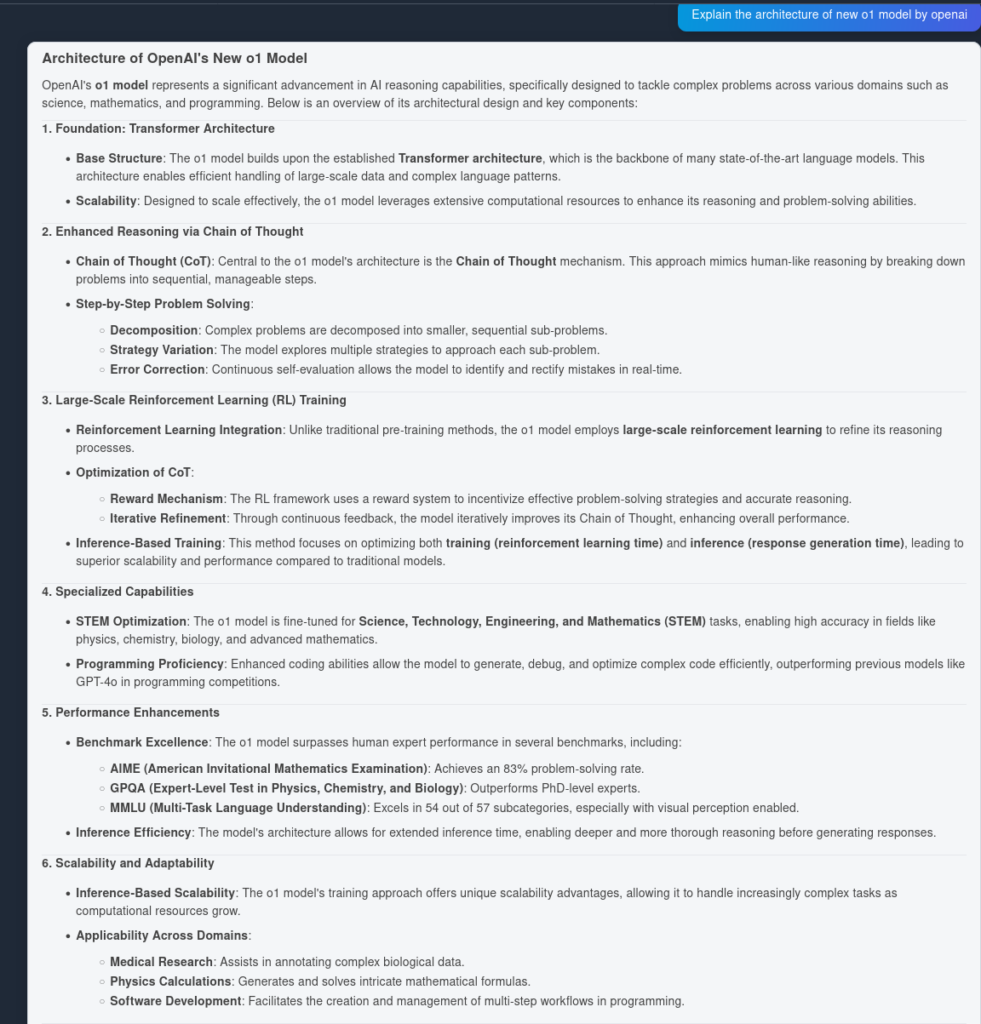
Và đây là kết quả từ OpenAI O1:
Như bạn thấy, OpenAI O1 đã nắm bắt nhiều lợi thế kiến trúc hơn từ bài viết—6 điểm so với 4 điểm của GPT4o. Ngoài ra, O1 còn đưa ra các suy luận logic từ từng điểm, làm giàu cho tài liệu với những phân tích sâu hơn về giá trị của thay đổi kiến trúc.
Sẵn sàng phát triển doanh nghiệp của bạn?
Bắt đầu dùng thử miễn phí ngay hôm nay và xem kết quả trong vài ngày.
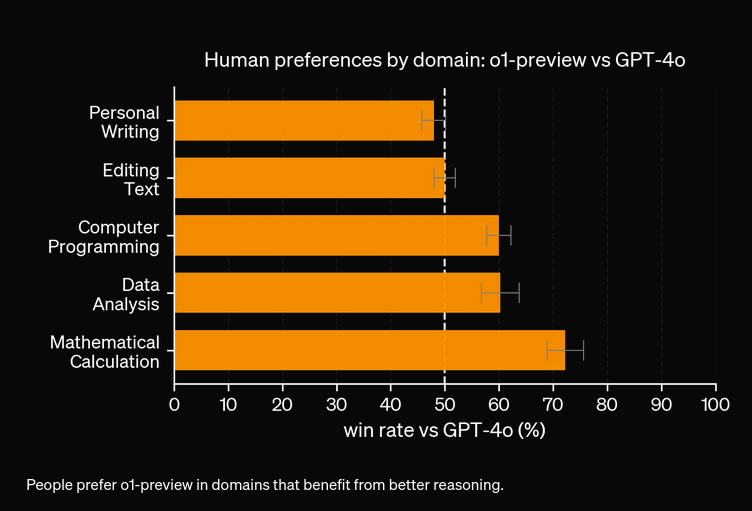
Qua thử nghiệm, mô hình O1 sẽ có chi phí cao hơn để đổi lại độ chính xác tăng lên. Mô hình mới có 3 loại token: Prompt Token, Completion Token, và Reason Token (loại token mới bổ sung), dẫn tới khả năng chi phí vận hành cao hơn. Trong đa số trường hợp, OpenAI O1 cho ra đáp án hữu ích hơn nếu dựa trên sự thật. Tuy nhiên, vẫn có trường hợp GPT4o vượt trội hơn O1—một số tác vụ đơn giản không cần lý luận.
Câu hỏi thường gặp
OpenAI O1 sử dụng học tăng cường quy mô lớn và tích hợp lý luận chuỗi suy nghĩ khi suy luận, cho phép giải quyết vấn đề sâu sắc và chiến lược hơn so với GPT4o.
Có, O1 đạt điểm cao hơn trong các đánh giá như AIME (83% so với 13% của GPT4o), GPQA (vượt các chuyên gia trình độ tiến sĩ), và MMLU, xuất sắc ở 54 trên 57 hạng mục.
Không phải lúc nào cũng vậy. Dù O1 xuất sắc ở các tác vụ đòi hỏi lý luận, GPT4o có thể vượt trội hơn trong các trường hợp đơn giản không yêu cầu lý luận nâng cao.
O1 giới thiệu token 'Reason' mới bên cạnh Prompt và Completion token, cho phép lý luận tinh vi hơn nhưng có thể làm tăng chi phí vận hành.
Bạn có thể sử dụng các nền tảng như FlowHunt để xây dựng flows RAG và tác nhân AI với OpenAI O1 cho các tác vụ cần lý luận nâng cao và truy xuất tài liệu chính xác.
Yasha là một nhà phát triển phần mềm tài năng, chuyên về Python, Java và học máy. Yasha viết các bài báo kỹ thuật về AI, kỹ thuật prompt và phát triển chatbot.
Yasha Boroumand
CTO, FlowHunt
Xây dựng Flows RAG nâng cao với FlowHunt
Trải nghiệm FlowHunt để tận dụng các LLM mới nhất như OpenAI O1 và GPT4o cho lý luận vượt trội và sinh kết quả tăng cường truy xuất.
Ngày Ra Mắt GPT-5 OpenAI: Cập Nhật Mới Nhất, Các Mẫu o1 và Tương Lai AI
Khám phá ngày ra mắt chính thức của GPT-5 bởi OpenAI, cách nó phát triển từ o1 và GPT-4o, cũng như ý nghĩa của thế hệ AI mới cho các nhà phát triển và doanh ngh...
Cách o1 Preview của OpenAI Chinh Phục Những Đề Bài Viết Phức Tạp
Khám phá cách o1 Preview của OpenAI vượt trội hơn GPT-4 khi chinh phục các đề bài viết phức tạp thông qua lập kế hoạch nội bộ, sáng tạo và tuân thủ các ràng buộ...
LLM lập luận như AI agent thế nào — So sánh từng mô hình (Claude, GPT, Gemini, Llama, Mistral, Grok, DeepSeek)
Các mô hình ngôn ngữ lớn thực sự lập luận thế nào bên trong một AI agent? So sánh thực dụng từng mô hình: Claude, GPT và dòng o, Gemini, Llama, Mistral, Grok và...
15 phút đọc
AI Agents
LLM
+9
Đồng Ý Cookie Chúng tôi sử dụng cookie để cải thiện trải nghiệm duyệt web của bạn và phân tích lưu lượng truy cập của mình. See our privacy policy.