RAG con LLMs de razonamiento: OpenAI O1 vs OpenAI GPT4o
OpenAI O1 aprovecha el aprendizaje por refuerzo y el razonamiento nativo de cadena de pensamiento para superar a GPT4o en tareas complejas de RAG, aunque a un costo más alto.
OpenAI acaba de lanzar un nuevo modelo llamado OpenAI O1
de la serie O1 de modelos. El principal cambio arquitectónico en estos modelos es la capacidad de pensar antes de responder a la consulta de un usuario. En este blog, profundizaremos en los cambios clave de OpenAI O1, los nuevos paradigmas que utilizan estos modelos y cómo este modelo puede aumentar significativamente la precisión en RAG. Compararemos un flujo RAG simple usando OpenAI GPT4o y el modelo OpenAI O1.
¿En qué se diferencia OpenAI O1 de modelos anteriores?
Aprendizaje por Refuerzo a Gran Escala
El modelo O1 aprovecha algoritmos de aprendizaje por refuerzo a gran escala durante su proceso de entrenamiento. Esto permite que el modelo desarrolle una sólida “Cadena de Pensamiento”, permitiéndole pensar de forma más profunda y estratégica sobre los problemas. Al optimizar continuamente sus vías de razonamiento mediante aprendizaje por refuerzo, el modelo O1 mejora significativamente su capacidad para analizar y resolver tareas complejas de manera eficiente.
Integración de Cadena de Pensamiento
Anteriormente, la cadena de pensamiento ha demostrado ser un mecanismo útil de ingeniería de prompts para hacer que un LLM “piense” por sí mismo y responda preguntas complejas siguiendo un plan paso a paso. Con los modelos O1, este paso viene incorporado y está integrado de forma nativa en el modelo en el momento de la inferencia, haciéndolo útil para tareas de resolución de problemas matemáticos y de codificación.
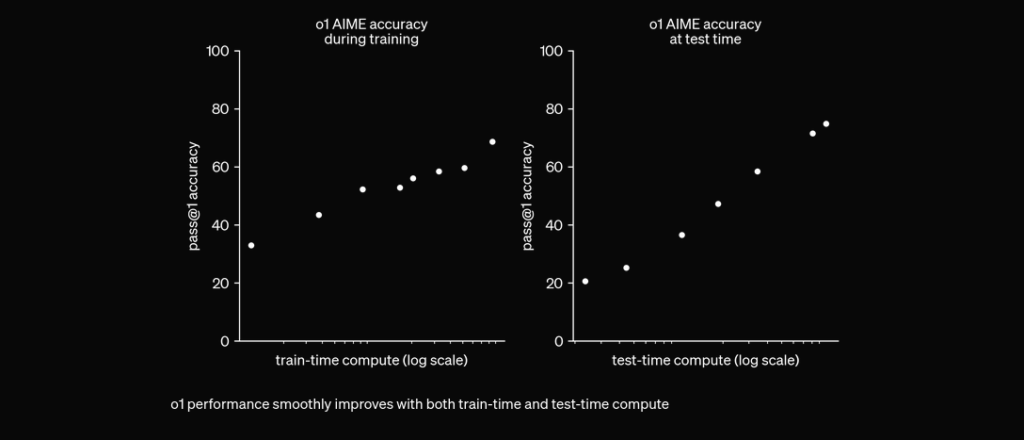
O1 está entrenado con RL para “pensar” antes de responder mediante una cadena de pensamiento privada. Cuanto más tiempo piensa, mejor rinde en tareas de razonamiento. Esto abre una nueva dimensión para escalar. Ya no estamos limitados por el preentrenamiento. Ahora también podemos escalar el cómputo en inferencia. pic.twitter.com/niqRO9hhg1 — Noam Brown (@polynoamial) 12 de septiembre de 2024
Rendimiento Superior en Benchmarks
En evaluaciones extensas, el modelo O1 ha demostrado un rendimiento sobresaliente en varios benchmarks:
AIME (American Invitational Mathematics Examination): Resuelve correctamente el 83% de los problemas, una mejora sustancial respecto al 13% de GPT-4o.
GPQA (Prueba de nivel experto en ciencias): Supera a expertos con doctorado, siendo el primer modelo de IA en superar a humanos en este benchmark.
MMLU (Comprensión de Lenguaje Multi-Tarea): Destaca en 54 de 57 subcategorías, logrando un 78.2% de rendimiento con percepción visual habilitada.
Competiciones de Programación: Logra posiciones altas en plataformas como Codeforces, superando al 93% de los competidores humanos.
OpenAI O1 vs OpenAI GPT4o en Flujos RAG
Para probar la precisión de OpenAI O1 y GPT4o, creamos dos flujos idénticos pero con dos LLMs diferentes. Compararemos la capacidad de respuesta a preguntas de los modelos sobre dos fuentes indexadas relativas al informe técnico de OpenAI O1.
Primero, crearemos un flujo RAG simple en FlowHunt. Consiste en Entrada de Chat, Recuperador de Documentos (que obtiene documentos relevantes), Prompt, Generador y Salida de Chat. Se añade el componente LLM de OpenAI para especificar el modelo (de lo contrario, se usa GPT4o por defecto).
Aquí está la respuesta de GPT4o:
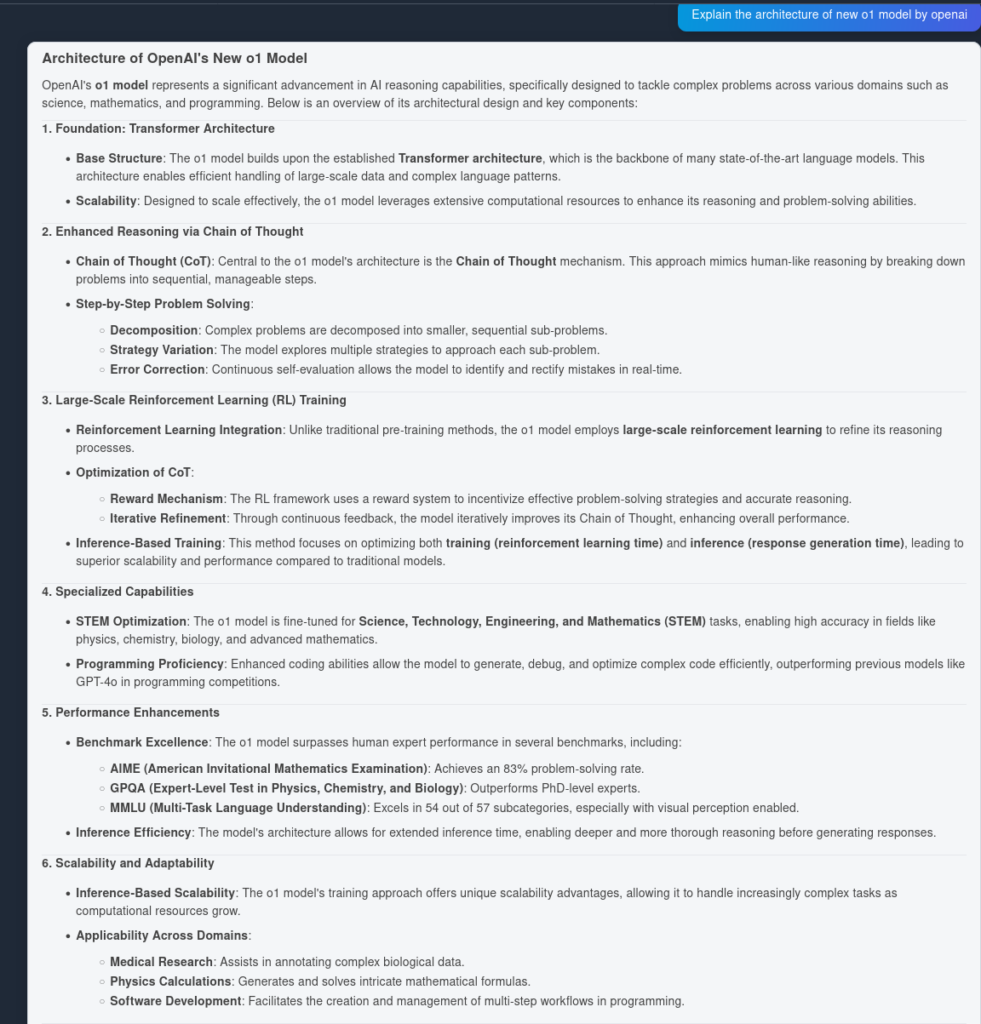
Y aquí está el resultado de OpenAI O1:
Como se puede ver, OpenAI O1 capturó más ventajas arquitectónicas del propio artículo—6 puntos frente a 4. Además, O1 hace inferencias lógicas desde cada punto, enriqueciendo el documento con más ideas sobre por qué el cambio arquitectónico es útil.
¿Listo para hacer crecer tu negocio?
Comienza tu prueba gratuita hoy y ve resultados en días.
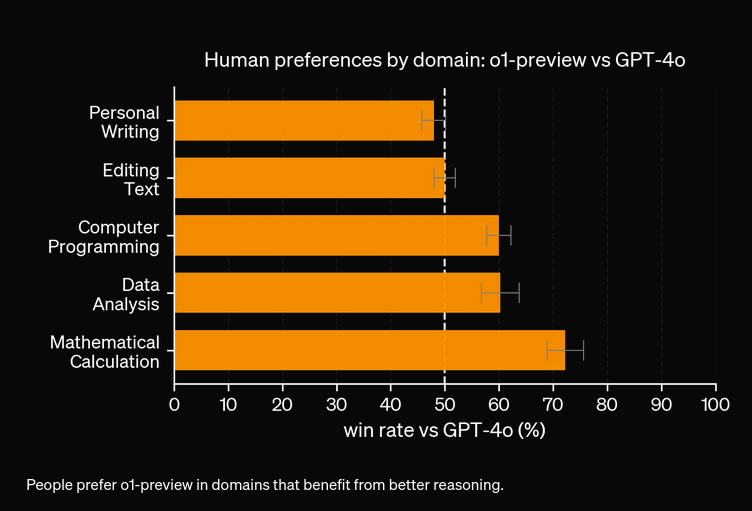
Según nuestros experimentos, el modelo O1 costaría más a cambio de mayor precisión. El nuevo modelo tiene 3 tipos de tokens: Token de Prompt, Token de Completion y Token de Reason (un tipo de token recién añadido), lo que potencialmente lo vuelve más caro. En la mayoría de los casos, OpenAI O1 proporciona respuestas que parecen más útiles si están fundamentadas en la verdad. Sin embargo, hay instancias en las que GPT4o supera a OpenAI O1—algunas tareas simplemente no necesitan razonamiento.
Preguntas frecuentes
OpenAI O1 utiliza aprendizaje por refuerzo a gran escala e integra razonamiento de cadena de pensamiento en tiempo de inferencia, lo que permite una resolución de problemas más profunda y estratégica que GPT4o.
Sí, O1 logra puntuaciones más altas en benchmarks como AIME (83% vs. 13% de GPT4o), GPQA (superando a expertos a nivel de doctorado) y MMLU, destacándose en 54 de 57 categorías.
No siempre. Aunque O1 destaca en tareas que requieren mucho razonamiento, GPT4o puede superarlo en casos de uso más simples que no requieren razonamiento avanzado.
O1 introduce un nuevo token 'Reason' además de los tokens Prompt y Completion, lo que permite razonamientos más sofisticados pero puede incrementar el costo operativo.
Puedes usar plataformas como FlowHunt para crear flujos RAG y agentes de IA con OpenAI O1 para tareas que requieran razonamiento avanzado y recuperación de documentos precisa.
Yasha es un talentoso desarrollador de software especializado en Python, Java y aprendizaje automático. Yasha escribe artículos técnicos sobre IA, ingeniería de prompts y desarrollo de chatbots.
Yasha Boroumand
CTO, FlowHunt
Crea Flujos RAG Avanzados con FlowHunt
Prueba FlowHunt para aprovechar los últimos LLMs como OpenAI O1 y GPT4o para un razonamiento y generación aumentada por recuperación superiores.
Fecha de lanzamiento de GPT-5 OpenAI: Últimas actualizaciones, modelos o1 y lo que viene
Descubre la fecha oficial de lanzamiento de GPT-5 por OpenAI, cómo se basa en o1 y GPT-4o, y lo que la próxima generación de modelos de IA significa para desarr...
Cómo razonan los LLM como agentes de IA — Comparativa por modelo (Claude, GPT, Gemini, Llama, Mistral, Grok, DeepSeek)
¿Cómo razonan realmente los modelos de lenguaje grandes dentro de un agente de IA? Comparativa práctica modelo por modelo: Claude, GPT y serie o, Gemini, Llama,...
Cómo el avance o1 Preview de OpenAI domina indicaciones de escritura complejas
Descubre cómo el avance o1 Preview de OpenAI supera a GPT-4 al dominar indicaciones de escritura complejas mediante planificación interna, creatividad y cumplim...
3 min de lectura
OpenAI
o1 Preview
+5
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.