RAG ja päättelyyn kykenevät LLM:t: OpenAI O1 vs OpenAI GPT4o
OpenAI O1 hyödyntää vahvistusoppimista ja sisäänrakennettua ketjumaista päättelyä, ylittäen GPT4o:n monimutkaisissa RAG-tehtävissä, joskin korkeammalla hinnalla.
OpenAI julkaisi juuri uuden mallin nimeltä OpenAI O1
O1-mallisarjasta. Näiden mallien tärkein arkkitehtuurinen muutos on kyky “ajatella” ennen käyttäjän kysymykseen vastaamista. Tässä blogissa sukellamme syvälle OpenAI O1:n keskeisiin muutoksiin, uusiin paradigmoihin joita nämä mallit hyödyntävät, ja siihen, kuinka tämä malli voi huomattavasti parantaa RAG-tarkkuutta. Vertailumme kohdistuu yksinkertaiseen RAG-prosessiin OpenAI GPT4o:lla ja OpenAI O1 -mallilla.
Miten OpenAI O1 eroaa aiemmista malleista?
Laajamittainen vahvistusoppiminen
O1-malli hyödyntää laajamittaisia vahvistusoppimisalgoritmeja koulutusprosessinsa aikana. Tämä mahdollistaa mallille vankan “Chain of Thought” -päättelyn, jolloin se kykenee pohtimaan ongelmia syvällisemmin ja strategisemmin. Optimoimalla jatkuvasti päättelyreittejään vahvistusoppimisen avulla O1-malli parantaa merkittävästi kykyään analysoida ja ratkaista monimutkaisia tehtäviä tehokkaasti.
Ketjumaisen päättelyn integrointi
Aiemmin ketjumainen päättely on osoittautunut hyödylliseksi prompttien suunnittelumenetelmäksi, joka saa LLM:n “ajattelemaan” itse ja vastaamaan monimutkaisiin kysymyksiin vaiheittain. O1-malleissa tämä vaihe tulee suoraan mallin mukana ja on integroituna natiivisti päättelyvaiheeseen, mikä tekee siitä hyödyllisen matemaattisissa ja koodausongelmien ratkaisutehtävissä.
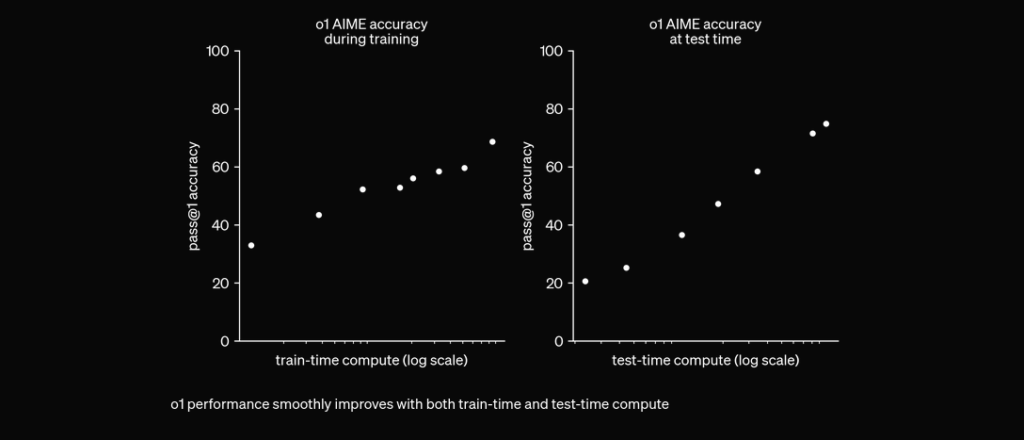
O1 on koulutettu RL:llä “ajattelemaan” ennen vastaamista yksityisen ketjumaisen päättelyn avulla. Mitä pidempään se ajattelee, sitä paremmin se suoriutuu päättelytehtävissä. Tämä avaa uuden ulottuvuuden skaalaamiselle. Emme ole enää esikoulutuksen pullonkaulan armoilla. Nyt voimme skaalata myös päättelylaskentaa. pic.twitter.com/niqRO9hhg1 — Noam Brown (@polynoamial) 12. syyskuuta 2024
Ylivertainen suorituskyky vertailuissa
Laajoissa arvioinneissa O1-malli on osoittanut merkittävää suorituskykyä eri vertailuissa:
AIME (American Invitational Mathematics Examination): Ratkaisee 83 % tehtävistä oikein, mikä on huomattava parannus GPT-4o:n 13 %:iin verrattuna.
GPQA (asiantuntijatason tieteellinen koe): Ohittaa tohtoritason asiantuntijat, ollen ensimmäinen AI-malli, joka päihittää ihmiset tällä mittarilla.
MMLU (Multi-Task Language Understanding): Menestyy 54:ssä 57 alaluokasta, saavuttaen 78,2 % tuloksen visuaalisen havainnoinnin ollessa käytössä.
Koodauskilpailut: Saavuttaa korkeat sijoitukset alustoilla kuten Codeforces, jättäen taakseen 93 % ihmiskilpailijoista.
OpenAI O1 vs OpenAI GPT4o RAG-prosessissa
Testataksemme OpenAI O1:n ja GPT4o:n tarkkuutta loimme kaksi identtistä prosessia, mutta käytimme eri LLM:iä. Vertailimme mallien kykyä vastata kysymyksiin kahdesta, OpenAI O1:n teknistä raporttia käsittelevästä lähteestä.
Ensin luomme yksinkertaisen RAG-prosessin FlowHuntilla. Se sisältää Chat Inputin, Document Retrieverin (noutaa relevantit dokumentit), Promptin, Generatorin ja Chat Outputin. LLM OpenAI -komponenttiin määritetään käytettävä malli (muuten oletuksena on GPT4o).
Tässä GPT4o:n vastaus:
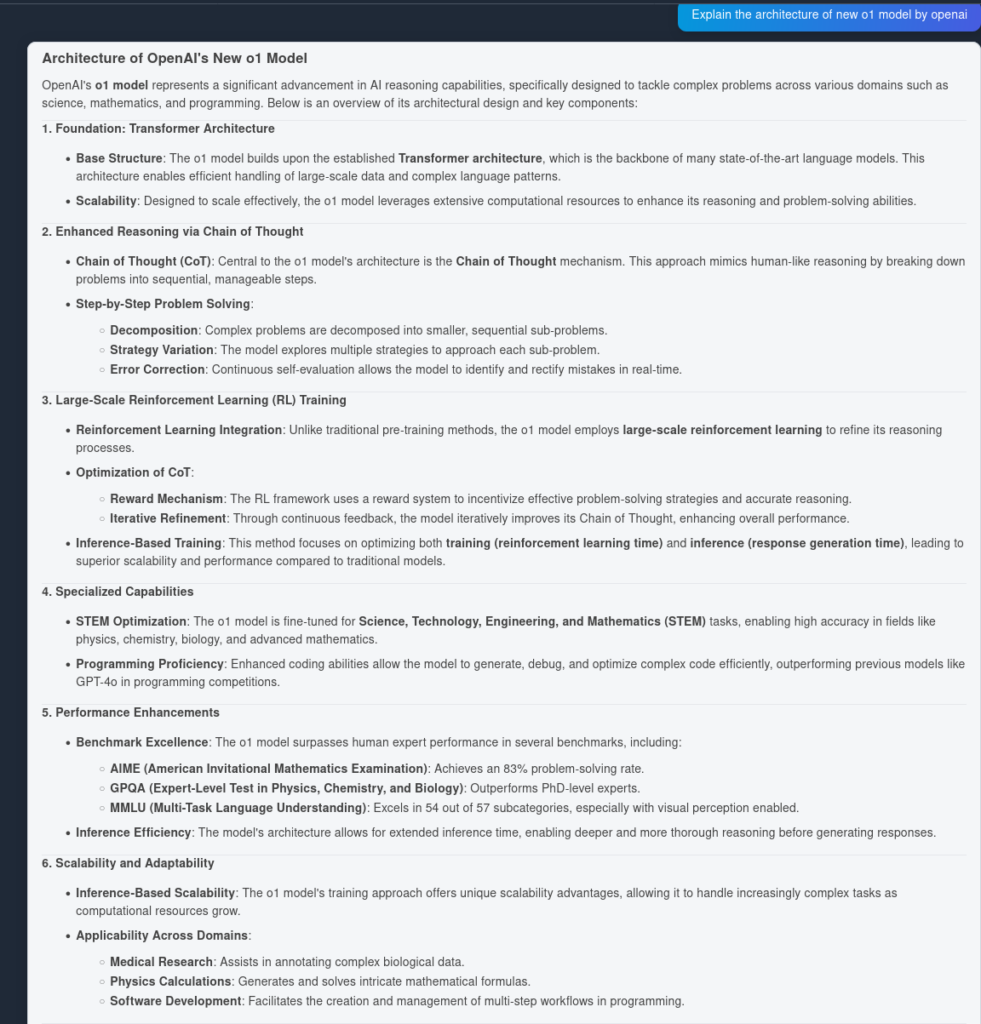
Ja tässä OpenAI O1:n tulos:
Kuten huomaat, OpenAI O1 poimi artikkelista enemmän arkkitehtuurisia yksityiskohtia—6 kohtaa 4:n sijaan. Lisäksi O1 tekee jokaisesta kohdasta loogisia johtopäätöksiä, rikastuttaen dokumenttia näkemyksillä siitä, miksi arkkitehtuurimuutos on hyödyllinen.
Valmis kasvattamaan liiketoimintaasi?
Aloita ilmainen kokeilujakso tänään ja näe tulokset muutamassa päivässä.
Kokeidemme perusteella O1-malli maksaa enemmän, mutta tarjoaa paremman tarkkuuden. Uudessa mallissa on kolme token-tyyppiä: Prompt Token, Completion Token ja Reason Token (uusi token-tyyppi), mikä voi nostaa kustannuksia. Useimmissa tapauksissa OpenAI O1 antaa vastauksia, jotka vaikuttavat hyödyllisemmiltä, jos ne perustuvat totuuteen. On kuitenkin tilanteita, joissa GPT4o päihittää OpenAI O1:n—kaikki tehtävät eivät yksinkertaisesti vaadi päättelyä.
Usein kysytyt kysymykset
OpenAI O1 käyttää laajamittaista vahvistusoppimista ja integroi ketjumaista päättelyä suoraan mallin päättelyvaiheessa, mahdollistaen syvällisemmän ja strategisemman ongelmanratkaisun kuin GPT4o.
Kyllä, O1 saavuttaa korkeammat tulokset vertailuissa kuten AIME (83 % vs. GPT4o:n 13 %), GPQA (ohittaen tohtoritason asiantuntijat) ja MMLU, menestyen 54:ssä 57 kategoriasta.
Ei aina. Vaikka O1 loistaa päättelyintensiivisissä tehtävissä, GPT4o voi olla parempi yksinkertaisemmissa käyttötapauksissa, jotka eivät vaadi edistynyttä päättelyä.
O1 esittelee uuden 'Reason'-tokenin Prompt- ja Completion-tokenien lisäksi, mahdollistaen kehittyneemmän päättelyn mutta kasvattaen mahdollisesti operatiivisia kustannuksia.
Voit käyttää esimerkiksi FlowHuntia rakentaaksesi RAG-prosesseja ja AI-agentteja OpenAI O1:llä tehtäviin, joissa tarvitaan edistynyttä päättelyä ja tarkkaa dokumenttien hakua.
Yasha on lahjakas ohjelmistokehittäjä, joka on erikoistunut Pythoniin, Javaan ja koneoppimiseen. Yasha kirjoittaa teknisiä artikkeleita tekoälystä, prompt engineeringistä ja chatbot-kehityksestä.
Yasha Boroumand
CTO, FlowHunt
Rakenna edistyneitä RAG-prosesseja FlowHuntilla
Kokeile FlowHuntia hyödyntääksesi uusimpia LLM-malleja, kuten OpenAI O1 ja GPT4o, parempaan päättelyyn ja tiedonhakuun perustuvaan generointiin.
GPT-5:n julkaisupäivä OpenAI: Viimeisimmät päivitykset, o1-mallit ja mitä seuraavaksi
Tutustu OpenAI:n GPT-5:n viralliseen julkaisupäivään, miten se rakentuu o1- ja GPT-4o-mallien pohjalle ja mitä seuraavan sukupolven tekoälymallit merkitsevät ke...
Miten suuret kielimallit todella päättelevät AI-agentin sisällä? Käytännön mallivertailu: Claude, GPT ja o-sarja, Gemini, Llama, Mistral, Grok ja DeepSeek — vah...
Kuinka OpenAI:n o1 Preview hallitsee monimutkaisia kirjoitusohjeita
Tutustu, kuinka OpenAI:n o1 Preview ylittää GPT-4:n hallitsemalla monimutkaisia kirjoitusohjeita sisäisen suunnittelun, luovuuden ja rajoituksiin sitoutumisen a...
2 min lukuaika
OpenAI
o1 Preview
+5
Evästeiden Suostumus Käytämme evästeitä parantaaksemme selauskokemustasi ja analysoidaksemme liikennettämme. See our privacy policy.