OpenAI O1 udnytter forstærkningslæring og indbygget ‘chain of thought’-ræsonnement til at overgå GPT4o i komplekse RAG-opgaver, dog til en højere pris.
OpenAI har netop lanceret en ny model kaldet OpenAI O1
fra O1-serien af modeller. Den vigtigste arkitektoniske ændring i disse modeller er evnen til at tænke, før der svares på en brugers forespørgsel. I denne blog dykker vi ned i de vigtigste ændringer i OpenAI O1, de nye paradigmer disse modeller anvender, og hvordan denne model markant kan øge RAG-nøjagtigheden. Vi sammenligner et simpelt RAG-flow med OpenAI GPT4o og OpenAI O1-modellen.
Hvordan adskiller OpenAI O1 sig fra tidligere modeller?
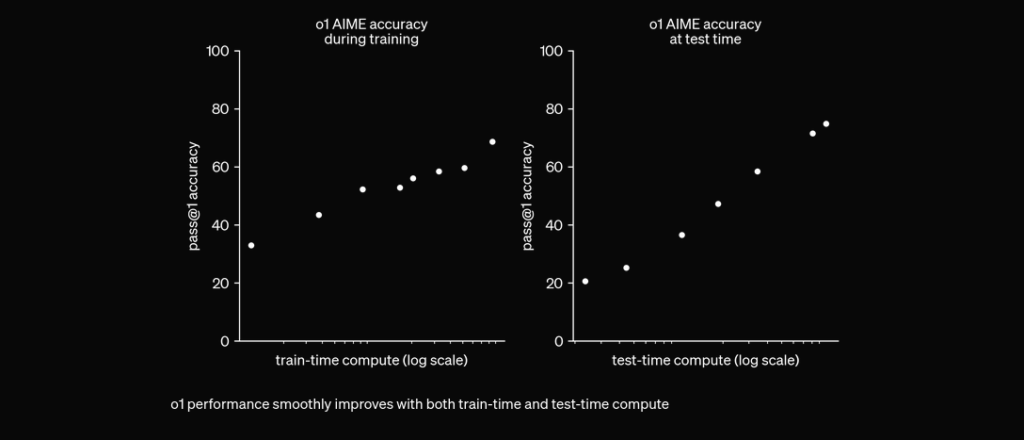
Storskala forstærkningslæring
O1-modellen udnytter storskala forstærkningslæringsalgoritmer under træningsprocessen. Dette giver modellen mulighed for at udvikle en robust “Chain of Thought”, så den kan tænke dybere og mere strategisk over problemer. Ved kontinuerligt at optimere sine ræsonnementveje gennem forstærkningslæring forbedrer O1-modellen markant sin evne til at analysere og løse komplekse opgaver effektivt.
Integration af Chain of Thought
Tidligere har chain of thought vist sig at være en nyttig prompt engineering-mekanisme til at få LLM’en til at “tænke” selv og besvare komplekse spørgsmål i en trinvis plan. Med O1-modeller kommer dette trin ud-af-boksen og er indbygget i modellen ved inferenstid, hvilket gør det nyttigt til matematiske og kodningsmæssige problemløsningsopgaver.
O1 er trænet med RL til at “tænke”, før den svarer via en privat chain of thought. Jo længere den tænker, jo bedre klarer den sig på ræsonnementsopgaver. Dette åbner en ny dimension for skalering. Vi er ikke længere begrænset af pretraining. Vi kan nu også skalere inferensberegning. pic.twitter.com/niqRO9hhg1 — Noam Brown (@polynoamial) 12. september 2024
Overlegen benchmark-performance
I omfattende evalueringer har O1-modellen vist bemærkelsesværdig ydeevne på tværs af forskellige benchmarks:
AIME (American Invitational Mathematics Examination): Løser 83% af opgaverne korrekt, en markant forbedring i forhold til GPT-4o’s 13%.
GPQA (Ekspertniveau-test i naturvidenskab): Overgår PhD-niveau eksperter og er den første AI-model, der overgår mennesker på dette benchmark.
MMLU (Multi-Task Language Understanding): Udmærker sig i 54 ud af 57 underkategorier og opnår 78,2% performance med visuel perception aktiveret.
Kodningskonkurrencer: Opnår høje placeringer på platforme som Codeforces og overgår 93% af menneskelige deltagere.
OpenAI O1 vs OpenAI GPT4o i RAG-flow
For at teste præstationsnøjagtigheden af OpenAI O1 og GPT4o, oprettede vi to identiske flows, men med to forskellige LLMs. Vi sammenligner modellernes spørgsmål-svar-kapacitet på to kilder indekseret fra den tekniske rapport om OpenAI O1.
Først laver vi et simpelt RAG-flow i FlowHunt. Det består af Chat Input, Document Retriever (henter relevante dokumenter), Prompt, Generator og Chat Output. LLM OpenAI-komponenten tilføjes for at angive modellen (ellers bruges GPT4o som standard).
Her er svaret fra GPT4o:
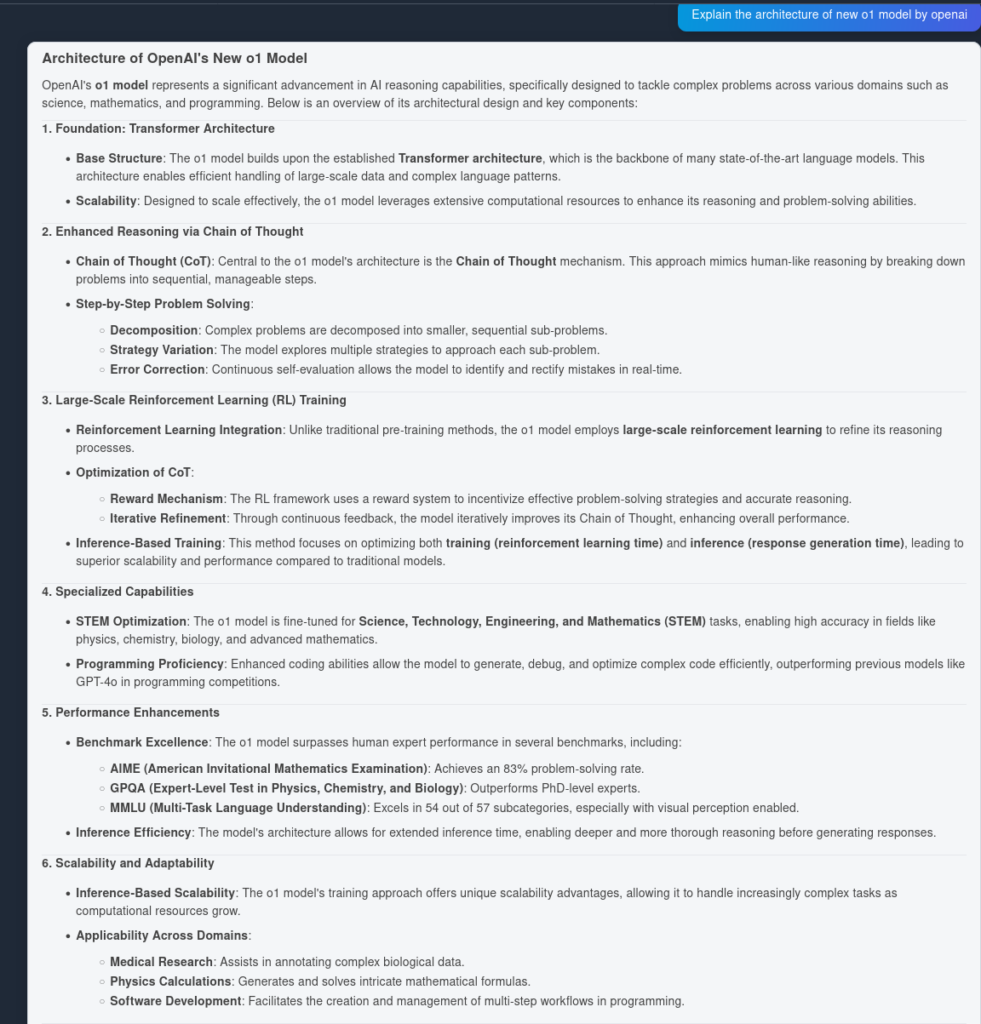
Og her er resultatet fra OpenAI O1:
Som det ses, fangede OpenAI O1 flere arkitektoniske fordele fra selve artiklen—6 punkter mod 4. Derudover laver O1 logiske implikationer ud fra hvert punkt, hvilket beriger dokumentet med flere indsigter i, hvorfor den arkitektoniske ændring er nyttig.
Klar til at vokse din virksomhed?
Start din gratis prøveperiode i dag og se resultater inden for få dage.
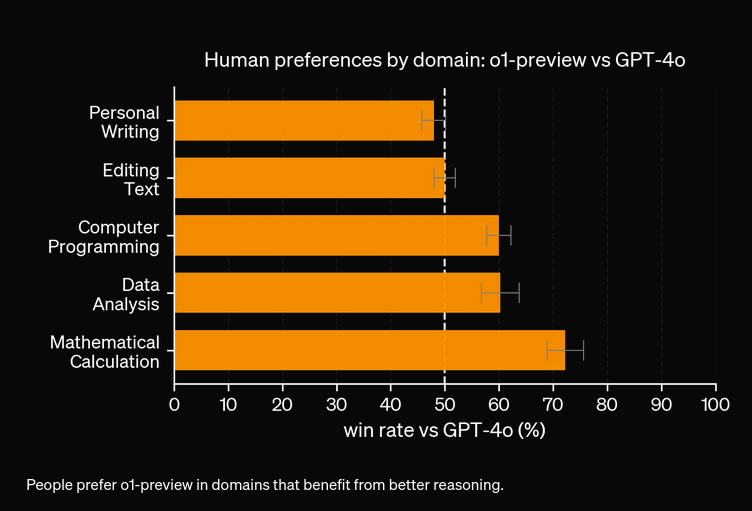
Ud fra vores eksperimenter vil O1-modellen koste mere for øget nøjagtighed. Den nye model har 3 typer tokens: Prompt Token, Completion Token og Reason Token (en nyligt tilføjet type token), hvilket potentielt gør den dyrere. I de fleste tilfælde leverer OpenAI O1 svar, der virker mere hjælpsomme, hvis de er sandhedsbaserede. Dog er der tilfælde, hvor GPT4o overgår OpenAI O1—nogle opgaver kræver simpelthen ikke ræsonnement.
Ofte stillede spørgsmål
OpenAI O1 bruger storskala forstærkningslæring og integrerer 'chain of thought'-ræsonnement ved inferenstid, hvilket muliggør dybere og mere strategisk problemløsning end GPT4o.
Ja, O1 opnår højere resultater i benchmarks som AIME (83% vs. GPT4o's 13%), GPQA (overgår PhD-niveau eksperter), og MMLU, hvor den klarer sig bedst i 54 ud af 57 kategorier.
Ikke altid. Selvom O1 er stærk i opgaver med meget ræsonnement, kan GPT4o overgå den i mere simple brugstilfælde, der ikke kræver avanceret ræsonnement.
O1 introducerer en ny 'Reason'-token ud over Prompt og Completion tokens, hvilket muliggør mere sofistikeret ræsonnement, men potentielt øger driftsomkostningen.
Du kan bruge platforme som FlowHunt til at bygge RAG-flows og AI-agenter med OpenAI O1 til opgaver, der kræver avanceret ræsonnement og præcis dokumenthentning.
Yasha er en talentfuld softwareudvikler med speciale i Python, Java og maskinlæring. Yasha skriver tekniske artikler om AI, prompt engineering og udvikling af chatbots.
Yasha Boroumand
CTO, FlowHunt
Byg avancerede RAG-flows med FlowHunt
Prøv FlowHunt for at udnytte de nyeste LLMs som OpenAI O1 og GPT4o til overlegent ræsonnement og retrieval-augmented generation.
GPT-5 udgivelsesdato OpenAI: Seneste opdateringer, o1-modeller og hvad der venter forude
Udforsk den officielle udgivelsesdato for GPT-5 fra OpenAI, hvordan den bygger videre på o1 og GPT-4o, og hvad næste generation af AI-modeller betyder for udvik...
Hvordan LLM'er ræsonnerer som AI-agenter — Sammenligning model for model (Claude, GPT, Gemini, Llama, Mistral, Grok, DeepSeek)
Hvordan ræsonnerer store sprogmodeller egentlig inde i en AI-agent? Praktisk sammenligning model for model: Claude, GPT og o-serien, Gemini, Llama, Mistral, Gro...
Hvordan OpenAI's o1 Preview mestrer komplekse skriveopgaver
Opdag hvordan OpenAI’s o1 Preview overgår GPT-4 ved at mestre komplekse skriveopgaver gennem intern planlægning, kreativitet og overholdelse af begrænsninger, h...
3 min læsning
OpenAI
o1 Preview
+5
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.