RAG avec les LLM de raisonnement : OpenAI O1 vs OpenAI GPT4o
OpenAI O1 exploite l’apprentissage par renforcement et le raisonnement natif en chaîne de pensée pour dépasser GPT4o dans les tâches RAG complexes, bien qu’à un coût plus élevé.
OpenAI O1
GPT4o
RAG
Reasoning
AI Agents
Benchmarks
OpenAI vient de sortir un nouveau modèle appelé OpenAI O1
de la série O1. Le principal changement architectural de ces modèles est la capacité de réfléchir avant de répondre à une requête utilisateur. Dans ce blog, nous allons approfondir les principaux changements d’OpenAI O1, les nouveaux paradigmes utilisés par ces modèles, et comment ce modèle peut significativement augmenter la précision du RAG. Nous comparerons un flux RAG simple utilisant OpenAI GPT4o et le modèle OpenAI O1.
En quoi OpenAI O1 est-il différent des modèles précédents ?
Apprentissage par renforcement à grande échelle
Le modèle O1 exploite des algorithmes d’apprentissage par renforcement à grande échelle durant son processus d’entraînement. Cela permet au modèle de développer une solide « chaîne de pensée », lui permettant de réfléchir plus profondément et de façon stratégique aux problèmes. En optimisant continuellement ses chemins de raisonnement via l’apprentissage par renforcement, le modèle O1 améliore significativement sa capacité à analyser et résoudre efficacement des tâches complexes.
Intégration de la chaîne de pensée
Précédemment, la chaîne de pensée s’est révélée un mécanisme utile d’ingénierie de prompts pour amener le LLM à « réfléchir » par lui-même et à répondre à des questions complexes par un plan étape par étape. Avec les modèles O1, cette étape est intégrée nativement dans le modèle lors de l’inférence, ce qui le rend utile pour les tâches de résolution de problèmes mathématiques et de codage.
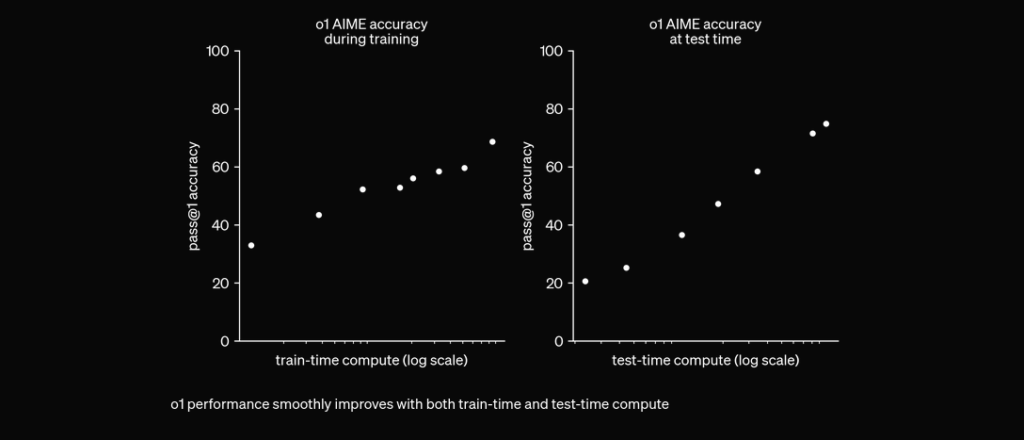
O1 est entraîné avec RL pour « réfléchir » avant de répondre via une chaîne de pensée privée. Plus il réfléchit longtemps, meilleurs sont ses résultats sur les tâches de raisonnement. Cela ouvre une nouvelle dimension pour l’évolutivité. Nous ne sommes plus limités par le pré-entraînement. Nous pouvons désormais augmenter la puissance de calcul à l’inférence aussi. pic.twitter.com/niqRO9hhg1 — Noam Brown (@polynoamial) 12 septembre 2024
Performance supérieure aux benchmarks
Lors d’évaluations approfondies, le modèle O1 a démontré des performances remarquables sur différents benchmarks :
AIME (American Invitational Mathematics Examination) : Résout 83 % des problèmes correctement, une nette amélioration par rapport aux 13 % de GPT-4o.
GPQA (test de niveau expert en sciences) : Dépasse les experts de niveau doctorat, marquant le premier modèle IA à surpasser les humains sur ce benchmark.
MMLU (compréhension linguistique multi-tâches) : Excelle dans 54 des 57 sous-catégories, atteignant 78,2 % de performance avec la perception visuelle activée.
Compétitions de codage : Obtient de bons classements sur des plateformes comme Codeforces, surpassant 93 % des concurrents humains.
OpenAI O1 vs OpenAI GPT4o dans un flux RAG
Pour tester la précision des performances d’OpenAI O1 et GPT4o, nous avons créé deux flux identiques, mais avec deux LLM différents. Nous comparerons la capacité de réponse aux questions de ces modèles sur deux sources indexées concernant le rapport technique d’OpenAI O1.
D’abord, nous allons créer un flux RAG simple dans FlowHunt. Il se compose d’une entrée de chat, d’un récupérateur de documents (qui va chercher les documents pertinents), d’un prompt, d’un générateur et d’une sortie de chat. Le composant LLM OpenAI est ajouté pour spécifier le modèle (sinon, GPT4o est utilisé par défaut).
Voici la réponse de GPT4o :
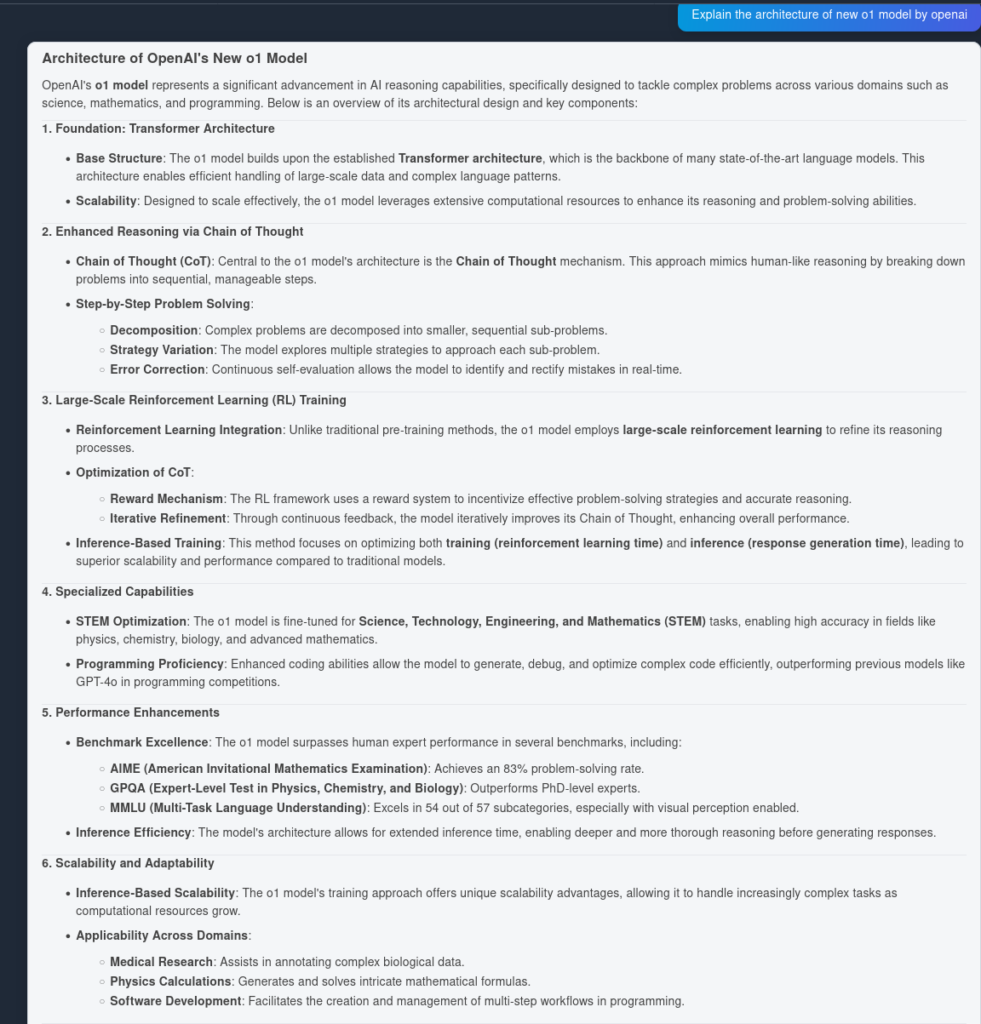
Et voici le résultat d’OpenAI O1 :
Comme vous pouvez le voir, OpenAI O1 a extrait davantage d’avantages architecturaux de l’article lui-même — 6 points contre 4. De plus, O1 effectue des implications logiques à partir de chaque point, enrichissant le document avec plus d’informations sur l’utilité du changement architectural.
Prêt à développer votre entreprise?
Commencez votre essai gratuit aujourd'hui et voyez les résultats en quelques jours.
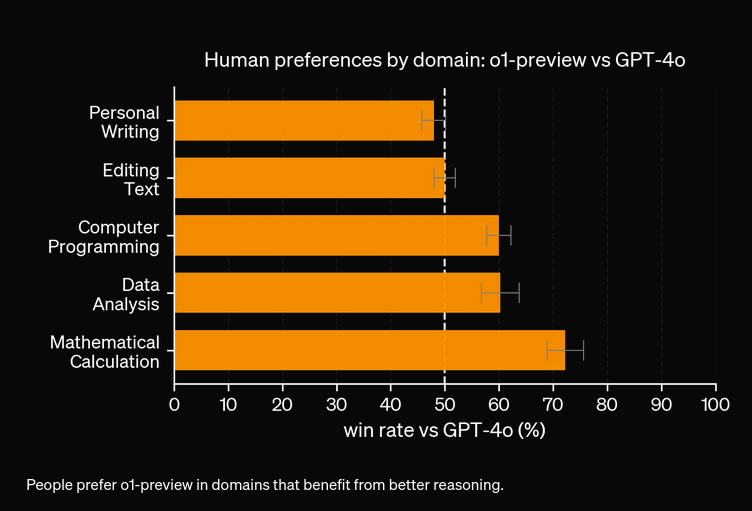
D’après nos expériences, le modèle O1 coûtera plus cher pour une précision accrue. Le nouveau modèle dispose de 3 types de jetons : Jeton Prompt, Jeton Completion et Jeton Reason (un nouveau type de jeton ajouté), ce qui le rend potentiellement plus onéreux. Dans la plupart des cas, OpenAI O1 fournit des réponses qui semblent plus utiles si elles sont fondées sur la vérité. Cependant, il existe quelques cas où GPT4o surpasse OpenAI O1 — certaines tâches n’ont tout simplement pas besoin de raisonnement.
Questions fréquemment posées
OpenAI O1 utilise un apprentissage par renforcement à grande échelle et intègre le raisonnement en chaîne de pensée lors de l'inférence, permettant une résolution de problèmes plus profonde et stratégique que GPT4o.
Oui, O1 obtient de meilleurs scores dans des benchmarks comme AIME (83 % contre 13 % pour GPT4o), GPQA (dépassant des experts de niveau doctorat) et MMLU, excellant dans 54 des 57 catégories.
Pas toujours. Bien que O1 excelle dans les tâches nécessitant beaucoup de raisonnement, GPT4o peut le surpasser dans des cas d'utilisation plus simples qui ne requièrent pas de raisonnement avancé.
O1 introduit un nouveau jeton 'Reason' en plus des jetons Prompt et Completion, permettant un raisonnement plus sophistiqué mais augmentant potentiellement le coût opérationnel.
Vous pouvez utiliser des plateformes comme FlowHunt pour construire des flux RAG et des agents IA avec OpenAI O1 pour des tâches nécessitant un raisonnement avancé et une récupération précise de documents.
Yasha est un développeur logiciel talentueux, spécialisé en Python, Java et en apprentissage automatique. Yasha écrit des articles techniques sur l'IA, l'ingénierie des prompts et le développement de chatbots.
Yasha Boroumand
CTO, FlowHunt
Construisez des flux RAG avancés avec FlowHunt
Essayez FlowHunt pour exploiter les derniers LLM comme OpenAI O1 et GPT4o pour un raisonnement supérieur et une génération augmentée par la recherche.
Date de sortie de GPT-5 OpenAI : dernières actualités, modèles o1 et perspectives
Découvrez la date officielle de sortie de GPT-5 par OpenAI, comment il s’appuie sur o1 et GPT-4o, et ce que la nouvelle génération de modèles d’IA signifie pour...
Comment l’aperçu o1 d’OpenAI maîtrise les consignes d’écriture complexes
Découvrez comment l’aperçu o1 d’OpenAI surpasse GPT-4 en maîtrisant des consignes d’écriture complexes grâce à la planification interne, la créativité et le res...
Comment les LLM raisonnent comme agents IA — Comparatif modèle par modèle (Claude, GPT, Gemini, Llama, Mistral, Grok, DeepSeek)
Comment les grands modèles de langage raisonnent-ils vraiment dans un agent IA ? Comparatif pratique modèle par modèle : Claude, GPT et série o, Gemini, Llama, ...
13 min de lecture
AI Agents
LLM
+9
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.