RAG z rozumującymi LLM-ami: OpenAI O1 vs OpenAI GPT4o
OpenAI O1 wykorzystuje uczenie przez wzmacnianie oraz natywne rozumowanie chain of thought, by przewyższyć GPT4o w złożonych zadaniach RAG, choć przy wyższych kosztach.
OpenAI właśnie wypuściło nowy model o nazwie OpenAI O1
z serii modeli O1. Najważniejszą zmianą architektoniczną w tych modelach jest zdolność do „myślenia” przed udzieleniem odpowiedzi na zapytanie użytkownika. W tym wpisie blogowym przyjrzymy się bliżej kluczowym zmianom w OpenAI O1, nowym paradygmatom stosowanym przez te modele i temu, jak ten model może znacząco zwiększyć dokładność RAG. Porównamy także prosty przepływ RAG z użyciem OpenAI GPT4o oraz modelu OpenAI O1.
Czym różni się OpenAI O1 od poprzednich modeli?
Uczenie przez wzmacnianie na dużą skalę
Model O1 wykorzystuje algorytmy uczenia przez wzmacnianie na dużą skalę podczas procesu treningu. Pozwala mu to rozwijać solidny „łańcuch rozumowania” (Chain of Thought), co umożliwia głębsze i bardziej strategiczne podejście do rozwiązywania problemów. Przez ciągłą optymalizację ścieżek rozumowania dzięki uczeniu przez wzmacnianie, model O1 znacząco poprawia swoje możliwości analizy i rozwiązywania złożonych zadań.
Integracja chain of thought
Dotychczas chain of thought sprawdzał się jako technika inżynierii promptów, która pozwalała LLM-om „myśleć” samodzielnie i rozwiązywać złożone pytania krok po kroku. W modelach O1 ten krok jest natywnie zintegrowany i domyślnie dostępny już na etapie inferencji, co czyni go szczególnie przydatnym przy zadaniach matematycznych oraz programistycznych.
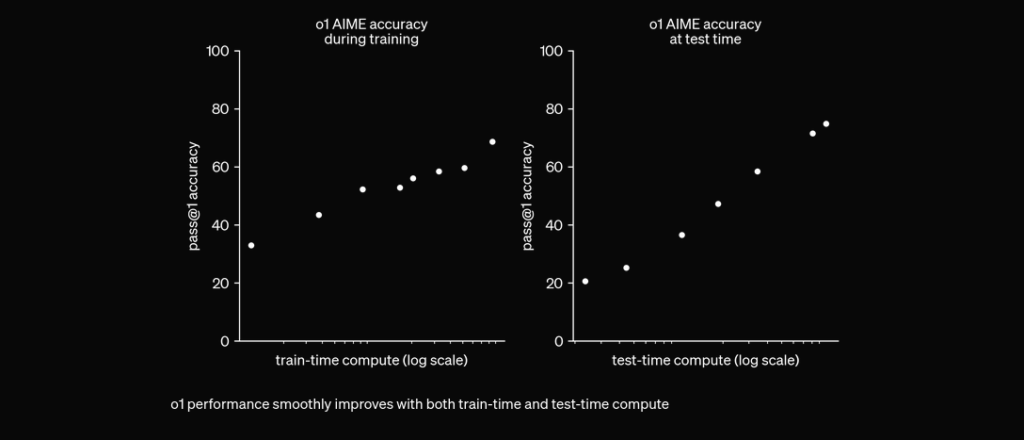
O1 jest trenowany z RL, by „myśleć” przed odpowiedzią poprzez prywatny chain of thought. Im dłużej myśli, tym lepiej radzi sobie w zadaniach rozumowania. To otwiera nowy wymiar skalowania. Nie ogranicza nas już pretrening. Możemy skalować także moc obliczeniową inferencji. pic.twitter.com/niqRO9hhg1 — Noam Brown (@polynoamial) 12 września 2024
Przewaga w benchmarkach
W szeroko zakrojonych testach model O1 wykazał się znakomitymi wynikami w różnych benchmarkach:
AIME (American Invitational Mathematics Examination): Rozwiązuje poprawnie 83% zadań, co stanowi ogromny postęp względem 13% dla GPT-4o.
GPQA (Test ekspercki z nauk ścisłych): Przewyższa ekspertów z doktoratem, jako pierwszy model AI pokonując ludzi w tym benchmarku.
MMLU (Multi-Task Language Understanding): Przoduje w 54 z 57 podkategorii, osiągając 78,2% skuteczności z aktywną percepcją wizualną.
Konkursy programistyczne: Osiąga wysokie pozycje na platformach takich jak Codeforces, przewyższając 93% ludzkich uczestników.
OpenAI O1 vs OpenAI GPT4o w przepływie RAG
Aby przetestować dokładność działania OpenAI O1 i GPT4o, stworzyliśmy dwa identyczne przepływy z różnymi LLM-ami. Porównamy możliwości odpowiadania na pytania przez oba modele na podstawie dwóch źródeł dotyczących raportu technicznego OpenAI O1.
Najpierw tworzymy prosty przepływ RAG w FlowHunt. Składa się on z wejścia czatu, wyszukiwarki dokumentów (pobierającej odpowiednie dokumenty), promptu, generatora i wyjścia czatu. Dodano komponent LLM OpenAI, by określić model (domyślnie używany jest GPT4o).
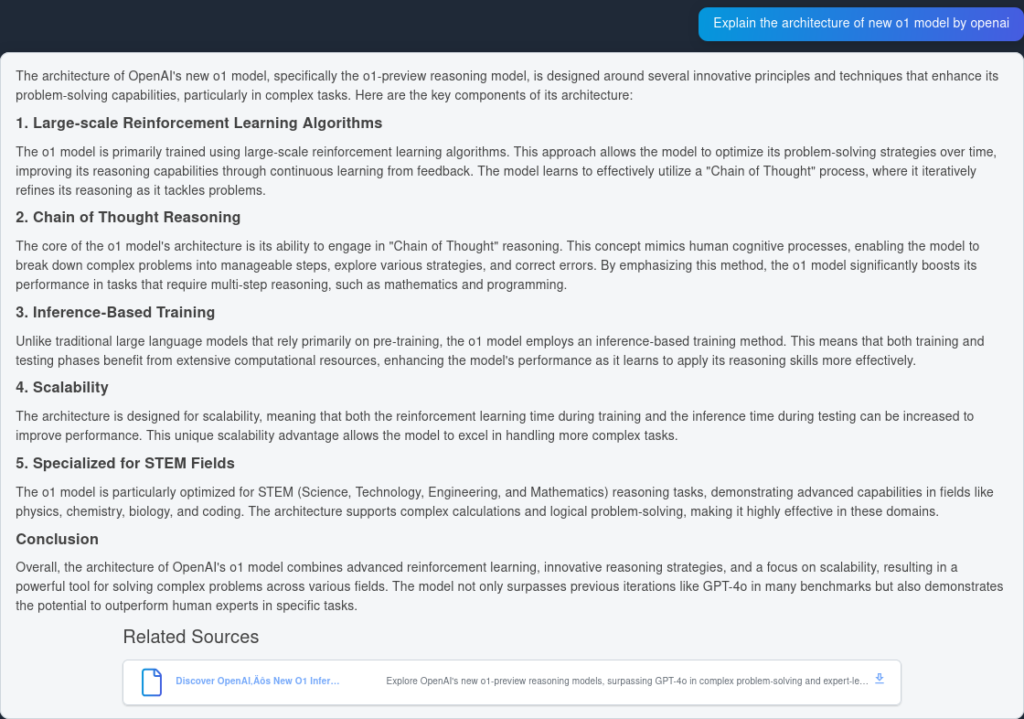
Oto odpowiedź z GPT4o:
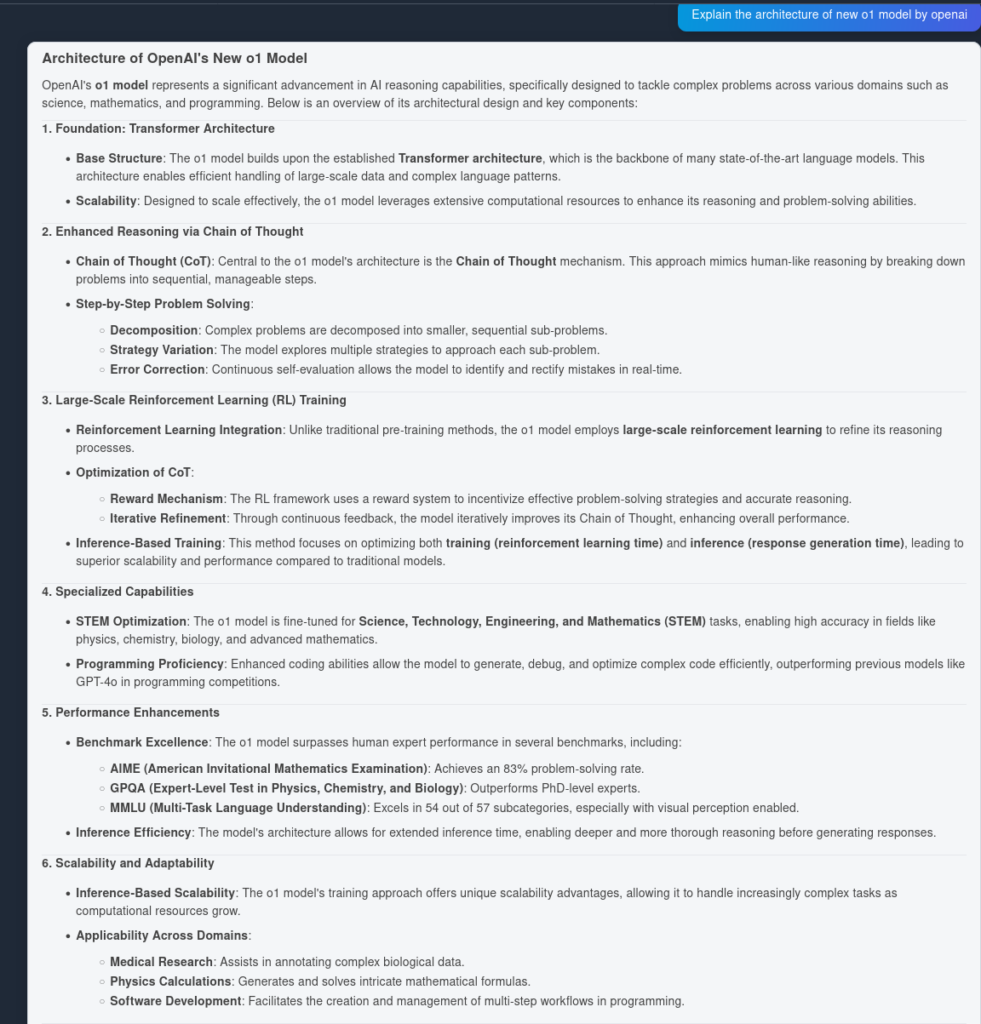
A tutaj rezultat z OpenAI O1:
Jak widać, OpenAI O1 wychwycił więcej zalet architektonicznych z samego artykułu—6 punktów zamiast 4. Dodatkowo O1 wyciąga logiczne implikacje z każdego z punktów, wzbogacając dokument o dodatkowe spostrzeżenia dotyczące powodów, dla których dana zmiana architektoniczna jest użyteczna.
Gotowy na rozwój swojej firmy?
Rozpocznij bezpłatny okres próbny już dziś i zobacz rezultaty w ciągu kilku dni.
Z naszych eksperymentów wynika, że O1 będzie droższy, ale oferuje wyższą dokładność. Nowy model ma 3 typy tokenów: Prompt Token, Completion Token oraz Reason Token (nowo wprowadzony typ tokena), co może generować wyższe koszty. W większości przypadków OpenAI O1 udziela odpowiedzi, które wydają się bardziej pomocne i bliższe prawdzie. Zdarzają się jednak sytuacje, gdy GPT4o przewyższa OpenAI O1—niektóre zadania po prostu nie wymagają rozumowania.
Najczęściej zadawane pytania
OpenAI O1 wykorzystuje uczenie przez wzmacnianie na dużą skalę i integruje rozumowanie chain of thought już na etapie inferencji, co pozwala na głębsze i bardziej strategiczne rozwiązywanie problemów niż GPT4o.
Tak, O1 osiąga wyższe wyniki w benchmarkach takich jak AIME (83% vs. 13% dla GPT4o), GPQA (przewyższając ekspertów z doktoratem) i MMLU, przodując w 54 z 57 kategorii.
Nie zawsze. O1 wyróżnia się przy zadaniach wymagających rozumowania, ale GPT4o może być lepszy przy prostszych zastosowaniach, które nie wymagają zaawansowanego rozumowania.
O1 wprowadza nowy token 'Reason' oprócz Prompt i Completion, umożliwiając bardziej zaawansowane rozumowanie, ale potencjalnie zwiększając koszty operacyjne.
Możesz użyć platform takich jak FlowHunt do budowy przepływów RAG i agentów AI z OpenAI O1 do zadań wymagających zaawansowanego rozumowania i precyzyjnego wyszukiwania dokumentów.
Yasha jest utalentowanym programistą specjalizującym się w Pythonie, Javie i uczeniu maszynowym. Yasha pisze artykuły techniczne o AI, inżynierii promptów i tworzeniu chatbotów.
Yasha Boroumand
CTO, FlowHunt
Buduj zaawansowane przepływy RAG z FlowHunt
Wypróbuj FlowHunt, aby wykorzystać najnowsze LLM-y, takie jak OpenAI O1 i GPT4o do lepszego rozumowania i generowania z rozszerzonym wyszukiwaniem.
Data premiery GPT-5 OpenAI: Najnowsze aktualizacje, modele o1 i co dalej
Poznaj oficjalną datę premiery GPT-5 od OpenAI, dowiedz się, jak rozwija modele o1 i GPT-4o oraz co nowa generacja modeli AI oznacza dla deweloperów i firm.
Jak OpenAI o1 Preview opanowuje złożone polecenia pisarskie
Dowiedz się, jak o1 Preview firmy OpenAI przewyższa GPT-4, opanowując złożone polecenia pisarskie dzięki wewnętrznemu planowaniu, kreatywności i przestrzeganiu ...
3 min czytania
OpenAI
o1 Preview
+5
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.