
OpenAI O3 Mini vs DeepSeek voor Agentisch Gebruik
Vergelijk OpenAI O3 Mini en DeepSeek op het gebied van redeneervermogen, schaakstrategie taken en agentisch gebruik van tools. Zie welke AI uitblinkt in nauwkeu...
10 min lezen
AI Models
OpenAI
+5

OpenAI O1 benut reinforcement learning en native chain of thought-redenering om GPT4o te overtreffen bij complexe RAG-taken, zij het tegen hogere kosten.
OpenAI heeft zojuist een nieuw model uitgebracht genaamd OpenAI O1 uit de O1-serie modellen. De belangrijkste architecturale verandering in deze modellen is het vermogen om na te denken voordat een gebruikersvraag wordt beantwoord. In deze blog duiken we diep in de belangrijkste veranderingen in OpenAI O1, de nieuwe paradigma’s die deze modellen gebruiken en hoe dit model de RAG-nauwkeurigheid aanzienlijk kan verhogen. We vergelijken een eenvoudige RAG-flow met het OpenAI GPT4o- en OpenAI O1-model.
Het O1-model maakt gebruik van grootschalige reinforcement learning-algoritmes tijdens het trainingsproces. Hierdoor kan het model een robuuste “Chain of Thought” ontwikkelen, waardoor het dieper en strategischer over problemen nadenkt. Door voortdurend zijn redeneerwegen te optimaliseren via reinforcement learning, verbetert het O1-model zijn vermogen om complexe taken efficiënt te analyseren en op te lossen aanzienlijk.
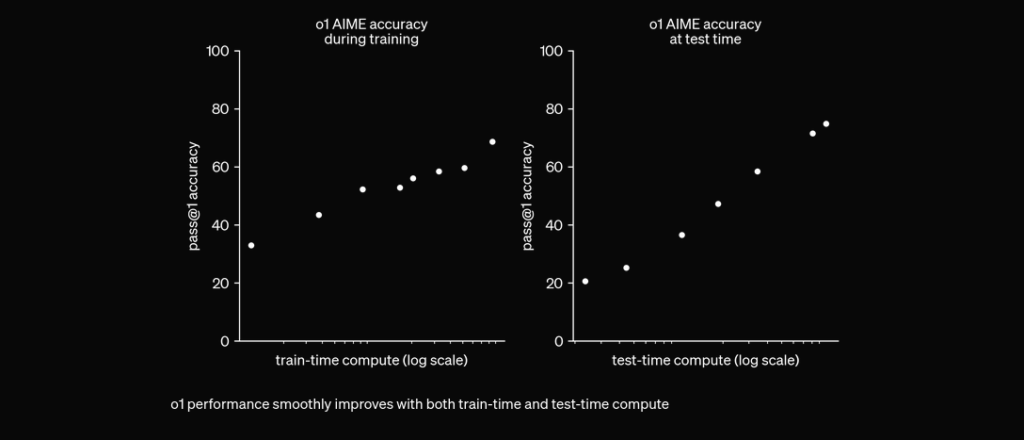
Voorheen bleek chain of thought een nuttig prompt engineering-mechanisme om LLMs zelfstandig te laten “nadenken” en complexe vragen in een stapsgewijs plan te beantwoorden. Met O1-modellen is deze stap standaard aanwezig en native geïntegreerd in het model tijdens inferentie, waardoor het erg bruikbaar is voor wiskundige en programmeeroplossingen.
O1 is getraind met RL om te “nadenken” voordat het reageert via een privé chain of thought. Hoe langer het nadenkt, hoe beter het presteert op redeneertaken. Dit opent een nieuwe dimensie voor schaalbaarheid. We zijn niet langer beperkt door pretraining. We kunnen nu ook inference compute opschalen. pic.twitter.com/niqRO9hhg1
— Noam Brown (@polynoamial) 12 september 2024
In uitgebreide evaluaties heeft het O1-model opmerkelijke prestaties laten zien op verschillende benchmarks:
Om de prestatie en nauwkeurigheid van OpenAI O1 en GPT4o te testen, hebben we twee identieke flows gecreëerd, maar met twee verschillende LLMs. We vergelijken het vraag-en-antwoordvermogen van de modellen op twee bronnen die zijn geïndexeerd over het technische rapport van OpenAI O1.
Eerst maken we een eenvoudige RAG-flow in FlowHunt. Deze bestaat uit Chat Input, Document Retriever (haalt relevante documenten op), Prompt, Generator en Chat Output. Het LLM OpenAI-component wordt toegevoegd om het model te specificeren (anders wordt standaard GPT4o gebruikt).
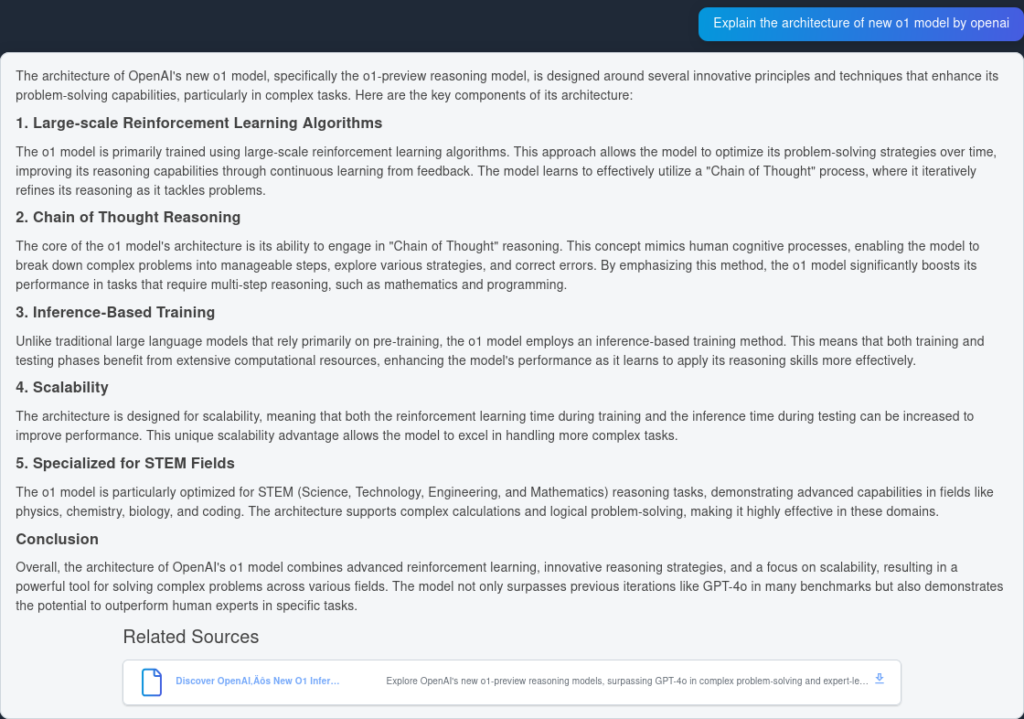
Hier is het antwoord van GPT4o:
En hier is het resultaat van OpenAI O1:
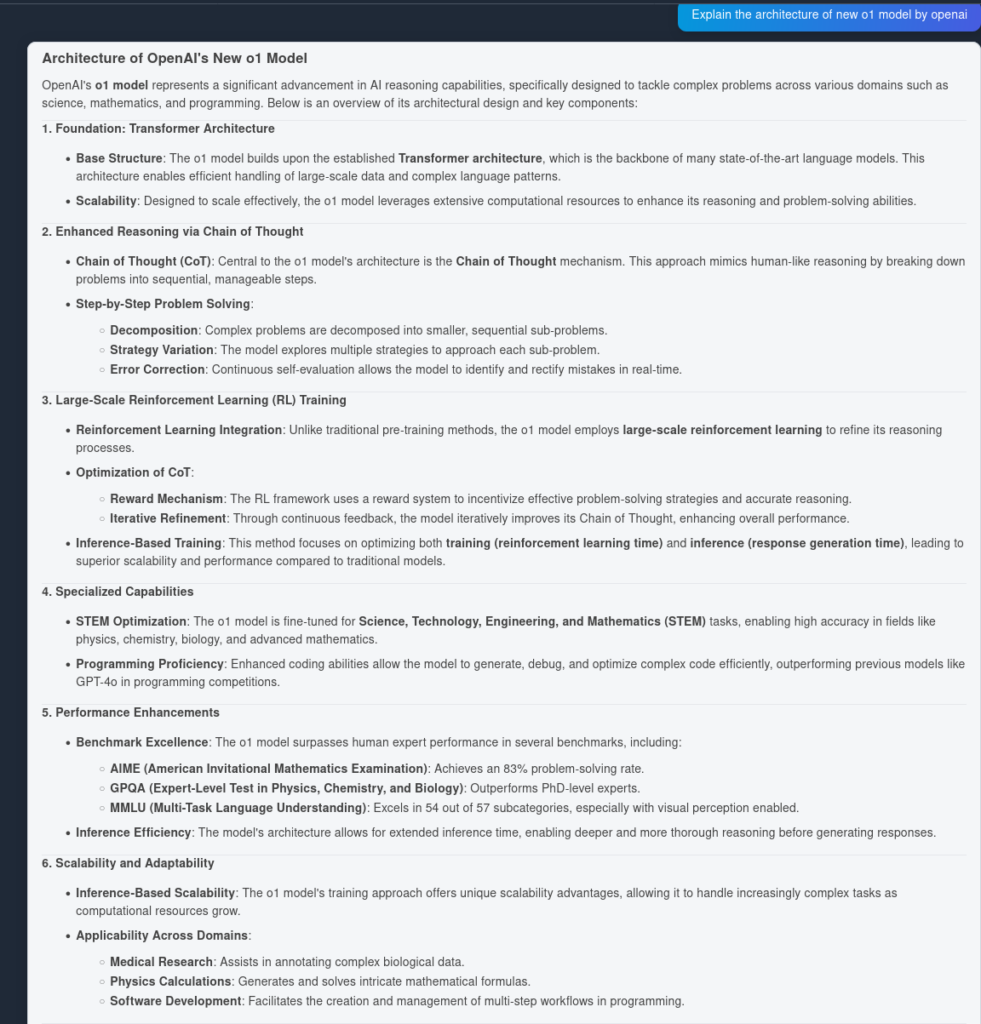
Zoals je ziet, heeft OpenAI O1 meer architecturale voordelen uit het artikel zelf gehaald—6 punten tegenover 4. Daarnaast maakt O1 logische implicaties van elk punt, waardoor het document wordt verrijkt met meer inzichten over waarom de architecturale wijziging nuttig is.
Start vandaag uw gratis proefperiode en zie binnen enkele dagen resultaten.
Uit onze experimenten blijkt dat het O1-model meer zal kosten voor een hogere nauwkeurigheid. Het nieuwe model heeft 3 soorten tokens: Prompt Token, Completion Token en Reason Token (een nieuw toegevoegd type token), wat het mogelijk duurder maakt. In de meeste gevallen geeft OpenAI O1 antwoorden die nuttiger lijken als ze op waarheid zijn gebaseerd. Toch zijn er enkele gevallen waarin GPT4o beter presteert dan OpenAI O1—sommige taken hebben simpelweg geen redenering nodig.
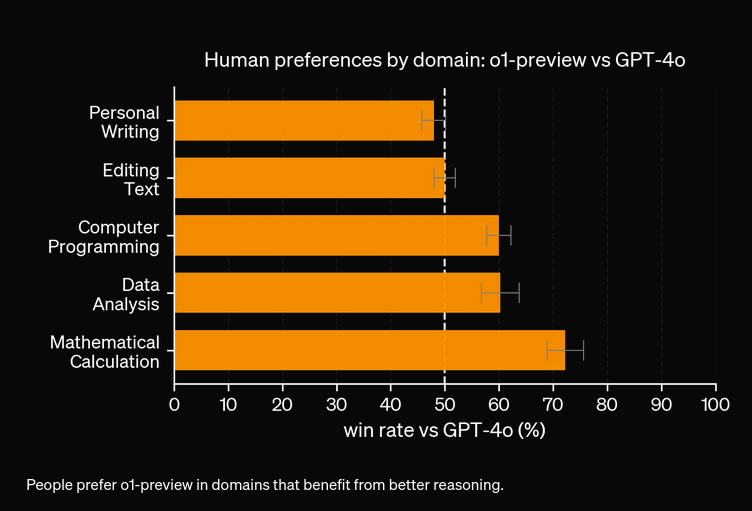
OpenAI O1 gebruikt grootschalige reinforcement learning en integreert chain of thought-redenering tijdens inferentie, waardoor dieper en strategischer probleemoplossen mogelijk wordt dan bij GPT4o.
Ja, O1 behaalt hogere scores in benchmarks zoals AIME (83% vs. GPT4o's 13%), GPQA (overtreft PhD-experts) en MMLU, en blinkt uit in 54 van de 57 categorieën.
Niet altijd. Hoewel O1 uitblinkt in taken met veel redeneren, kan GPT4o het beter doen in eenvoudigere toepassingen die geen geavanceerd redeneren vereisen.
O1 introduceert een nieuw 'Reason'-token naast Prompt- en Completion-tokens, waardoor geavanceerder redeneren mogelijk is, maar de operationele kosten mogelijk stijgen.
Je kunt platforms zoals FlowHunt gebruiken om RAG-flows en AI-agents te bouwen met OpenAI O1 voor taken die geavanceerd redeneren en nauwkeurige documentopvraging vereisen.
Yasha is een getalenteerde softwareontwikkelaar die gespecialiseerd is in Python, Java en machine learning. Yasha schrijft technische artikelen over AI, prompt engineering en chatbotontwikkeling.

Probeer FlowHunt om de nieuwste LLMs zoals OpenAI O1 en GPT4o te benutten voor superieur redeneren en retrieval-augmented generation.
Vergelijk OpenAI O3 Mini en DeepSeek op het gebied van redeneervermogen, schaakstrategie taken en agentisch gebruik van tools. Zie welke AI uitblinkt in nauwkeu...

FlowHunt v2.19.14 brengt OpenAI’s GPT-4.1 modellen, 9 nieuwe beeldgeneratiemodellen van Stable Diffusion, Google en Ideogram, plus HubSpot-integratie voor gestr...

Ontdek de geavanceerde mogelijkheden van de GPT-o1 Preview AI Agent. Deze diepgaande verkenning laat zien hoe deze verder gaat dan tekstgeneratie, met zijn rede...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.