

2026年版 AIウェブスクレイパーおすすめ10選:ランキングとレビュー
2026年のベストAIウェブスクレイパー10選。抽出精度・使いやすさ・アンチボット対策・価格でランキング。ユースケースに最適なAIスクレイピングツールを見つけましょう。...
2 分で読める
Web Scraping
AI Tools
+2
Apifyは利用可能な最も強力なウェブスクレイピングおよび自動化プラットフォームの1つですが、開発者向けに構築されており、Actorシステムの習得が必要で、大量のスクレイピングでは費用がすぐにかさみます。よりシンプル、より安価、またはAIワークフローに適したものをお探しなら、強力な代替品があります。
Apifyはクラウドベースのウェブスクレイピングおよびブラウザ自動化プラットフォームです。その中核となる単位は「Actor」 — Apifyのクラウドインフラストラクチャで実行される再利用可能で共有可能なスクレイピングまたは自動化スクリプトです。ユーザーはApify SDKを使用してNode.jsでカスタムActorを構築するか、一般的なスクレイピングタスク(Amazon製品データ、Google Mapsリスト、LinkedInプロフィール、ソーシャルメディアコンテンツ)向けにApify Storeから事前構築されたActorを使用できます。
Apifyはウェブスクレイピングのインフラストラクチャの課題を処理します:ヘッドレスブラウザによるJavaScriptレンダリング、IPブロックを回避するためのプロキシローテーション、CAPTCHA処理、スケジューリング、結果の保存。これにより、ローカルでスクレイパーを実行するよりも大幅に強力になります。
トレードオフ:ApifyはカスタムActorを構築するために開発者のスキルが必要であり、その価格は計算時間に応じてスケールし(継続的なスクレイピングでは高額になる可能性があります)、Actorパラダイムには学習曲線があります。
| ツール | 最適な用途 | 無料ティア | 開始価格 | ノーコード | AIネイティブ |
|---|---|---|---|---|---|
| FlowHunt | AI統合抽出 | ✅ | 使用量ベース | ✅ | ✅ |
| Apify | カスタム開発者スクレイパー | ✅ | $49/月 | ❌ | 部分的 |
| Browse AI | ノーコードサイトスクレイピング | ✅ | $48/月 | ✅ | 部分的 |
| Firecrawl | LLM/AIデータ準備 | ✅ | $16/月 | 部分的 | ✅ |
| Octoparse | ビジュアルなポイントアンドクリックスクレイピング | ✅ | $75/月 | ✅ | ❌ |
| ScraperAPI | APIベースのJSレンダリング | ✅ | $49/月 | ❌ | ❌ |
| Bright Data | エンタープライズ規模の抽出 | ❌ | カスタム | ❌ | 部分的 |
| PhantomBuster | LinkedIn/ソーシャル抽出 | ✅ | $56/月 | ✅ | ❌ |
| Bardeen | ブラウザタスク自動化 | ✅ | $10/月 | ✅ | ✅ |
FlowHuntはApifyとは異なる方法でウェブデータ抽出にアプローチします:スタンドアロンのスクレイパーを構築するのではなく、より大きな自動化ワークフローの一部としてウェブを閲覧するAIエージェントを構築します。エージェントはURLに移動し、ページコンテンツを読み取り、特定の情報を抽出し、そのデータをすぐに次のステップで使用できます — CRMに供給したり、要約を生成したり、アウトリーチシーケンスをトリガーしたりします。
これは数百万ページをバッチスクレイピングするのとは根本的に異なるユースケースです — FlowHuntはビジネスプロセスの一部としてのインテリジェントでターゲットを絞った抽出に優れています。
Apifyに対する主な利点:
最適なユースケース:
最適ではない用途: 一度に数千ページの大量バッチスクレイピング(その場合はScraperAPIまたはBright Dataを使用してください)。
価格: 無料ティアあり。使用量ベースの価格が実際のワークフロー実行に応じてスケールします。
Browse AIは非開発者にとって最も簡単なApify代替品です。スクレイピングしたいウェブサイトに移動し、抽出したいデータをクリックしてBrowse AIに示すと、スケジュールに沿って抽出を繰り返す「ロボット」を構築します。
ダイナミックなJavaScriptレンダリングサイト、ページネーション、ログイン保護されたページをコードなしで処理します。
価格:
主な機能:
長所: 真のノーコード — ポイントアンドクリックインターフェースで数分でセットアップ;JavaScript負荷の高いサイトをうまく処理;スケジュール監視と変更検出が組み込まれている;一般的なサイト向けの事前構築されたロボット
短所: 複雑なカスタム抽出ロジックの柔軟性が限られる;非常に大量のスクレイピングではApifyよりもスケールが劣る;頻繁に変更されるサイトでは実行ごとの価格が予測しにくい
最適な用途: コードを書いたりインフラストラクチャを管理したりせずに、特定のウェブサイトから定期的な抽出を必要とする非技術ユーザー。
最新のヒント、トレンド、お得な情報を無料で入手。
Firecrawlは特定のユースケース向けに目的別設計されています:ウェブサイト全体をLLMが読み取れるクリーンなマークダウンに変換することです。ウェブサイトをクロールし、JavaScriptをレンダリングし、ページネーションを処理し、構造化されたクリーンなテキストを出力します — RAG(検索拡張生成)ナレッジベースの構築やウェブコンテンツをAIエージェントに供給するのに最適です。
価格:
主な機能:
長所: クリーンなLLM対応マークダウン出力 — HTMLのクリーンアップ不要;サイトマップサポート付きの完全なウェブサイトクローリング;ダイナミックなJavaScriptサイトのマッピングとクロール;シンプルなAPI — 数分で統合
短所: 構造化データ(価格、製品仕様)の抽出には不向き — 構造化レコードではなくテキストを出力;ビジュアルビルダーなし — 開発者APIのみ;スケジュール監視ユースケース向けには設計されていない
最適な用途: クリーンで構造化されたウェブコンテンツを入力として必要とするAIエージェント、RAGパイプライン、またはLLMアプリケーションを構築する開発者。
Octoparseは、スクレイパーをビジュアルに構築するためのポイントアンドクリックインターフェースを備えたデスクトップアプリケーションを提供し、その後スケジュールに沿ってクラウドで実行します。コードなしで、最も一般的なスクレイピングシナリオ(ページネーション、無限スクロール、ドロップダウンナビゲーション)を処理します。
価格:
主な機能:
長所: ビジュアルワークフロービルダー — コード不要;スケジューリングとIPローテーションを備えたクラウド実行;複雑なページネーションとマルチページフローの処理;Excel、CSV、Google Sheets、データベースへのエクスポート
短所: 同等の機能に対して代替品よりも高価;デスクトップクライアント(Windows/Mac)はブラウザベースのツールに比べて摩擦が増える;スケジュールバッチ実行に比べてリアルタイム抽出には不向き
最適な用途: 複雑またはページネーションされたウェブサイトから信頼性の高いスケジュールデータ抽出を必要とする非技術アナリストおよびオペレーションチーム。
ScraperAPIは、大規模なウェブスクレイピングの最も難しい部分を処理するAPIサービスです:JavaScriptレンダリング、CAPTCHA解決、自動プロキシローテーション。開発者はURLをScraperAPIに送信し、クリーンなHTMLを取得します — その間のすべてを処理します。
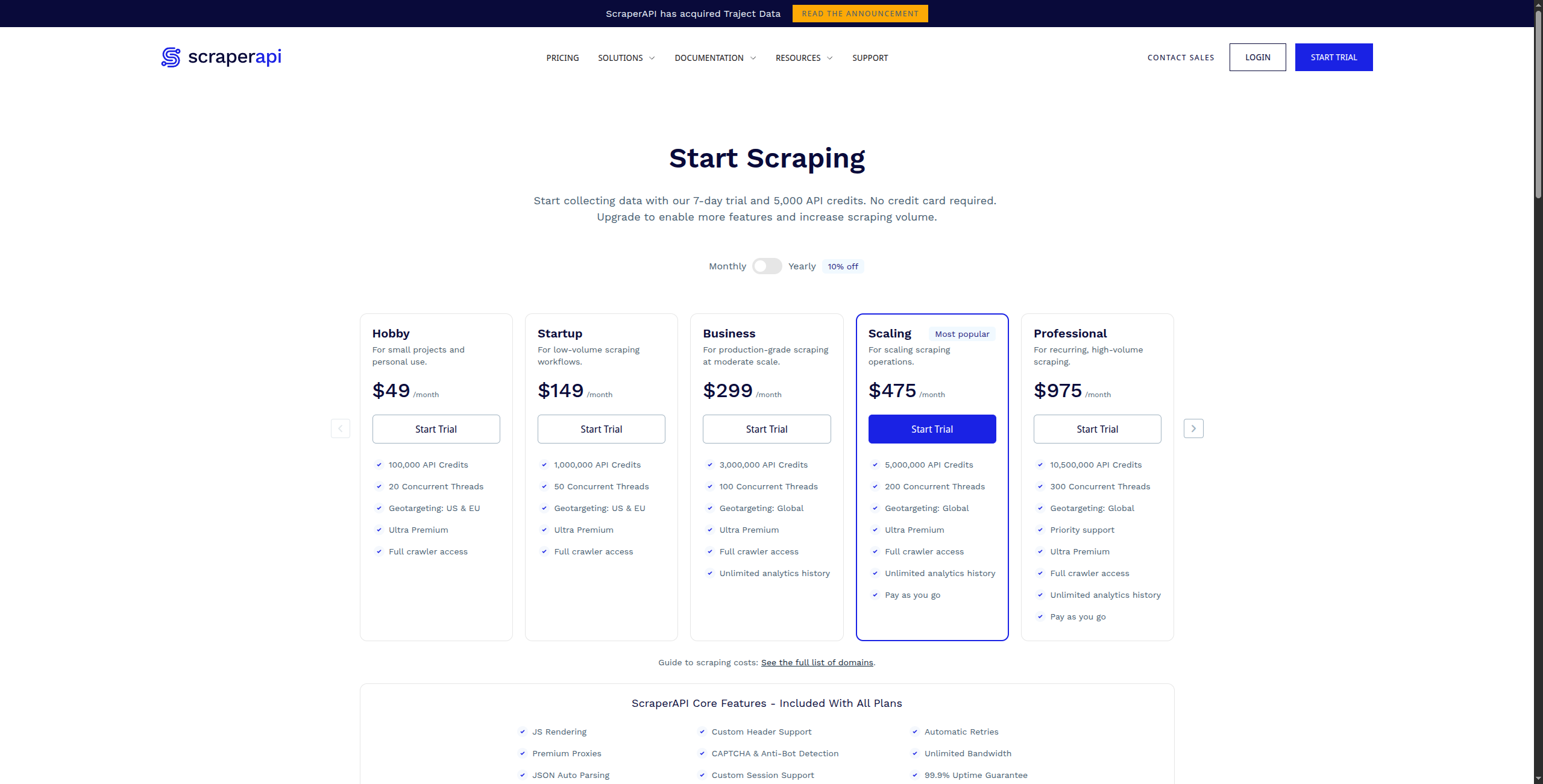
価格:
主な機能:
長所: シンプルなAPI統合 — 1つの関数呼び出しで複雑なスクレイピングインフラストラクチャを置き換える;CAPTCHA、ジオターゲティング、デバイスエミュレーションの処理;一般的なサイト(Amazon、Google、eBay)向けの構造化データエンドポイント;大量のシンプルなスクレイピングではApifyよりも低コスト
短所: HTMLを返す — データを自分で解析および抽出する必要がある;ビジュアルビルダーやノーコードインターフェースなし;スケジューリングや監視なし — 単なるレンダリング/プロキシレイヤー
最適な用途: 独自のプロキシプールを管理せずに信頼性が高くスケーラブルなプロキシとレンダリングインフラストラクチャを必要とするスクレイパーを構築する開発者。
Bright Dataは世界最大級のプロキシネットワーク(7,200万以上のIP)を運営し、完全なウェブデータ製品スイートを提供します:プロキシネットワーク、スクレイピングAPI、ブラウザ自動化、数百の人気ウェブサイト向けの事前構築されたデータセット。エンタープライズ規模のウェブデータニーズにおいては、比類なきものです。
価格:
主な機能:
長所: 世界最大のプロキシネットワーク — 高度なボット対策保護の回避に最適;一般的なユースケース(Amazon、LinkedIn、ソーシャルメディア)向けの事前構築されたデータセット;カスタムスクレイパー構築のためのWeb Scraper IDE;エンタープライズコンプライアンスとデータ品質保証
短所: 複雑な価格設定 — 異なるコストモデルを持つ複数の製品;小規模または中規模のスクレイピングニーズには過剰;うまく実装するには技術リソースが必要
最適な用途: 大量のスクレイピングニーズ、厳格なコンプライアンス要件、または高度なボット対策回避要件を持つエンタープライズチーム。
PhantomBusterは、ソーシャルプラットフォーム(LinkedIn、Twitter/X、Instagram、Facebook、Google Mapsなど)でのデータ抽出とアクションの自動化に特化しています。汎用ウェブスクレイパーではありませんが、そのニッチで優れています。
価格:
主な機能:
長所: 一般的なソーシャルスクレイピングシナリオ向けの事前構築されたPhantom;スクレイピングスクリプトなしのLinkedInリード抽出;データ抽出と並行した自動化(プロフィール訪問、接続リクエスト);ほとんどのユースケース向けのノーコードインターフェース
短所: プラットフォーム固有 — 任意のウェブサイトスクレイピングには役立たない;自動化によるLinkedIn TOSコンプライアンスリスク;下位プランでの実行時間制限が低い
最適な用途: リード生成とアウトリーチのためにLinkedInおよびソーシャルメディアデータを抽出して行動する必要がある営業チームおよびグロースマーケター。
Bardeenは、ブラウザアクションを記録および再生し、表示しているページからデータを抽出し、抽出されたデータを100以上のアプリと統合するChrome拡張機能です。完全に無人のスクレイピングではなく、半自動化されたオンデマンド抽出に最適です。
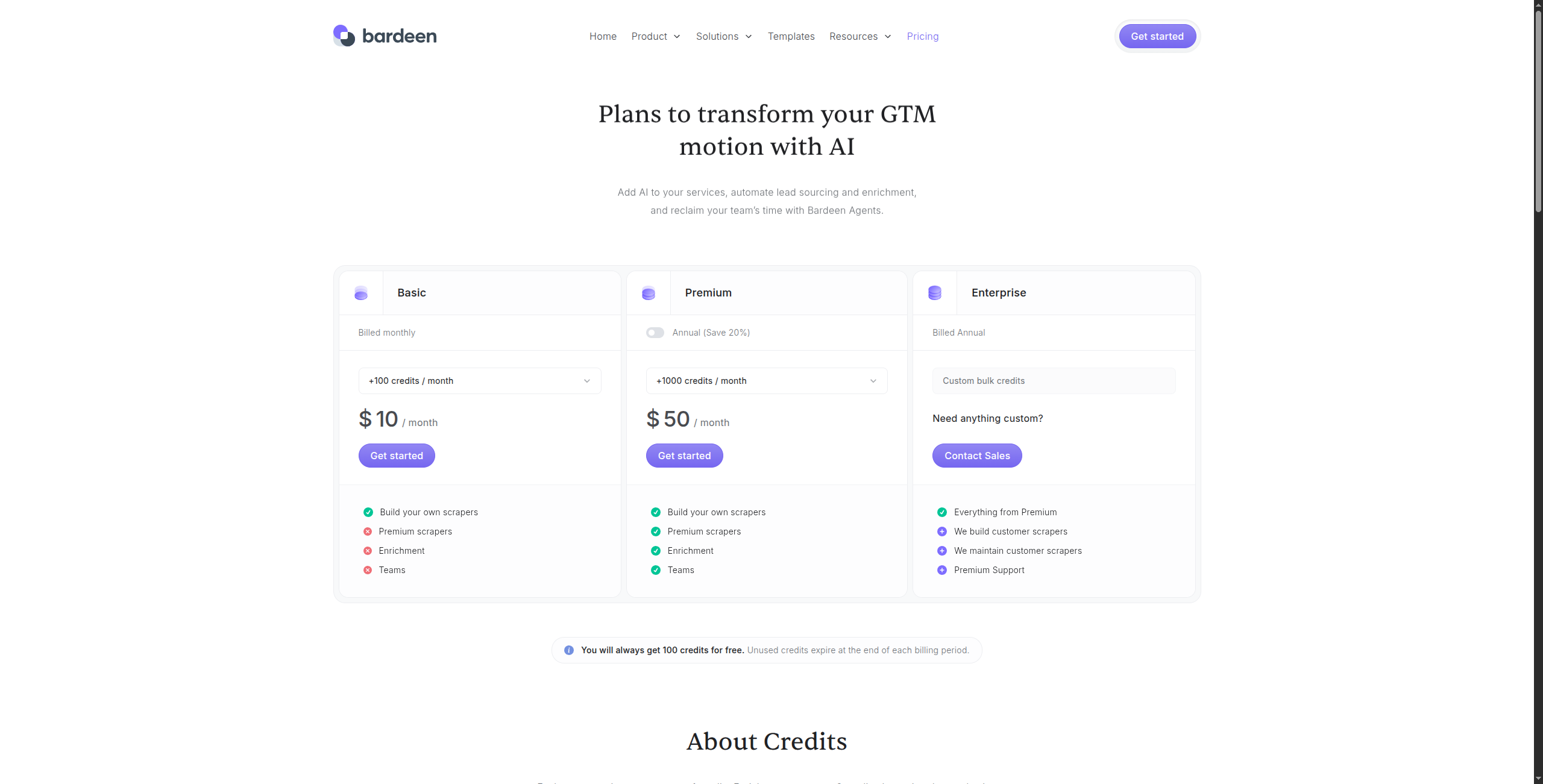
価格:
主な機能:
長所: ノーコードChrome拡張機能 — セットアップ不要;CSSセレクタではなく記述によってデータを抽出するAI Magic Actions;Notion、Airtable、HubSpot、Salesforceとの強力な統合;個人の生産性とリサーチワークフローに適している
短所: Chromeを開いておく必要がある — 完全に無人の自動化ではない;サーバーサイドの大量スクレイピングには不向き;ログインユーザーがブラウザでアクセスできるものに限定される
最適な用途: コードを書かずに繰り返しのブラウザリサーチとデータ収集タスクを自動化する必要がある個人貢献者および小規模チーム。
ほとんどのビジネスユースケース — 競合他社の監視、リードデータの抽出、見込み客のリサーチ — において、FlowHuntのAIネイティブなアプローチは、セットアップの速さとワークフロー統合の両方でApifyの開発者中心のモデルに勝ります。大量の技術的なスクレイピングプロジェクトには、ScraperAPIとBright Dataが適切なツールです。
アルシアはFlowHuntのAIワークフローエンジニアです。コンピュータサイエンスのバックグラウンドとAIへの情熱を持ち、AIツールを日常業務に統合して効率的なワークフローを作り出し、生産性と創造性を高めることを専門としています。

2026年のベストAIウェブスクレイパー10選。抽出精度・使いやすさ・アンチボット対策・価格でランキング。ユースケースに最適なAIスクレイピングツールを見つけましょう。...

Browse AIの代替ツールをお探しですか?AIを活用したスクレイパーから完全自動化プラットフォームまで、8つのWebスクレイピングおよびデータ抽出ツールを比較して、最適なツールを見つけました。...

ランキングとレビュー:2026年の最高のAIアプリビルダー12選。AIエージェント構築、プロンプトからのフルスタックアプリ開発、社内ツール作成まで、最適なプラットフォームが見つかります。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.