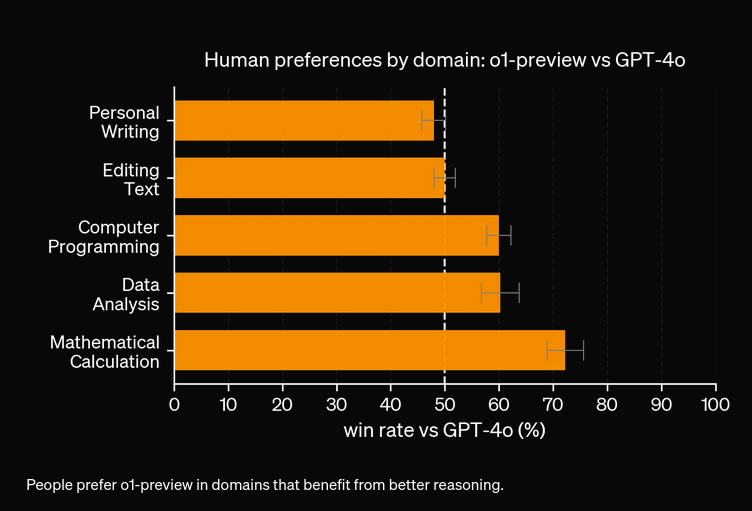
OpenAI 刚刚发布了名为 OpenAI O1 的新一代 O1 系列模型。这一系列模型的主要架构变革,是具备了在回答用户问题前“思考”的能力。本文将深入探讨 OpenAI O1 的关键变革、模型所采用的新范式,以及该模型如何显著提升 RAG 的准确率。我们还将对比使用 OpenAI GPT4o 和 OpenAI O1 的简单 RAG 流程。
OpenAI O1 与以往模型有何不同?
大规模强化学习
O1 模型在训练过程中采用了大规模强化学习算法。这使得模型能够发展出强大的“链式思考”能力,从而对问题进行更深入、更具策略性的思考。通过强化学习不断优化推理路径,O1 显著提升了解析和高效解决复杂任务的能力。
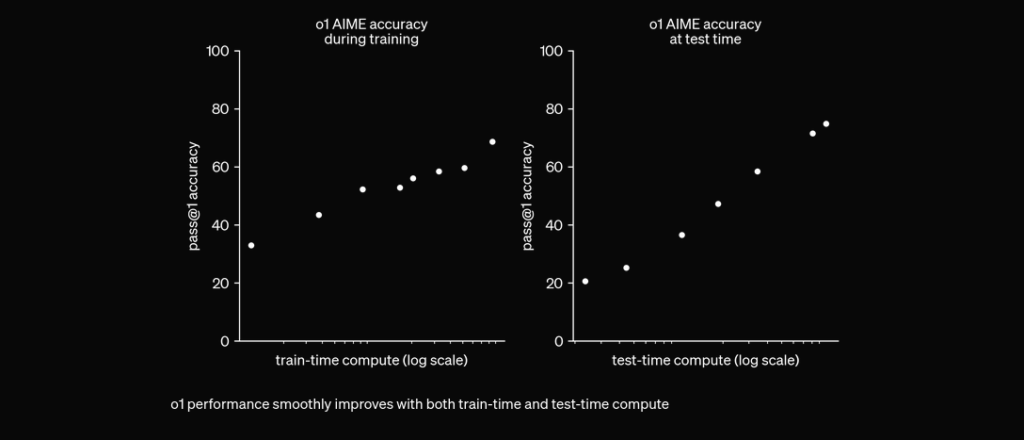
链式思考原生集成
以往,链式思考常作为提示工程手段,让大模型“自主思考”,以分步方式解答复杂问题。而 O1 模型将这一步骤内置,并在推理时原生集成,使其在数学与编程等问题求解任务中表现更为出色。
O1 通过强化学习训练,在回答前以私有链式思考“思考”。思考越久,推理任务表现越佳。这为模型扩展开启了新维度,不再受限于预训练,现在也能扩展推理算力。pic.twitter.com/niqRO9hhg1
— Noam Brown (@polynoamial) 2024年9月12日
卓越的基准测试表现
在大量评测中,O1 模型在多个基准测试中表现卓越:
- AIME(美国邀请数学考试): 正确解决 83% 的问题,远超 GPT-4o 的 13%。
- GPQA(科学领域专家级测试): 超越博士级专家,成为首个在该基准上超过人类的 AI 模型。
- MMLU(多任务语言理解): 57 个子类别中有 54 个表现优异,开启视觉感知后达到 78.2% 的成绩。
- 编程竞赛: 在 Codeforces 等平台排名靠前,超越 93% 的人类参赛者。
OpenAI O1 与 OpenAI GPT4o 在 RAG 流程中的对比
为测试 OpenAI O1 和 GPT4o 的性能准确性,我们分别用两个不同的大模型,构建了两条完全相同的流程。我们将对比两个模型在关于 OpenAI O1 技术报告的两个知识源上的问答能力。
首先,我们在 FlowHunt 中搭建了一个简单的 RAG 流程,包含:聊天输入、文档检索器(获取相关文档)、提示、生成器和聊天输出。再通过 LLM OpenAI 组件指定模型(否则默认用 GPT4o)。
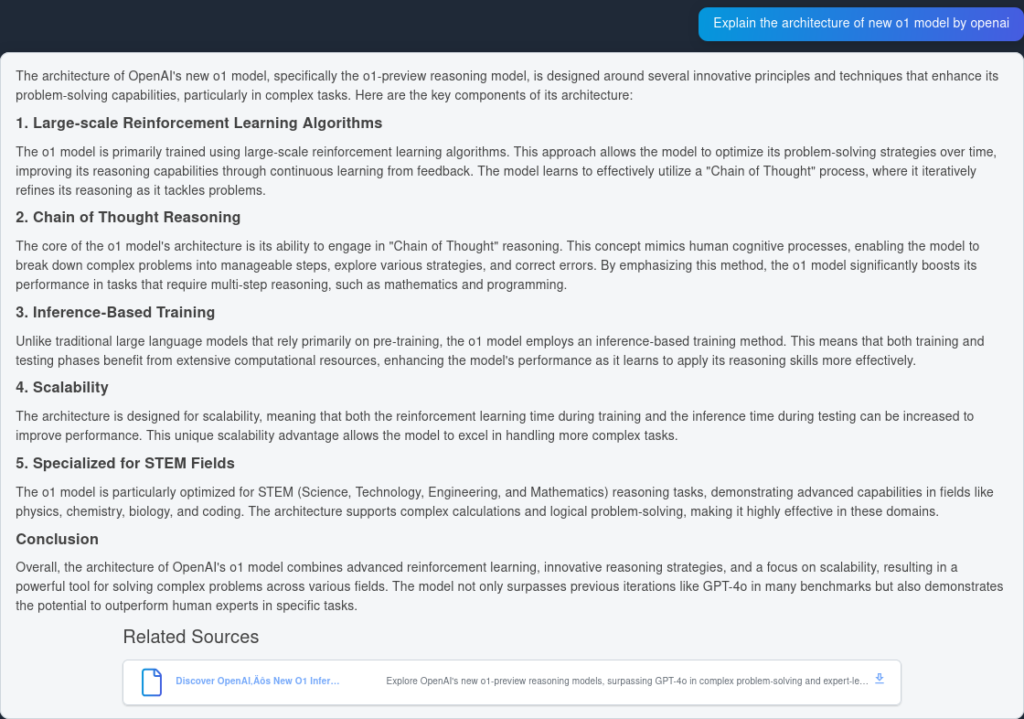
以下为 GPT4o 的回答:
以下为 OpenAI O1 的回答:
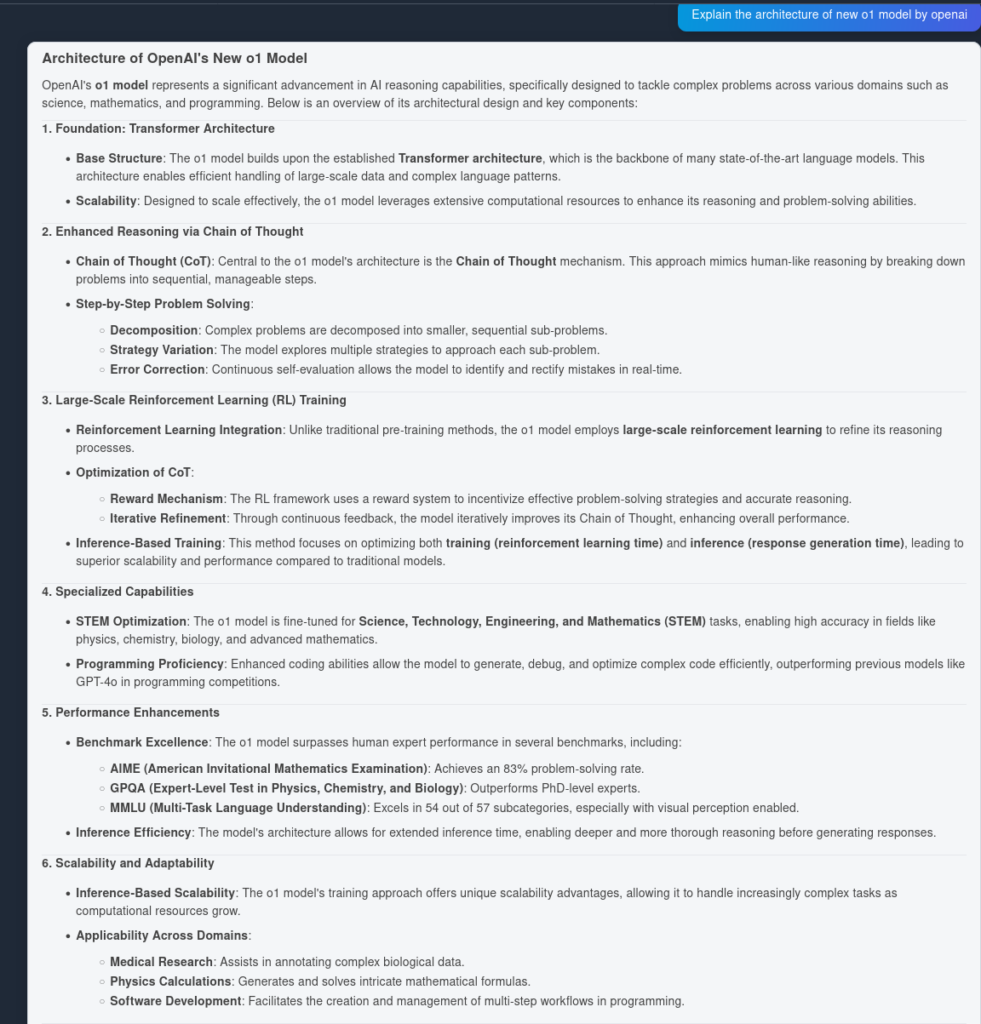
如上图所示,OpenAI O1 从原文中提取了更多架构优势——共计 6 点,而 GPT4o 仅为 4 点。此外,O1 还能针对每一点作出逻辑推断,进一步丰富了文档内容,阐明架构变更的意义。
OpenAI O1 值得使用吗?
从我们的实验来看,O1 模型为了更高的准确率,成本也会更高。新模型包含三种 token 类型:提示 Token(Prompt Token)、完成 Token(Completion Token) 和新增的 推理 Token(Reason Token),因此可能更为昂贵。大多数情况下,如果答案以事实为基础,OpenAI O1 会显得更有帮助。但也有部分场景,GPT4o 的表现优于 O1——有些任务本不需要推理。