AI-agentit
Opi rakentamaan, konfiguroimaan ja orkestroimaan AI-agentteja FlowHuntissa. Yksinkertaisista agenteista deep agenteihin ja täysiin tiimeihin, löydä kaikki tarvi...
3 min lukuaika
Agentit
Opi rakentamaan luotettavia tekoälyagentteja oikealla arkkitehtuurilla, työkaluintegraatioilla ja virheiden ehkäisyllä. Vertaile viitekehyksiä, malleja ja tosielämän esimerkkejä.
Tekoälyagentit eroavat perusteellisesti chatboteista. Chatbot odottaa käyttäjän syötettä ja vastaa. Agentti tavoittelee päämääriä autonomisesti kutsuen työkaluja, päätellen ongelmia ja toimien ilman ihmisen syötettä jokaisessa vaiheessa.
Tämä ero on tärkeä, koska agentit voivat automatisoida kokonaisia työnkulkuja. Liidien kvalifiointiagentti pisteyttää prospekteja, rikastaa niiden tietoja ja osoittaa ne myyjille — kaikki ilman ihmisen puuttumista. Sisällön triage-agentti luokittelee tukipyyntöjä, ohjaa ne asiantuntijoille ja eskaloi rajatapaukset ihmisille.
Tässä oppaassa opit arkkitehtuoimaan luotettavia agentteja, integroimaan ne liiketoimintajärjestelmiin, estämään yleisiä vikoja ja mittaamaan niiden vaikutusta. Käsittelemme todellisia malleja, joita käytetään tuotannossa yrityksissä, jotka automatisoivat liidien kvalifiointia, dokumenttien käsittelyä ja asiakastukea mittakaavassa.
Tekoälyagentti on ohjelmistojärjestelmä, joka:
Agentit ovat päämäärävetoisia. Määrittelet tavoitteen (“Pisteytä ja kvalifioi tämä liidi”), ja agentti selvittää, kuinka se saavutetaan.
User: "What's the status of my order?"
Chatbot: [Looks up order, responds]
User: "Can you cancel it?"
Chatbot: [Cancels order, responds]
Käyttäjä ohjaa jokaista vuorovaikutusta. Chatbot on tilaton — jokainen viesti on riippumaton.
Agent goal: "Qualify and score this lead"
1. Agent observes: [Lead data from CRM]
2. Agent reasons: "I need to enrich this data and score them"
3. Agent acts: Calls enrichment API
4. Agent observes: [Enriched data]
5. Agent reasons: "Score is 85, should assign to top sales rep"
6. Agent acts: Updates CRM, sends notification
7. Done. No human input required.
Agentti työskentelee määriteltyä päämäärää kohti tehden useita päätöksiä ja työkalukutsuja autonomisesti.
Manuaalinen liidien kvalifiointi: 5 minuuttia per liidi × 100 liidiä = 500 tuntia/kk. Kustannus: 10 000 $/kk (20 $/tunti).
Agenttivetoinen: 10 sekuntia per liidi × 100 liidiä = 16 tuntia/kk. Kustannus: 100 $ (agentin API-kutsut). Säästö: 99 %.
Agentit moninkertaistavat tiimisi kapasiteetin ilman uusia palkkauksia.
Monimutkaiset tehtävät vaativat useita askeleita:
Agentit hoitavat tämän päättelyn automaattisesti. Sinä määrittelet päämäärän; agentti pilkkoo sen askeleisiin.
Agentit ovat “käsiä”. Ne kutsuvat API:ja:
Yksittäinen agentti voi orkestroida 5–10 työkalukutsua työnkulun suorittamiseksi.
Agentit voivat parantua ajan myötä. Jos agentti luokittelee dokumentit väärin, annat palautetta. Agentti oppii ja säätää promptausstrategiaansa.
Jokaisen agentin ytimessä on silmukka:
┌─────────────────────────────────────────┐
│ START: Agent receives goal │
└────────────────┬────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ OBSERVE: Read input, tool results, │
│ memory, environment │
└────────────────┬────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ REASON: LLM decides next action │
│ (which tool to call, or done?) │
└────────────────┬────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ ACT: Execute tool call or complete │
│ task │
└────────────────┬────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ FEEDBACK: Evaluate result, update │
│ memory, check if goal met │
└────────────────┬────────────────────────┘
│
├─→ Goal not met? Loop back to OBSERVE
│
└─→ Goal met or max steps reached? DONE
Agentti lukee:
LLM vastaanottaa promptin kuten:
You are a lead qualification agent. Your goal is to score and qualify this lead.
Available tools:
1. enrich_lead(lead_id) - Get additional data about the lead
2. score_lead(lead_data) - Score based on criteria
3. assign_to_sales_rep(lead_id, rep_id) - Assign lead to a rep
4. send_notification(rep_id, message) - Notify rep
Current state:
- Lead ID: 12345
- Company: Acme Corp
- Revenue: Unknown (need to enrich)
- Status: Not scored yet
What should you do next?
LLM vastaa: “Minun pitäisi ensin rikastaa liidi saadakseni liikevaihtotiedot, sitten pisteyttää ja sitten osoittaa.”
Agentti suorittaa valitun työkalun:
result = enrich_lead(lead_id=12345)
# Returns: {'revenue': '$10M', 'industry': 'SaaS', 'employees': 150}
Agentti tarkistaa: Onnistuiko työkalukutsu? Edistikö se päämäärää? Päivitä muisti ja jatka silmukkaa.
Agentti toistaa havainnointi → päättely → toiminta → palaute kunnes:
Työkalut ovat funktioita, joita agentti voi kutsua. Määrittele ne selkeästi:
tools = [
{
"name": "enrich_lead",
"description": "Get additional company data about a lead (revenue, employees, industry)",
"parameters": {
"lead_id": {"type": "string", "description": "Unique identifier of the lead"}
}
},
{
"name": "score_lead",
"description": "Score a lead on a scale of 0-100 based on fit criteria",
"parameters": {
"lead_data": {"type": "object", "description": "Lead information including revenue, industry, etc."}
}
}
]
Selkeät kuvaukset auttavat LLM:ää valitsemaan oikean työkalun.
LLM vastaa työkalukutsulla:
{
"thought": "I need to enrich this lead to get revenue data",
"action": "enrich_lead",
"action_input": {"lead_id": "12345"}
}
Agenttisi viitekehys suorittaa työkalun ja välittää tuloksen takaisin LLM:lle.
Käsittele sekä onnistuminen että epäonnistuminen:
def execute_tool(tool_name, tool_input):
try:
if tool_name == "enrich_lead":
result = crm_api.enrich(tool_input['lead_id'])
return {"status": "success", "data": result}
except Exception as e:
return {"status": "error", "message": str(e)}
Jos työkalu epäonnistuu, agentin pitäisi kokeilla eri lähestymistapaa tai eskaloida ihmiselle.
Agentin työmuisti: nykyinen syöte, työkalujen tulokset, päättelyvaiheet. Yleensä tallennettu kontekstiikkunaan (promptiin).
Esimerkki: Liidien kvalifiointiagentti muistaa:
Pysyvä muisti: menneet päätökset, opitut kaavat, tietokanta.
Käyttötapaukset:
Toteuta vektoritietokannoilla (Pinecone, Weaviate) semanttista hakua varten.
LLM:illä on rajallinen kontekstiikkuna (4K–128K tokenia). Agentit eivät voi muistaa kaikkea. Strategioita:
Useimmille agenteille Claude tai avoimen lähdekoodin mallit riittävät ja ovat halvempia.
Esimerkki reflexion-promptista:
Agent: "I'll assign this lead to rep John."
Critic: "Wait, did you check if John is already at capacity?"
Agent: "Good point. Let me check John's workload first."
Valitse nopeus reaaliaikaan (asiakastuki). Valitse tarkkuus korkean panoksen tehtäviin (taloudelliset päätökset).
Aloita ilmainen kokeilujakso tänään ja näe tulokset muutamassa päivässä.
Reaktiiviset agentit tekevät yksittäisen päätöksen ja toimivat. Ei monivaiheista suunnittelua.
Input: "What's my account balance?"
→ Agent queries database
→ Agent responds with balance
Done.
def customer_service_agent(question):
# 1. Search knowledge base
articles = search_kb(question)
# 2. LLM picks best article
response = llm.complete(f"""
Question: {question}
Relevant articles: {articles}
Provide an answer based on these articles.
""")
# 3. Return response
return response
Viive: 1–3 sekuntia. Kustannus: 0,001–0,01 $ per kysely.
Suunnitteluagentit pilkkovat monimutkaiset päämäärät vaiheisiin.
Goal: "Qualify and assign this lead"
→ Agent plans: [enrich, score, assign, notify]
→ Agent executes each step
→ Agent verifies goal achieved
Done.
def lead_qualification_agent(lead_id):
lead = crm.get_lead(lead_id)
# Step 1: Enrich
enriched = enrich_lead(lead)
# Step 2: Score
score = score_lead(enriched)
# Step 3: Assign
best_rep = find_best_sales_rep(score)
crm.assign_lead(lead_id, best_rep)
# Step 4: Notify
send_slack(f"New qualified lead assigned to {best_rep}")
return {"lead_id": lead_id, "score": score, "assigned_to": best_rep}
Viive: 5–15 sekuntia. Kustannus: 0,02–0,05 $ per liidi.
Oppivat agentit paranevat palautteesta.
Initial: Agent classifies document as "Invoice" (60% confidence)
Human feedback: "Actually, it's a Receipt"
Agent learns: Adjust classification prompts
Next time: Same document classified as "Receipt" (90% confidence)
def recommendation_agent(user_id):
# Get user history
history = db.get_user_history(user_id)
# LLM recommends based on patterns
recommendation = llm.complete(f"""
User history: {history}
Based on past preferences, what should we recommend?
""")
# Show recommendation, collect feedback
feedback = user_feedback # thumbs up/down
# Store feedback for future recommendations
db.log_feedback(user_id, recommendation, feedback)
return recommendation
Ajan myötä suositukset paranevat agentin oppiessa käyttäjän mieltymyksiä.
Valvova agentti koordinoi asiantuntija-agentteja.
Supervisor: "Process this support ticket"
├─ Classifier agent: "This is a billing issue"
├─ Billing specialist agent: "Refund $50"
└─ Notification agent: "Send confirmation email"
def content_pipeline_agent(topic):
# Supervisor delegates
research = research_agent(topic)
draft = writer_agent(research)
edited = editor_agent(draft)
published = publisher_agent(edited)
return {"topic": topic, "status": "published"}
Jokainen asiantuntija-agentti on optimoitu tehtäväänsä. Valvoja orkestroi.
Kuinka kehittynyttä agentin ajattelu on. Yksinkertaiset agentit käyttävät chain-of-thoughtia. Monimutkaiset agentit käyttävät suunnittelua ja reflexionia.
Voitko helposti yhdistää API:ja, tietokantoja, CRM-järjestelmiä? Vai tarvitseeko mukautettua koodia?
Kuinka nopeasti kehittäjä saa toimivan agentin? Koodittomat alustat ovat nopeampia; Python-viitekehykset joustavampia.
Jotkin viitekehykset ovat avoimen lähdekoodin (ilmaisia). Toiset veloittavat API-kutsua tai tilausta kohti.
Mihin kukin työkalu on optimoitu?
| Työkalu | Viitekehystyyppi | Päättelykyky | Työkaluintegraatio | Oppimiskäyrä | Hinnoittelu | Parhaiten |
|---|---|---|---|---|---|---|
| n8n | Visuaalinen työnkulkurakentaja | Chain-of-thought | 500+ integraatiota | Matala | Ilmainen + maksullinen | Ei-tekniset käyttäjät, nopea käyttöönotto |
| CrewAI | Python-viitekehys | Suunnittelu + reflexion | Mukautetut työkalut (Python) | Keskitaso | Avoimen lähdekoodin | Kehittäjät, monimutkaiset agentit |
| Autogen | Python-viitekehys | Moniagenttipäättely | Mukautetut työkalut | Korkea | Avoimen lähdekoodin | Tutkimus, moniagenttijärjestelmät |
| LangGraph | Python-viitekehys | Suunnittelu + tilanhallinta | LangChain-ekosysteemi | Keskitaso | Avoimen lähdekoodin | Monimutkaiset työnkulut, tilanseuranta |
| FlowHunt | Natiivi alusta | Chain-of-thought + suunnittelu | Natiivit + API-integraatiot | Matala | Tilaus | Työnkulkuautomaatio, helppokäyttöisyys |
| Lindy.ai | Kooditon alusta | Chain-of-thought | 100+ integraatiota | Hyvin matala | Freemium | Ei-tekniset, nopeat agentit |
| Gumloop | Kooditon alusta | Chain-of-thought | 50+ integraatiota | Hyvin matala | Freemium | Yksinkertainen automaatio, mallit |
Keskeiset erot:
Saa uusimmat vinkit, trendit ja tarjoukset ilmaiseksi.
Ole tarkka. Huono: “Automatisoi liidien hallinta.” Hyvä: “Pisteytä liidit 0–100, rikasta yritystiedoilla, osoita myyjille kapasiteetin mukaan.”
Kompromissit:
Syötetiedot: liiditiedot, dokumentin teksti, asiakkaan kysymys, konteksti muistista.
Luettele API:t, tietokannat, palvelut, joita agentti kutsuu.
Esimerkki liidien kvalifiointiin:
Määrittele onnistumisehto. “Pysähdy, kun liidi on pisteytetty ja osoitettu.”
Määrittele myös maksimiaskeleet estääksesi äärettömät silmukat. “Pysähdy 10 askeleen jälkeen riippumatta.”
CrewAI-esimerkki:
from crewai import Agent, Task, Crew
# Define agents
enrichment_agent = Agent(
role="Data Enrichment Specialist",
goal="Enrich lead data with company information",
tools=[enrich_tool]
)
scoring_agent = Agent(
role="Lead Scoring Expert",
goal="Score leads based on fit criteria",
tools=[score_tool]
)
assignment_agent = Agent(
role="Sales Manager",
goal="Assign leads to best sales rep",
tools=[assign_tool, notify_tool]
)
# Define tasks
enrich_task = Task(
description="Enrich this lead: {lead_id}",
agent=enrichment_agent
)
score_task = Task(
description="Score the enriched lead",
agent=scoring_agent
)
assign_task = Task(
description="Assign lead to best rep and notify",
agent=assignment_agent
)
# Run crew
crew = Crew(agents=[enrichment_agent, scoring_agent, assignment_agent],
tasks=[enrich_task, score_task, assign_task])
result = crew.kickoff(inputs={"lead_id": "12345"})
def test_enrichment_tool():
result = enrich_tool("lead_123")
assert result['revenue'] is not None
assert result['employees'] is not None
def test_scoring_agent():
lead = {"company": "Acme", "revenue": "10M", "employees": 50}
score = score_agent(lead)
assert 0 <= score <= 100
def test_full_loop():
result = lead_qualification_agent("lead_123")
assert result['assigned_to'] is not None
assert result['score'] > 0
def lead_qualification_agent(lead_id):
"""
Autonomous agent that qualifies leads.
1. Fetches lead from CRM
2. Enriches with company data
3. Scores based on fit criteria
4. Assigns to best sales rep
5. Notifies rep
"""
tools = {
"get_lead": crm.get_lead,
"enrich_lead": enrichment_api.enrich,
"score_lead": scoring_model.score,
"find_best_rep": crm.find_available_rep,
"assign_lead": crm.assign,
"send_notification": slack.send
}
# Step 1: Observe
lead = get_lead(lead_id)
print(f"Observing lead: {lead['company']}")
# Step 2: Reason (LLM decides next action)
# LLM: "I need to enrich this lead first"
# Step 3: Act
enriched = enrich_lead(lead)
print(f"Enriched: revenue={enriched['revenue']}")
# Step 4: Feedback + Loop
# LLM: "Now I'll score"
# Step 5: Act
score = score_lead(enriched)
print(f"Score: {score}")
# Step 6: Reason
# LLM: "Score is {score}, should assign to top rep"
# Step 7: Act
best_rep = find_best_rep(score)
assign_lead(lead_id, best_rep)
send_notification(best_rep, f"New lead: {lead['company']}")
print(f"Assigned to {best_rep}")
Useimmat agentit kutsuvat REST API:ita. Käytä vakio-HTTP-asiakasta:
def call_crm_api(endpoint, method="GET", data=None):
url = f"https://api.crm.com/{endpoint}"
headers = {"Authorization": f"Bearer {api_key}"}
if method == "GET":
response = requests.get(url, headers=headers)
elif method == "POST":
response = requests.post(url, json=data, headers=headers)
return response.json()
Käynnistä agentit tapahtumissa (uusi liidi, saapuva sähköposti, lomakkeen lähetys):
@app.post("/webhook/new_lead")
def on_new_lead(lead_data):
# Trigger agent asynchronously
queue.enqueue(lead_qualification_agent, lead_data['id'])
return {"status": "queued"}
from ratelimit import limits, sleep_and_retry
@sleep_and_retry
@limits(calls=100, period=60) # 100 calls per minute
def call_api(endpoint):
return requests.get(f"https://api.example.com/{endpoint}")
Agentti lukee asiakkaan tiedot, aiemmat vuorovaikutukset, tietokannan:
def get_customer_history(customer_id):
query = "SELECT * FROM interactions WHERE customer_id = %s"
return db.execute(query, (customer_id,))
Agentti kirjoittaa päätöksiä tietokantaan:
def store_lead_score(lead_id, score, assigned_to):
db.execute(
"UPDATE leads SET score = %s, assigned_to = %s WHERE id = %s",
(score, assigned_to, lead_id)
)
Käytä transaktioita monivaiheisissa operaatioissa:
with db.transaction():
score = score_lead(lead)
db.update_lead_score(lead_id, score)
rep = find_best_rep(score)
db.assign_lead(lead_id, rep)
# All-or-nothing: if any step fails, rollback
Käytä virallisia SDK:ita:
from salesforce import SalesforceAPI
sf = SalesforceAPI(api_key=key)
# Update lead
sf.update_lead(lead_id, {
'score': 85,
'assigned_to': 'john@acme.com',
'status': 'qualified'
})
from slack_sdk import WebClient
slack = WebClient(token=slack_token)
# Notify sales rep
slack.chat_postMessage(
channel="john",
text=f"New qualified lead: {lead['company']} (score: {score})"
)
Käytä OAuth-laajuuksia rajoittaaksesi, mitä agentit voivat tehdä:
# Agent can only read leads, update scores
# Cannot delete leads or access sensitive data
oauth_scopes = ["leads:read", "leads:update"]
Korkean riskin päätökset: taloudelliset transaktiot, asiakashyvitykset, poliittiset poikkeukset.
if decision_risk_score > 0.7:
# Route to human for approval
escalate_to_human(decision, reason="High risk")
else:
# Agent executes decision
execute_decision(decision)
def lead_qualification_with_escalation(lead_id):
score = score_lead(lead_id)
if score > 80:
# High confidence, assign directly
assign_lead(lead_id, best_rep)
elif 50 < score < 80:
# Medium confidence, route to human
escalate_to_human(lead_id, "Review and assign")
else:
# Low score, reject
reject_lead(lead_id)
@app.post("/feedback/lead_score")
def on_score_feedback(lead_id, actual_score, agent_score):
# Store feedback
db.log_feedback(lead_id, agent_score, actual_score)
# Retrain model on feedback (periodic)
if should_retrain():
retrain_scoring_model()
# Bad: Agent keeps calling same tool
Agent thinks: "I need to get lead data"
→ Calls get_lead()
→ Still doesn't have enriched data
→ Calls get_lead() again
→ Infinite loop
max_steps = 10
steps_taken = 0
while steps_taken < max_steps:
action = llm.decide_next_action()
if action == last_action:
# Same action twice, break loop
break
execute_action(action)
steps_taken += 1
try:
result = agent.run(timeout=30) # 30 second timeout
except TimeoutError:
escalate_to_human("Agent loop timeout")
# Bad: Agent hallucinates tool output
Agent: "I called enrich_lead, got revenue=$100M"
Reality: enrich_lead() returned null (API failed)
Agent made up the result
def execute_tool_safely(tool_name, params):
try:
result = execute_tool(tool_name, params)
# Validate result
if result is None:
return {"error": "Tool returned null"}
if not validate_result(result):
return {"error": "Result failed validation"}
return result
except Exception as e:
return {"error": str(e)}
Käytä RAG:ia ankkuroidaksesi agentin faktoihin:
# Instead of: "Summarize this article"
# Use: "Summarize this article, citing specific passages"
knowledge_base = vector_db.search(query)
prompt = f"""
Summarize this article. Only cite specific passages.
Article: {article}
Knowledge base: {knowledge_base}
"""
def robust_agent_call(goal, retries=3):
for attempt in range(retries):
try:
result = agent.run(goal)
# Validate result
if validate(result):
return result
except Exception as e:
if attempt == retries - 1:
escalate_to_human(goal)
else:
time.sleep(2 ** attempt) # Backoff
# Bad: Ambiguous tool description
"update_lead - Update a lead"
# Good: Clear description
"update_lead - Update a lead's score, status, or assigned_to field.
Parameters: lead_id (required), score (0-100), status (qualified/disqualified),
assigned_to (sales rep email)"
# Validate before execution
tool_call = llm.decide_tool_call()
if not validate_tool_call(tool_call):
# Tool call is invalid, ask LLM to fix
llm.correct_tool_call(tool_call)
else:
execute_tool(tool_call)
def validate_tool_call(call):
tool = tools[call['name']]
required_params = tool['required_parameters']
for param in required_params:
if param not in call['params']:
return False
return True
try:
result = execute_tool(tool_call)
except ToolExecutionError as e:
# Suggest correct tool
correct_tool = suggest_correct_tool(e)
llm.suggest_retry(correct_tool)
# Bad: Agent calls same tool multiple times
Agent: "Let me get lead data"
→ Calls get_lead()
→ Calls get_lead() again (forgot it already did)
→ Calls get_lead() a third time
Cost: 3x higher than needed
budget = {"tokens": 10000, "api_calls": 50}
spent = {"tokens": 0, "api_calls": 0}
def execute_with_budget(action):
global spent
if spent['api_calls'] >= budget['api_calls']:
raise BudgetExceededError()
result = execute_action(action)
spent['api_calls'] += 1
return result
Toteuta välimuisti:
cache = {}
def get_lead_cached(lead_id):
if lead_id in cache:
return cache[lead_id]
result = crm_api.get_lead(lead_id)
cache[lead_id] = result
return result
if cost_this_hour > budget_per_hour:
# Switch to cheaper model
switch_to_model("gpt-3.5-turbo") # Cheaper than GPT-4
Agentti, joka tekee 5 peräkkäistä API-kutsua 1 sekunnin välein = 5+ sekunnin viive.
# Parallel execution
import asyncio
async def parallel_agent(lead_id):
lead = await get_lead_async(lead_id)
# Call multiple tools in parallel
enrichment, scoring = await asyncio.gather(
enrich_lead_async(lead),
score_lead_async(lead)
)
return (enrichment, scoring)
Käytä nopeampia malleja:
# Instead of GPT-4 (slower, more accurate)
# Use GPT-3.5-turbo (faster, still accurate enough)
model = "gpt-3.5-turbo" # 200ms latency vs 500ms for GPT-4
try:
result = agent.run(timeout=5) # 5 second timeout
return result
except TimeoutError:
# Return partial results
return partial_result
# Queue for async completion
queue.enqueue(complete_agent, lead_id)
Vertaa agentin tulostetta ground truthiin (ihmisen tarkistus, todelliset tulokset).
correct = 0
total = 100
for decision in agent_decisions:
if decision == human_review[decision.id]:
correct += 1
accuracy = correct / total * 100 # e.g., 94%
Mittaa päästä päähän -aika syötteestä tulosteeseen.
start = time.time()
result = agent.run(input_data)
latency = time.time() - start # e.g., 8.5 seconds
cost = (llm_api_calls * llm_cost) + (tool_calls * tool_cost) + (human_review_rate * hourly_rate)
# e.g., $0.03 per lead
Kysely käyttäjiltä: “Kuinka tyytyväinen olet agentin päätöksiin?”
automated = tasks_completed_by_agent
total = all_tasks
automation_rate = automated / total * 100 # e.g., 87%
Manual lead qualification:
- 100 leads/month
- 5 minutes per lead
- 500 hours/month
- $20/hour = $10,000/month
Agent-driven:
- 100 leads/month
- $0.03 per lead (API calls)
- $3 total API cost
- $500/month human review (10% escalation)
- $100/month infrastructure
Total: $603/month
Savings per month: $10,000 - $603 = $9,397
ROI: 1,557% (9,397 / 603)
Payback period: < 1 month (immediate)
Manual process:
- 500 leads/month
- 5 min per lead = 2,500 hours = $50,000/month
Agent process:
- 500 leads/month
- $0.03 per lead = $15
- 5% escalation (25 leads) = $250 human time
- Infrastructure = $500
Total: $765/month
Savings: $50,000 - $765 = $49,235/month
ROI: 6,436%
# Track daily metrics
daily_metrics = {
'accuracy': 0.94,
'latency': 8.5,
'cost_per_task': 0.03,
'automation_rate': 0.87
}
# Test 1: GPT-4 (more accurate, slower)
# Test 2: GPT-3.5-turbo (faster, slightly less accurate)
# Measure: accuracy, latency, cost
# Choose based on your priorities
# Collect human feedback on agent mistakes
feedback = db.get_feedback()
# Retrain agent (adjust prompts, add examples)
agent.retrain(feedback)
# Measure: accuracy improves from 94% to 96%
Valvo ROI:ta. Jos agentti ei tuota arvoa, poista se. Skaalaa onnistuneet agentit muille tiimeille.
FAQ-osio renderöityy automaattisesti frontmatterista ja näkyy alla.
{{ cta-dark-panel heading=“Rakenna agentteja ilman monimutkaisuutta” description=“FlowHuntin natiivi agenttialusta hoitaa työkaluintegraatiot, virheenkäsittelyn ja valvonnan. Aloita autonomisten työnkulkujen rakentaminen minuuteissa, ei viikoissa.” ctaPrimaryText=“Kokeile FlowHuntia ilmaiseksi” ctaPrimaryURL=“https://app.flowhunt.io/sign-in" ctaSecondaryText=“Varaa demo” ctaSecondaryURL=“https://www.flowhunt.io/demo/" gradientStartColor="#7c3aed” gradientEndColor="#ec4899” gradientId=“cta-ai-agents” }}
Arshia on AI-työnkulkuinsinööri FlowHuntilla. Tietojenkäsittelytieteen taustalla ja intohimolla tekoälyyn hän erikoistuu luomaan tehokkaita työnkulkuja, jotka integroivat tekoälytyökaluja arjen tehtäviin, parantaen tuottavuutta ja luovuutta.

FlowHuntin natiivi agenttialusta hoitaa työkaluintegraatiot, virheenkäsittelyn ja valvonnan. Aloita autonomisten työnkulkujen rakentaminen minuuteissa.
Opi rakentamaan, konfiguroimaan ja orkestroimaan AI-agentteja FlowHuntissa. Yksinkertaisista agenteista deep agenteihin ja täysiin tiimeihin, löydä kaikki tarvi...
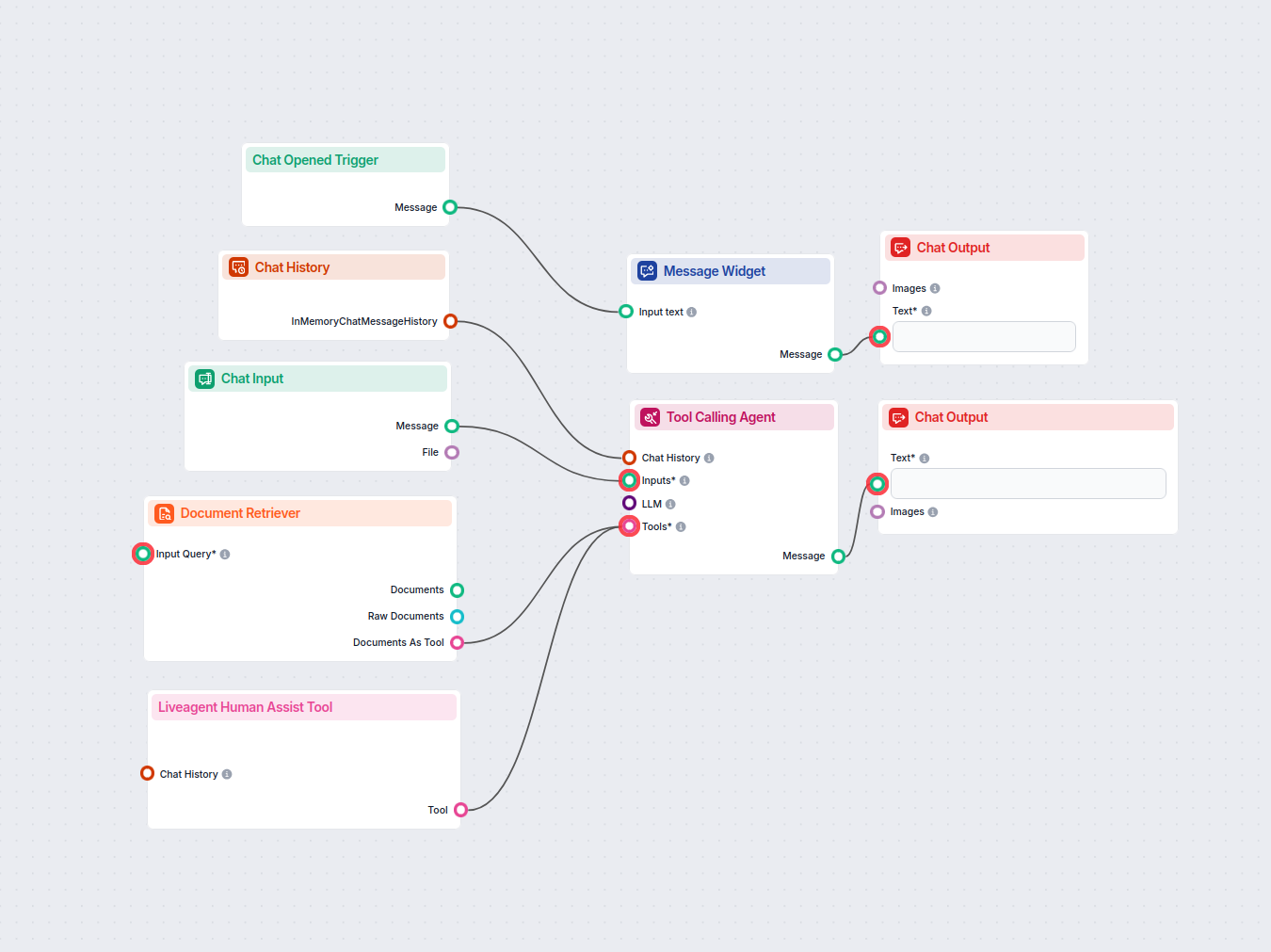
Automatisoi asiakastukesi tekoälybottilla, joka vastaa kysymyksiin sisäisen tietopankkisi avulla ja yhdistää käyttäjän tarvittaessa saumattomasti LiveAgentin ka...

Opi luomaan lääketieteellinen chatbot tekoälyllä hyödyntämällä FlowHuntin PubMed-työkalua. Tämä kattava opas kattaa tutkimusprosessin rakentamisen, tekoälyagent...
Evästeiden Suostumus
Käytämme evästeitä parantaaksemme selauskokemustasi ja analysoidaksemme liikennettämme. See our privacy policy.