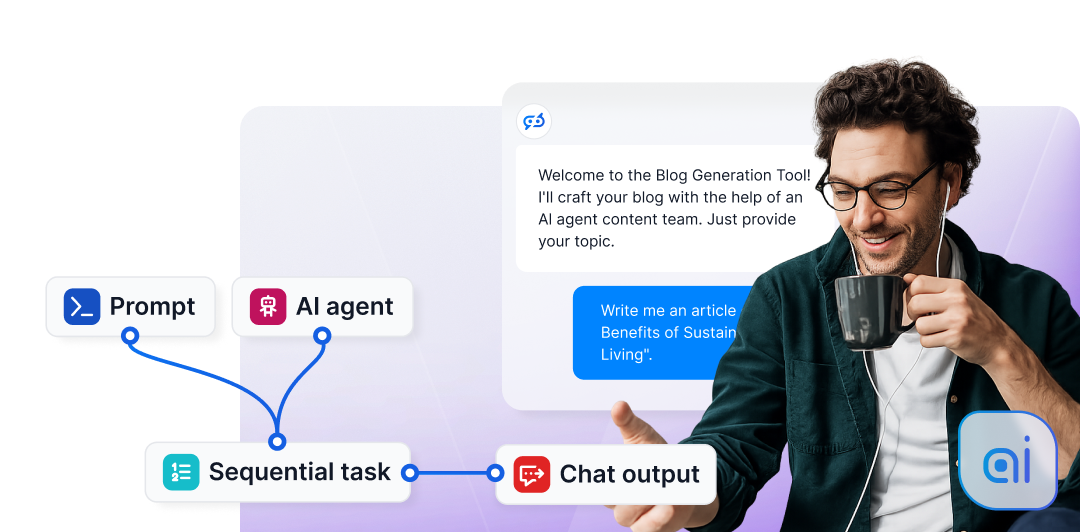
وكلاء الذكاء الاصطناعي
تعرف على كيفية بناء وتكوين وتنسيق وكلاء الذكاء الاصطناعي في FlowHunt. من الوكلاء البسطاء إلى الوكلاء العميقين والطاقم الكامل، ستجد جميع الأدلة التي تحتاجها هنا....
3 دقيقة قراءة
الوكلاء
تعلّم كيفية بناء وكلاء ذكاء اصطناعي موثوقين بهندسة معمارية سليمة، وتكامل الأدوات، ومنع الأعطال. قارن بين الأُطر والأنماط والأمثلة الواقعية.
وكلاء الذكاء الاصطناعي يختلفون جوهريًا عن روبوتات الدردشة. روبوت الدردشة ينتظر إدخال المستخدم ويستجيب. أما الوكيل فيسعى لتحقيق أهداف ذاتيًا، مستدعيًا الأدوات ومفكّرًا في المشكلات ومتخذًا إجراءات دون تدخل بشري في كل خطوة.
يهم هذا التمييز لأن الوكلاء يمكنهم أتمتة سير عمل كامل. وكيل تأهيل العملاء المحتملين يقيّم المرشحين، ويُثري بياناتهم، ويُسندهم إلى مندوبي المبيعات—كل ذلك دون تدخل بشري. وكيل فرز المحتوى يصنّف تذاكر الدعم، ويوجّهها إلى المختصين، ويصعّد الحالات الحدية إلى البشر.
في هذا الدليل ستتعلم كيفية هندسة وكلاء موثوقين، ودمجهم مع أنظمة الأعمال، ومنع الأعطال الشائعة، وقياس أثرهم. سنتناول أنماطًا حقيقية تُستخدم في الإنتاج لدى شركات تؤتمت تأهيل العملاء المحتملين، ومعالجة المستندات، ودعم العملاء على نطاق واسع.
وكيل الذكاء الاصطناعي هو نظام برمجي:
الوكلاء موجّهون بالأهداف. أنت تحدد الهدف (“قيّم هذا العميل المحتمل وأهّله”)، والوكيل يجد طريقة لتحقيقه.
User: "What's the status of my order?"
Chatbot: [Looks up order, responds]
User: "Can you cancel it?"
Chatbot: [Cancels order, responds]
المستخدم يقود كل تفاعل. روبوت الدردشة عديم الحالة—كل رسالة مستقلة.
Agent goal: "Qualify and score this lead"
1. Agent observes: [Lead data from CRM]
2. Agent reasons: "I need to enrich this data and score them"
3. Agent acts: Calls enrichment API
4. Agent observes: [Enriched data]
5. Agent reasons: "Score is 85, should assign to top sales rep"
6. Agent acts: Updates CRM, sends notification
7. Done. No human input required.
يعمل الوكيل نحو هدف محدد، ويتخذ قرارات متعددة ويجري استدعاءات أدوات ذاتيًا.
تأهيل العملاء المحتملين يدويًا: 5 دقائق لكل عميل × 100 عميل = 500 ساعة/شهر. التكلفة: 10,000 دولار/شهر (بسعر 20 دولارًا/ساعة).
مدفوعًا بالوكلاء: 10 ثوانٍ لكل عميل × 100 عميل = 16 ساعة/شهر. التكلفة: 100 دولار (استدعاءات API للوكيل). التوفير: 99%.
الوكلاء يضاعفون قدرة فريقك دون توظيف.
المهام المعقدة تتطلب خطوات متعددة:
يتولى الوكلاء هذا الاستدلال تلقائيًا. أنت تحدد الهدف؛ والوكيل يقسّمه إلى خطوات.
الوكلاء هم “الأيدي”. يستدعون واجهات API من أجل:
يمكن لوكيل واحد تنسيق 5-10 استدعاءات أدوات لإكمال سير العمل.
يمكن للوكلاء التحسّن بمرور الوقت. إذا صنّف الوكيل المستندات بشكل خاطئ، تقدم تغذية راجعة. يتعلم الوكيل ويعدّل استراتيجية التوجيه الخاصة به.
جوهر كل وكيل هو حلقة:
┌─────────────────────────────────────────┐
│ START: Agent receives goal │
└────────────────┬────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ OBSERVE: Read input, tool results, │
│ memory, environment │
└────────────────┬────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ REASON: LLM decides next action │
│ (which tool to call, or done?) │
└────────────────┬────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ ACT: Execute tool call or complete │
│ task │
└────────────────┬────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ FEEDBACK: Evaluate result, update │
│ memory, check if goal met │
└────────────────┬────────────────────────┘
│
├─→ Goal not met? Loop back to OBSERVE
│
└─→ Goal met or max steps reached? DONE
يقرأ الوكيل:
يتلقى النموذج اللغوي الكبير موجّهًا مثل:
You are a lead qualification agent. Your goal is to score and qualify this lead.
Available tools:
1. enrich_lead(lead_id) - Get additional data about the lead
2. score_lead(lead_data) - Score based on criteria
3. assign_to_sales_rep(lead_id, rep_id) - Assign lead to a rep
4. send_notification(rep_id, message) - Notify rep
Current state:
- Lead ID: 12345
- Company: Acme Corp
- Revenue: Unknown (need to enrich)
- Status: Not scored yet
What should you do next?
يستجيب النموذج: “ينبغي أن أُثري العميل المحتمل أولًا للحصول على بيانات الإيرادات، ثم التقييم، ثم التعيين.”
ينفذ الوكيل الأداة المختارة:
result = enrich_lead(lead_id=12345)
# Returns: {'revenue': '$10M', 'industry': 'SaaS', 'employees': 150}
يتحقق الوكيل: هل نجح استدعاء الأداة؟ هل اقترب من الهدف؟ يحدّث الذاكرة ويستمر في الحلقة.
يكرر الوكيل الملاحظة ← الاستدلال ← الإجراء ← التغذية الراجعة حتى:
الأدوات هي دوال يمكن للوكيل استدعاؤها. عرّفها بوضوح:
tools = [
{
"name": "enrich_lead",
"description": "Get additional company data about a lead (revenue, employees, industry)",
"parameters": {
"lead_id": {"type": "string", "description": "Unique identifier of the lead"}
}
},
{
"name": "score_lead",
"description": "Score a lead on a scale of 0-100 based on fit criteria",
"parameters": {
"lead_data": {"type": "object", "description": "Lead information including revenue, industry, etc."}
}
}
]
الأوصاف الواضحة تساعد النموذج اللغوي على اختيار الأداة الصحيحة.
يستجيب النموذج اللغوي باستدعاء أداة:
{
"thought": "I need to enrich this lead to get revenue data",
"action": "enrich_lead",
"action_input": {"lead_id": "12345"}
}
ينفّذ إطار عمل الوكيل الأداة ويعيد النتيجة إلى النموذج اللغوي.
تعامل مع النجاح والفشل:
def execute_tool(tool_name, tool_input):
try:
if tool_name == "enrich_lead":
result = crm_api.enrich(tool_input['lead_id'])
return {"status": "success", "data": result}
except Exception as e:
return {"status": "error", "message": str(e)}
إذا فشلت الأداة، ينبغي أن يحاول الوكيل نهجًا مختلفًا أو يصعّد إلى إنسان.
الذاكرة العاملة للوكيل: الإدخال الحالي، نتائج الأدوات، خطوات الاستدلال. تُخزَّن عادةً في نافذة السياق (الموجّه).
مثال: وكيل تأهيل العملاء المحتملين يتذكّر:
ذاكرة دائمة: القرارات السابقة، الأنماط المتعلَّمة، قاعدة المعرفة.
حالات الاستخدام:
نفّذ ذلك باستخدام قواعد البيانات المتجهية (Pinecone، Weaviate) للبحث الدلالي.
نماذج اللغة الكبيرة لها نوافذ سياق محدودة (4K-128K رمزًا). لا يمكن للوكلاء تذكّر كل شيء. الاستراتيجيات:
لمعظم الوكلاء، Claude أو النماذج مفتوحة المصدر كافية وأرخص.
مثال على موجّه Reflexion:
Agent: "I'll assign this lead to rep John."
Critic: "Wait, did you check if John is already at capacity?"
Agent: "Good point. Let me check John's workload first."
اختر السرعة للوقت الفعلي (دعم العملاء). اختر الدقة للقرارات عالية المخاطر (القرارات المالية).
ابدأ تجربتك المجانية اليوم وشاهد النتائج في غضون أيام.
يتخذ الوكلاء التفاعليون قرارًا واحدًا ويتصرفون. لا تخطيط متعدد الخطوات.
Input: "What's my account balance?"
→ Agent queries database
→ Agent responds with balance
Done.
def customer_service_agent(question):
# 1. Search knowledge base
articles = search_kb(question)
# 2. LLM picks best article
response = llm.complete(f"""
Question: {question}
Relevant articles: {articles}
Provide an answer based on these articles.
""")
# 3. Return response
return response
زمن الاستجابة: 1-3 ثوانٍ. التكلفة: 0.001-0.01 دولار لكل استعلام.
وكلاء التخطيط يفككون الأهداف المعقدة إلى خطوات.
Goal: "Qualify and assign this lead"
→ Agent plans: [enrich, score, assign, notify]
→ Agent executes each step
→ Agent verifies goal achieved
Done.
def lead_qualification_agent(lead_id):
lead = crm.get_lead(lead_id)
# Step 1: Enrich
enriched = enrich_lead(lead)
# Step 2: Score
score = score_lead(enriched)
# Step 3: Assign
best_rep = find_best_sales_rep(score)
crm.assign_lead(lead_id, best_rep)
# Step 4: Notify
send_slack(f"New qualified lead assigned to {best_rep}")
return {"lead_id": lead_id, "score": score, "assigned_to": best_rep}
زمن الاستجابة: 5-15 ثانية. التكلفة: 0.02-0.05 دولار لكل عميل محتمل.
وكلاء التعلّم يتحسّنون مع التغذية الراجعة.
Initial: Agent classifies document as "Invoice" (60% confidence)
Human feedback: "Actually, it's a Receipt"
Agent learns: Adjust classification prompts
Next time: Same document classified as "Receipt" (90% confidence)
def recommendation_agent(user_id):
# Get user history
history = db.get_user_history(user_id)
# LLM recommends based on patterns
recommendation = llm.complete(f"""
User history: {history}
Based on past preferences, what should we recommend?
""")
# Show recommendation, collect feedback
feedback = user_feedback # thumbs up/down
# Store feedback for future recommendations
db.log_feedback(user_id, recommendation, feedback)
return recommendation
بمرور الوقت، تتحسن التوصيات مع تعلم الوكيل لتفضيلات المستخدم.
وكيل مشرف ينسّق وكلاء متخصصين.
Supervisor: "Process this support ticket"
├─ Classifier agent: "This is a billing issue"
├─ Billing specialist agent: "Refund $50"
└─ Notification agent: "Send confirmation email"
def content_pipeline_agent(topic):
# Supervisor delegates
research = research_agent(topic)
draft = writer_agent(research)
edited = editor_agent(draft)
published = publisher_agent(edited)
return {"topic": topic, "status": "published"}
كل وكيل متخصص محسّن لمهمته. المشرف ينسّق.
مدى تطوّر تفكير الوكيل. الوكلاء البسطاء يستخدمون chain-of-thought. الوكلاء المعقدون يستخدمون التخطيط وReflexion.
هل يمكنك توصيل واجهات API وقواعد البيانات وأنظمة CRM بسهولة؟ أم أنك تحتاج إلى كود مخصص؟
كم بسرعة يمكن لمطوّر الحصول على وكيل يعمل؟ المنصات بدون كود أسرع؛ أطر بايثون أكثر مرونة.
بعض الأطر مفتوحة المصدر (مجانية). أخرى تفرض رسومًا لكل استدعاء API أو اشتراك.
لماذا كل أداة محسّنة؟
| Tool | Framework Type | Reasoning Capability | Tool Integration | Learning Curve | Pricing | Best For |
|---|---|---|---|---|---|---|
| n8n | Visual workflow builder | Chain-of-thought | 500+ integrations | Low | Free + paid | Non-technical users, quick setup |
| CrewAI | Python framework | Planning + reflexion | Custom tools (Python) | Medium | Open-source | Developers, complex agents |
| Autogen | Python framework | Multi-agent reasoning | Custom tools | High | Open-source | Research, multi-agent systems |
| LangGraph | Python framework | Planning + state management | LangChain ecosystem | Medium | Open-source | Complex workflows, state tracking |
| FlowHunt | Native platform | Chain-of-thought + planning | Native + API integrations | Low | Subscription | Workflow automation, ease-of-use |
| Lindy.ai | No-code platform | Chain-of-thought | 100+ integrations | Very low | Freemium | Non-technical, quick agents |
| Gumloop | No-code platform | Chain-of-thought | 50+ integrations | Very low | Freemium | Simple automation, templates |
الاختلافات الرئيسية:
احصل على أحدث النصائح والاتجاهات والعروض مجانًا.
كن محددًا. سيء: “أتمتة إدارة العملاء المحتملين.” جيد: “تقييم العملاء المحتملين 0-100، إثراؤهم ببيانات الشركة، تعيينهم لمندوبي المبيعات بناءً على السعة.”
المقايضات:
بيانات الإدخال: بيانات العميل المحتمل، نص المستند، سؤال العميل، السياق من الذاكرة.
قائمة بواجهات API وقواعد البيانات والخدمات التي سيستدعيها الوكيل.
مثال لتأهيل العملاء المحتملين:
عرّف شرط النجاح. “توقف عندما يُقيَّم العميل المحتمل ويُعيَّن.”
عرّف أيضًا الحد الأقصى من الخطوات لمنع الحلقات اللانهائية. “توقف بعد 10 خطوات، بغض النظر.”
مثال CrewAI:
from crewai import Agent, Task, Crew
# Define agents
enrichment_agent = Agent(
role="Data Enrichment Specialist",
goal="Enrich lead data with company information",
tools=[enrich_tool]
)
scoring_agent = Agent(
role="Lead Scoring Expert",
goal="Score leads based on fit criteria",
tools=[score_tool]
)
assignment_agent = Agent(
role="Sales Manager",
goal="Assign leads to best sales rep",
tools=[assign_tool, notify_tool]
)
# Define tasks
enrich_task = Task(
description="Enrich this lead: {lead_id}",
agent=enrichment_agent
)
score_task = Task(
description="Score the enriched lead",
agent=scoring_agent
)
assign_task = Task(
description="Assign lead to best rep and notify",
agent=assignment_agent
)
# Run crew
crew = Crew(agents=[enrichment_agent, scoring_agent, assignment_agent],
tasks=[enrich_task, score_task, assign_task])
result = crew.kickoff(inputs={"lead_id": "12345"})
def test_enrichment_tool():
result = enrich_tool("lead_123")
assert result['revenue'] is not None
assert result['employees'] is not None
def test_scoring_agent():
lead = {"company": "Acme", "revenue": "10M", "employees": 50}
score = score_agent(lead)
assert 0 <= score <= 100
def test_full_loop():
result = lead_qualification_agent("lead_123")
assert result['assigned_to'] is not None
assert result['score'] > 0
def lead_qualification_agent(lead_id):
"""
Autonomous agent that qualifies leads.
1. Fetches lead from CRM
2. Enriches with company data
3. Scores based on fit criteria
4. Assigns to best sales rep
5. Notifies rep
"""
tools = {
"get_lead": crm.get_lead,
"enrich_lead": enrichment_api.enrich,
"score_lead": scoring_model.score,
"find_best_rep": crm.find_available_rep,
"assign_lead": crm.assign,
"send_notification": slack.send
}
# Step 1: Observe
lead = get_lead(lead_id)
print(f"Observing lead: {lead['company']}")
# Step 2: Reason (LLM decides next action)
# LLM: "I need to enrich this lead first"
# Step 3: Act
enriched = enrich_lead(lead)
print(f"Enriched: revenue={enriched['revenue']}")
# Step 4: Feedback + Loop
# LLM: "Now I'll score"
# Step 5: Act
score = score_lead(enriched)
print(f"Score: {score}")
# Step 6: Reason
# LLM: "Score is {score}, should assign to top rep"
# Step 7: Act
best_rep = find_best_rep(score)
assign_lead(lead_id, best_rep)
send_notification(best_rep, f"New lead: {lead['company']}")
print(f"Assigned to {best_rep}")
معظم الوكلاء يستدعون REST APIs. استخدم عميل HTTP قياسي:
def call_crm_api(endpoint, method="GET", data=None):
url = f"https://api.crm.com/{endpoint}"
headers = {"Authorization": f"Bearer {api_key}"}
if method == "GET":
response = requests.get(url, headers=headers)
elif method == "POST":
response = requests.post(url, json=data, headers=headers)
return response.json()
شغّل الوكلاء بناءً على الأحداث (عميل محتمل جديد، بريد إلكتروني وارد، إرسال نموذج):
@app.post("/webhook/new_lead")
def on_new_lead(lead_data):
# Trigger agent asynchronously
queue.enqueue(lead_qualification_agent, lead_data['id'])
return {"status": "queued"}
from ratelimit import limits, sleep_and_retry
@sleep_and_retry
@limits(calls=100, period=60) # 100 calls per minute
def call_api(endpoint):
return requests.get(f"https://api.example.com/{endpoint}")
الوكيل يقرأ بيانات العميل، التفاعلات السابقة، قاعدة المعرفة:
def get_customer_history(customer_id):
query = "SELECT * FROM interactions WHERE customer_id = %s"
return db.execute(query, (customer_id,))
الوكيل يكتب القرارات في قاعدة البيانات:
def store_lead_score(lead_id, score, assigned_to):
db.execute(
"UPDATE leads SET score = %s, assigned_to = %s WHERE id = %s",
(score, assigned_to, lead_id)
)
استخدم المعاملات للعمليات متعددة الخطوات:
with db.transaction():
score = score_lead(lead)
db.update_lead_score(lead_id, score)
rep = find_best_rep(score)
db.assign_lead(lead_id, rep)
# All-or-nothing: if any step fails, rollback
استخدم SDKs الرسمية:
from salesforce import SalesforceAPI
sf = SalesforceAPI(api_key=key)
# Update lead
sf.update_lead(lead_id, {
'score': 85,
'assigned_to': 'john@acme.com',
'status': 'qualified'
})
from slack_sdk import WebClient
slack = WebClient(token=slack_token)
# Notify sales rep
slack.chat_postMessage(
channel="john",
text=f"New qualified lead: {lead['company']} (score: {score})"
)
استخدم نطاقات OAuth للحد مما يمكن للوكلاء فعله:
# Agent can only read leads, update scores
# Cannot delete leads or access sensitive data
oauth_scopes = ["leads:read", "leads:update"]
القرارات عالية المخاطر: المعاملات المالية، استرداد أموال العملاء، استثناءات السياسة.
if decision_risk_score > 0.7:
# Route to human for approval
escalate_to_human(decision, reason="High risk")
else:
# Agent executes decision
execute_decision(decision)
def lead_qualification_with_escalation(lead_id):
score = score_lead(lead_id)
if score > 80:
# High confidence, assign directly
assign_lead(lead_id, best_rep)
elif 50 < score < 80:
# Medium confidence, route to human
escalate_to_human(lead_id, "Review and assign")
else:
# Low score, reject
reject_lead(lead_id)
@app.post("/feedback/lead_score")
def on_score_feedback(lead_id, actual_score, agent_score):
# Store feedback
db.log_feedback(lead_id, agent_score, actual_score)
# Retrain model on feedback (periodic)
if should_retrain():
retrain_scoring_model()
# Bad: Agent keeps calling same tool
Agent thinks: "I need to get lead data"
→ Calls get_lead()
→ Still doesn't have enriched data
→ Calls get_lead() again
→ Infinite loop
max_steps = 10
steps_taken = 0
while steps_taken < max_steps:
action = llm.decide_next_action()
if action == last_action:
# Same action twice, break loop
break
execute_action(action)
steps_taken += 1
try:
result = agent.run(timeout=30) # 30 second timeout
except TimeoutError:
escalate_to_human("Agent loop timeout")
# Bad: Agent hallucinates tool output
Agent: "I called enrich_lead, got revenue=$100M"
Reality: enrich_lead() returned null (API failed)
Agent made up the result
def execute_tool_safely(tool_name, params):
try:
result = execute_tool(tool_name, params)
# Validate result
if result is None:
return {"error": "Tool returned null"}
if not validate_result(result):
return {"error": "Result failed validation"}
return result
except Exception as e:
return {"error": str(e)}
استخدم RAG لتأصيل الوكيل في الحقائق:
# Instead of: "Summarize this article"
# Use: "Summarize this article, citing specific passages"
knowledge_base = vector_db.search(query)
prompt = f"""
Summarize this article. Only cite specific passages.
Article: {article}
Knowledge base: {knowledge_base}
"""
def robust_agent_call(goal, retries=3):
for attempt in range(retries):
try:
result = agent.run(goal)
# Validate result
if validate(result):
return result
except Exception as e:
if attempt == retries - 1:
escalate_to_human(goal)
else:
time.sleep(2 ** attempt) # Backoff
# Bad: Ambiguous tool description
"update_lead - Update a lead"
# Good: Clear description
"update_lead - Update a lead's score, status, or assigned_to field.
Parameters: lead_id (required), score (0-100), status (qualified/disqualified),
assigned_to (sales rep email)"
# Validate before execution
tool_call = llm.decide_tool_call()
if not validate_tool_call(tool_call):
# Tool call is invalid, ask LLM to fix
llm.correct_tool_call(tool_call)
else:
execute_tool(tool_call)
def validate_tool_call(call):
tool = tools[call['name']]
required_params = tool['required_parameters']
for param in required_params:
if param not in call['params']:
return False
return True
try:
result = execute_tool(tool_call)
except ToolExecutionError as e:
# Suggest correct tool
correct_tool = suggest_correct_tool(e)
llm.suggest_retry(correct_tool)
# Bad: Agent calls same tool multiple times
Agent: "Let me get lead data"
→ Calls get_lead()
→ Calls get_lead() again (forgot it already did)
→ Calls get_lead() a third time
Cost: 3x higher than needed
budget = {"tokens": 10000, "api_calls": 50}
spent = {"tokens": 0, "api_calls": 0}
def execute_with_budget(action):
global spent
if spent['api_calls'] >= budget['api_calls']:
raise BudgetExceededError()
result = execute_action(action)
spent['api_calls'] += 1
return result
نفّذ التخزين المؤقت:
cache = {}
def get_lead_cached(lead_id):
if lead_id in cache:
return cache[lead_id]
result = crm_api.get_lead(lead_id)
cache[lead_id] = result
return result
if cost_this_hour > budget_per_hour:
# Switch to cheaper model
switch_to_model("gpt-3.5-turbo") # Cheaper than GPT-4
وكيل يجري 5 استدعاءات API متسلسلة بثانية لكل منها = 5+ ثوانٍ زمن استجابة.
# Parallel execution
import asyncio
async def parallel_agent(lead_id):
lead = await get_lead_async(lead_id)
# Call multiple tools in parallel
enrichment, scoring = await asyncio.gather(
enrich_lead_async(lead),
score_lead_async(lead)
)
return (enrichment, scoring)
استخدم نماذج أسرع:
# Instead of GPT-4 (slower, more accurate)
# Use GPT-3.5-turbo (faster, still accurate enough)
model = "gpt-3.5-turbo" # 200ms latency vs 500ms for GPT-4
try:
result = agent.run(timeout=5) # 5 second timeout
return result
except TimeoutError:
# Return partial results
return partial_result
# Queue for async completion
queue.enqueue(complete_agent, lead_id)
قارن مخرجات الوكيل بالحقيقة الأرضية (مراجعة بشرية، نتائج فعلية).
correct = 0
total = 100
for decision in agent_decisions:
if decision == human_review[decision.id]:
correct += 1
accuracy = correct / total * 100 # e.g., 94%
قِس الوقت من طرف إلى طرف من الإدخال إلى الإخراج.
start = time.time()
result = agent.run(input_data)
latency = time.time() - start # e.g., 8.5 seconds
cost = (llm_api_calls * llm_cost) + (tool_calls * tool_cost) + (human_review_rate * hourly_rate)
# e.g., $0.03 per lead
استطلع آراء المستخدمين: “ما مدى رضاك عن قرارات الوكيل؟”
automated = tasks_completed_by_agent
total = all_tasks
automation_rate = automated / total * 100 # e.g., 87%
Manual lead qualification:
- 100 leads/month
- 5 minutes per lead
- 500 hours/month
- $20/hour = $10,000/month
Agent-driven:
- 100 leads/month
- $0.03 per lead (API calls)
- $3 total API cost
- $500/month human review (10% escalation)
- $100/month infrastructure
Total: $603/month
Savings per month: $10,000 - $603 = $9,397
ROI: 1,557% (9,397 / 603)
Payback period: < 1 month (immediate)
Manual process:
- 500 leads/month
- 5 min per lead = 2,500 hours = $50,000/month
Agent process:
- 500 leads/month
- $0.03 per lead = $15
- 5% escalation (25 leads) = $250 human time
- Infrastructure = $500
Total: $765/month
Savings: $50,000 - $765 = $49,235/month
ROI: 6,436%
# Track daily metrics
daily_metrics = {
'accuracy': 0.94,
'latency': 8.5,
'cost_per_task': 0.03,
'automation_rate': 0.87
}
# Test 1: GPT-4 (more accurate, slower)
# Test 2: GPT-3.5-turbo (faster, slightly less accurate)
# Measure: accuracy, latency, cost
# Choose based on your priorities
# Collect human feedback on agent mistakes
feedback = db.get_feedback()
# Retrain agent (adjust prompts, add examples)
agent.retrain(feedback)
# Measure: accuracy improves from 94% to 96%
راقب العائد على الاستثمار. إذا لم يقدم الوكيل قيمة، اسحبه. وسّع نطاق الوكلاء الناجحين إلى فرق أخرى.
يتم عرض قسم الأسئلة الشائعة تلقائيًا من frontmatter ويظهر أدناه.
{{ cta-dark-panel heading=“Build Agents Without the Complexity” description=“FlowHunt’s native agent platform handles tool integration, error handling, and monitoring. Start building autonomous workflows in minutes, not weeks.” ctaPrimaryText=“Try FlowHunt Free” ctaPrimaryURL=“https://app.flowhunt.io/sign-in" ctaSecondaryText=“Book a Demo” ctaSecondaryURL=“https://www.flowhunt.io/demo/" gradientStartColor="#7c3aed” gradientEndColor="#ec4899” gradientId=“cta-ai-agents” }}
أرشيا هو مهندس سير عمل الذكاء الاصطناعي في FlowHunt. بخلفية في علوم الحاسوب وشغف بالذكاء الاصطناعي، يختص في إنشاء سير عمل فعّال يدمج أدوات الذكاء الاصطناعي في المهام اليومية، مما يعزز الإنتاجية والإبداع.

منصة الوكلاء الأصلية من FlowHunt تتعامل مع تكامل الأدوات ومعالجة الأخطاء والمراقبة. ابدأ ببناء سير عمل ذاتي التشغيل في دقائق.
تعرف على كيفية بناء وتكوين وتنسيق وكلاء الذكاء الاصطناعي في FlowHunt. من الوكلاء البسطاء إلى الوكلاء العميقين والطاقم الكامل، ستجد جميع الأدلة التي تحتاجها هنا....

تعلم كيفية إنشاء روبوت دردشة طبي باستخدام الذكاء الاصطناعي وأداة PubMed من FlowHunt. يغطي هذا الدليل الشامل إعداد تدفق البحث، ودمج وكلاء الذكاء الاصطناعي، والوص...
اكتشف كيف يُحدث الذكاء الاصطناعي الوكيل وأنظمة الوكلاء المتعددة ثورة في أتمتة سير العمل من خلال اتخاذ القرار الذاتي، والقدرة على التكيف، والتعاون—ما يعزز الكفاء...
الموافقة على ملفات تعريف الارتباط
نستخدم ملفات تعريف الارتباط لتعزيز تجربة التصفح وتحليل حركة المرور لدينا. See our privacy policy.