Slack-integration
FlowHunts Slack-integration möjliggör sömlöst AI-samarbete direkt i ditt Slack-arbetsutrymme. Ta med valfri Flow till Slack, automatisera arbetsflöden, få AI-hj...
7 min läsning
Slack
Integration
+3

Anslut vilken LLM som helst (Claude, GPT, Gemini, Grok, Llama, Mistral) till Slack med FlowHunts no-code flödesbyggare. Konfigurationen är densamma för varje modell — välj den modell som passar ditt användningsfall och driftsätt på minuter.
Att lägga till en AI-assistent i Slack brukade innebära att välja en leverantör, skriva integrationskod och bygga om allt när en bättre modell släpptes sex månader senare. Med FlowHunt är integrationen frikopplad från modellen: du bygger Slack-flödet en gång, kopplar in den LLM du vill ha — Claude, GPT, Gemini, Grok, Llama, Mistral — och byter ut den när som helst utan att röra resten.
Den här guiden går igenom hela installationen. Första halvan är densamma för varje modell. Andra halvan bryter ner vilken modell man ska välja för vilket användningsfall, med anteckningar specifika för varje LLM-familj. Hoppa till avsnittet som matchar din stack, eller läs från början till slut om du börjar från noll.
Slack är där team ställer frågor. En AI-agent som lever där svarar på dem omedelbart — utan att byta kontext till ett separat chattverktyg, dashboard eller kunskapsbas. Vanliga driftsättningar:
Boten lever i Slack, så adoptionen är automatisk — ingen behöver lära sig ett nytt verktyg.
Starta din kostnadsfria provperiod idag och se resultat inom några dagar.
Installationen är identisk oavsett vilken AI-modell du väljer. Välj din modell i steg 4; allt annat förblir detsamma.
Logga in på ditt FlowHunt -konto och öppna fliken Integrations. Välj Slack, klicka Connect och auktorisera appen på Slacks OAuth-skärm. Bevilja de läs-/skrivbehörigheter som FlowHunt begär — de låter boten ta emot meddelanden och posta svar i din arbetsyta.
URL:en till din arbetsyta visas i det övre vänstra hörnet av Slack-skrivbords- eller webbappen — kopiera den därifrån om FlowHunt frågar. När den är auktoriserad är Slack ansluten och redo att användas i vilket flöde som helst.
I FlowHunts flödesbyggare, släpp en Slack Message Received-komponent på canvasen. Detta block lyssnar efter inkommande Slack-meddelanden och triggar resten av flödet.
Konfigurera två inställningar:
#ai-assistant-kanal är den renaste installationen.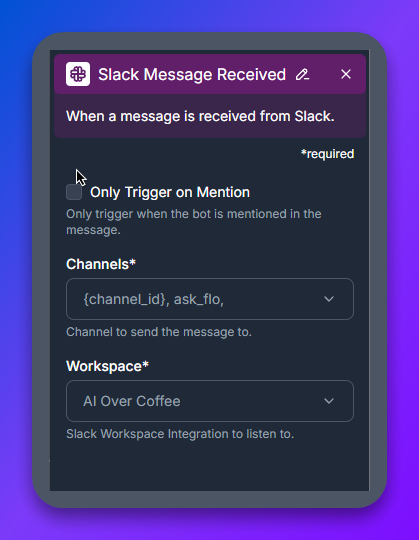
AI Agent-blocket är botens resonemangslager. Det tar användarens meddelande, bestämmer vilka verktyg som ska användas och utformar svaret.
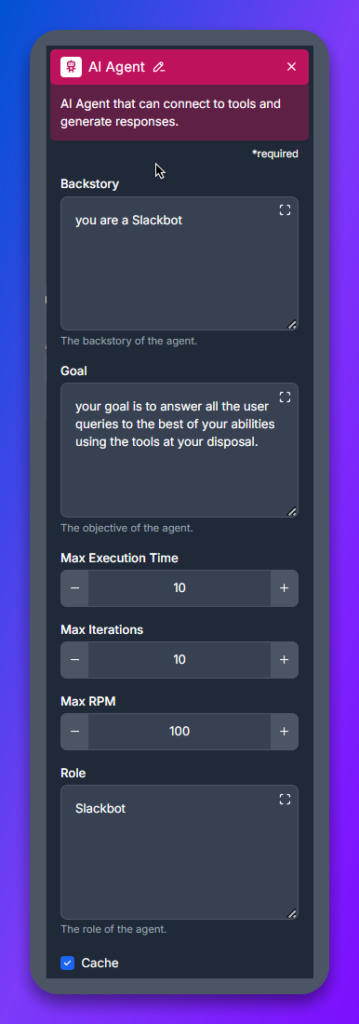
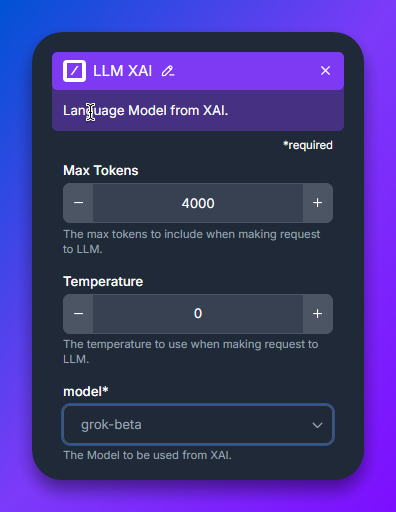
Anslut en LLM-komponent till AI-agenten. Det är här du väljer vilken AI-modell som driver boten. FlowHunt har en separat LLM-komponent för varje leverantör — LLM OpenAI, LLM Anthropic, LLM Google, LLM Meta, LLM Mistral, LLM xAI — och inuti varje väljer du den specifika modellvarianten.
Detta är det enda steget som skiljer sig per modell. Hoppa till avsnittet Välj rätt AI-modell nedan för en jämförelse och anteckningar per familj.
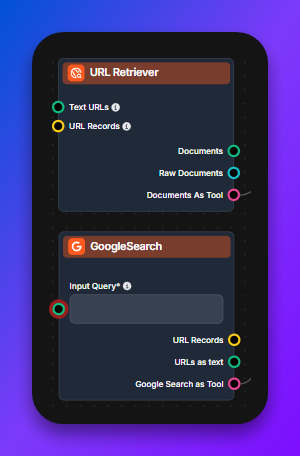
AI-agenten blir dramatiskt mer användbar när den kan använda verktyg. Vanliga är:
Verktyg är modell-agnostiska. Vilken LLM du än väljer i steg 4 kan använda vilket verktyg du än kopplar in.
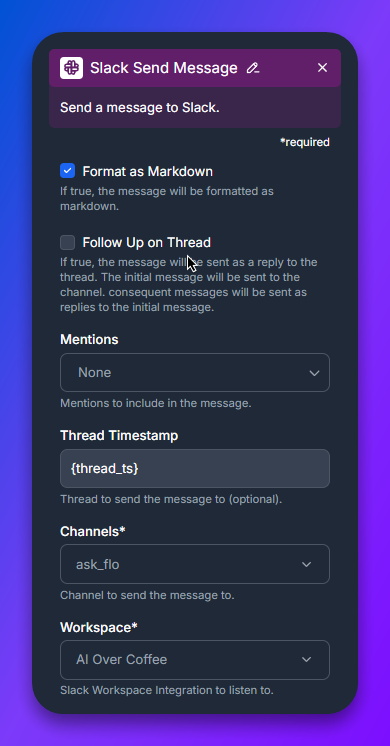
Avsluta flödet med en Slack Send Message-komponent, konfigurerad för samma kanal och arbetsyta som steg 2. Spara flödet, öppna Slack och @-omnämn boten i din testkanal. Boten ska svara med modellen du valde i steg 4.
Det är hela installationen. Att byta modell senare är en ett-klicks-ändring i steg 4 — inga kodändringar, ingen ombyggnad av flödet.
Alla större LLM-familjer fungerar i FlowHunts Slack-flöde. Skillnaderna handlar om kostnad, latens, kontextfönster, resonemangsdjup och kvaliteten på tool-calling. Använd tabellen för att göra en kortlista, läs sedan det familjespecifika avsnittet för installationsanteckningar.
| Modellfamilj | Bäst för | Latens | Kostnad | Anteckningar |
|---|---|---|---|---|
| Claude (Anthropic) | Långkontextanalys, noggrant resonemang, kodgranskning | Medium | Medium–Hög | Stark på att följa nyanserade instruktioner; utmärkt för intern Q&A över dokument |
| GPT / o-serien (OpenAI) | Allmänt syfte, brett verktygsekosystem, multimodal | Låg–Medium | Låg (mini) – Hög (o-serie) | GPT-4o Mini är standardvalet; o1 / o3 för svårt resonemang |
| Gemini (Google) | Massiva kontextfönster, snabb multimodal, sökgrundad | Låg | Låg–Medium | 1.5 Pro hanterar 1M+ tokens; bra för helhets-dokument Slack-Q&A |
| Grok (xAI) | Realtid / nyhetsmedvetna frågor, X (Twitter)-data, ledig ton | Låg | Medium | Bäst när boten behöver medvetenhet om aktuella händelser |
| Llama (Meta) | Självhostade / privata driftsättningar, kostnadskänsliga arbetslaster | Beror på host | Låg (självhostad) | Öppna vikter — använd när dataresidens spelar roll |
| Mistral | Open-weight, balanserad kostnad/kvalitet, EU-vänlig hosting | Låg | Låg–Medium | Mistral Large konkurrerar med GPT-4o till lägre kostnad |
Välj en att börja med. Att byta modell i FlowHunt är en ett-klicks-ändring i LLM-komponenten, så att övertänka det initiala valet lönar sig inte — leverera med ett vettigt standardval, mät kvaliteten på riktig Slack-trafik, iterera.
Få de senaste tipsen, trenderna och erbjudandena gratis.
Varje avsnitt nedan är fristående. Välj avsnittet för den modellfamilj du ansluter och följ dess anteckningar.
Claude är Anthropics familj av LLM:er, väl lämpade för Slackbots som hanterar nyanserad intern Q&A, dokumentsammanfattning, kodgranskning och noggrant följande av instruktioner. För att ansluta Claude till Slack, släpp LLM Anthropic-komponenten i steg 4 och välj varianten:
För interna kunskapsslackbots över Notion eller Confluence är Claude 3.5 Sonnet plus en Document Retriever den mest pålitliga utgångspunkten.
OpenAI:s GPT- och o-serie-modeller är det bredaste valet för Slack — stark allmän prestanda, den mest mogna tool-callingen och multimodal input (vision, ljud). Släpp LLM OpenAI-komponenten i steg 4 och välj varianten:
För de flesta team: börja med GPT-4o Mini. Uppgradera till GPT-4o eller o1 endast på flöden där användarna klagar på svarens kvalitet.
Google Gemini är det starkaste valet när kontextfönstret spelar roll — Gemini 1.5 Pro hanterar över 1M tokens, tillräckligt för att släppa hela kodbaser eller dokumentmängder i en enda Slack-fråga. Släpp LLM Google-komponenten i steg 4 och välj varianten:
Om din Slackbot behöver resonera över hela din kunskapsbas i en enda passering (utan retrieval-steg) är Gemini Pros kontextfönster det renaste svaret.
xAI Grok är inbyggd i FlowHunts Slack-flöde på samma sätt som de andra modellerna — släpp LLM xAI-komponenten (eller använd LLM OpenAI-komponenten som pekar på Grok-endpointen, beroende på din FlowHunt-version) och välj Grok-varianten. Groks utmärkande egenskap är realtidsmedvetenhet — den har tillgång till live information, inklusive X (Twitter)-data, vilket gör den till det bästa valet när Slackboten behöver kontext om aktuella händelser: nyheter, marknadsdata, breaking news. Para ihop den med Google Search Tool för ännu bredare webbtillgång.
Metas Llama-familj är open-weight-alternativet — använd det när dataresidens, självhosting eller kostnad per token utesluter hostade API:er. Släpp LLM Meta-komponenten i steg 4 och välj varianten:
Llama är det rätta svaret när ditt säkerhets- eller compliance-team kräver att modellen körs på infrastruktur du kontrollerar, eller när hög meddelandevolym gör hostade API-kostnader oöverkomliga.
Mistral är den europeiska open-weight-utmanaren — starka modeller, EU-vänlig hosting och bra pris-prestanda. Släpp LLM Mistral-komponenten i steg 4 och välj varianten:
Välj Mistral när EU-dataresidens spelar roll, eller när du vill ha open-weight-flexibilitet med kvalitet närmare frontier än Llama 3.x i vissa benchmarks.
Tre flödesmönster täcker de flesta Slack-driftsättningar. Bygg vilket som helst av dem ovanpå installationen ovan genom att justera AI-agentens verktyg och prompt:
Dessa mönster läggs rent ovanpå varandra: ett enda Slack-flöde kan kombinera kunskapsbas-retrieval, live webbsökning och interna API-anrop, där LLM:en väljer rätt verktyg per fråga.
Boten svarar inte på meddelanden. Kontrollera att “Only Trigger on Mention” matchar hur du testar — om det är aktiverat måste du @-omnämna boten. Bekräfta att kanalen i Slack Message Received matchar kanalen du postar i.
Boten svarar men svaret är dåligt. Iterera på AI-agentens backstory och goal först — de har större effekt än att byta modell. Om kvaliteten fortfarande är dålig efter prompt-iteration, uppgradera till en starkare modell i LLM-komponenten (Mini → standard → toppklass).
Behörighetsfel efter Slack-auth. Återanslut Slack-integrationen i FlowHunts Integrations-flik och bevilja behörigheter på nytt. Slack ogiltigförklarar ibland tokens efter ändringar av arbetsytans ägare.
Långa svar trunkeras i Slack. Slack har en gräns för tecken per meddelande. Lägg till ett efterbearbetningssteg i flödet för att dela upp långa svar, eller instruera AI-agenten i dess goal att hålla svaren under 3 000 tecken vid postning till Slack.
Hela installationen — att ansluta Slack, bygga flödet, välja en modell — är ett kvällsprojekt i FlowHunt. Flödet du bygger idag fungerar med vilken framtida modell som helst: när GPT-6 eller Claude 5 släpps byter du LLM-komponenten och resten av flödet fortsätter köra.
Börja med FlowHunts gratisnivå , anslut Slack och lansera en fungerande AI-Slackbot före lunch.
Arshia är en AI-arbetsflödesingenjör på FlowHunt. Med en bakgrund inom datavetenskap och en passion för AI, specialiserar han sig på att skapa effektiva arbetsflöden som integrerar AI-verktyg i vardagliga uppgifter, vilket förbättrar produktivitet och kreativitet.

FlowHunts no-code flödesbyggare ansluter Slack till alla stora LLM:er — Claude, GPT, Gemini, Grok, Llama, Mistral — genom ett enhetligt flöde. Ingen kod, ingen infrastruktur att hantera.
FlowHunts Slack-integration möjliggör sömlöst AI-samarbete direkt i ditt Slack-arbetsutrymme. Ta med valfri Flow till Slack, automatisera arbetsflöden, få AI-hj...

Integrera FlowHunt med Slack för att automatisera meddelanden, trigga arbetsflöden och hålla ditt team uppdaterat med AI-drivna flöden.

Ny på FlowHunt? Börja här. Lär dig grunderna för att bygga AI-arbetsflöden, distribuera chatbots och ansluta kunskapskällor — allt utan att skriva kod.
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.